Program Development Process and Tool
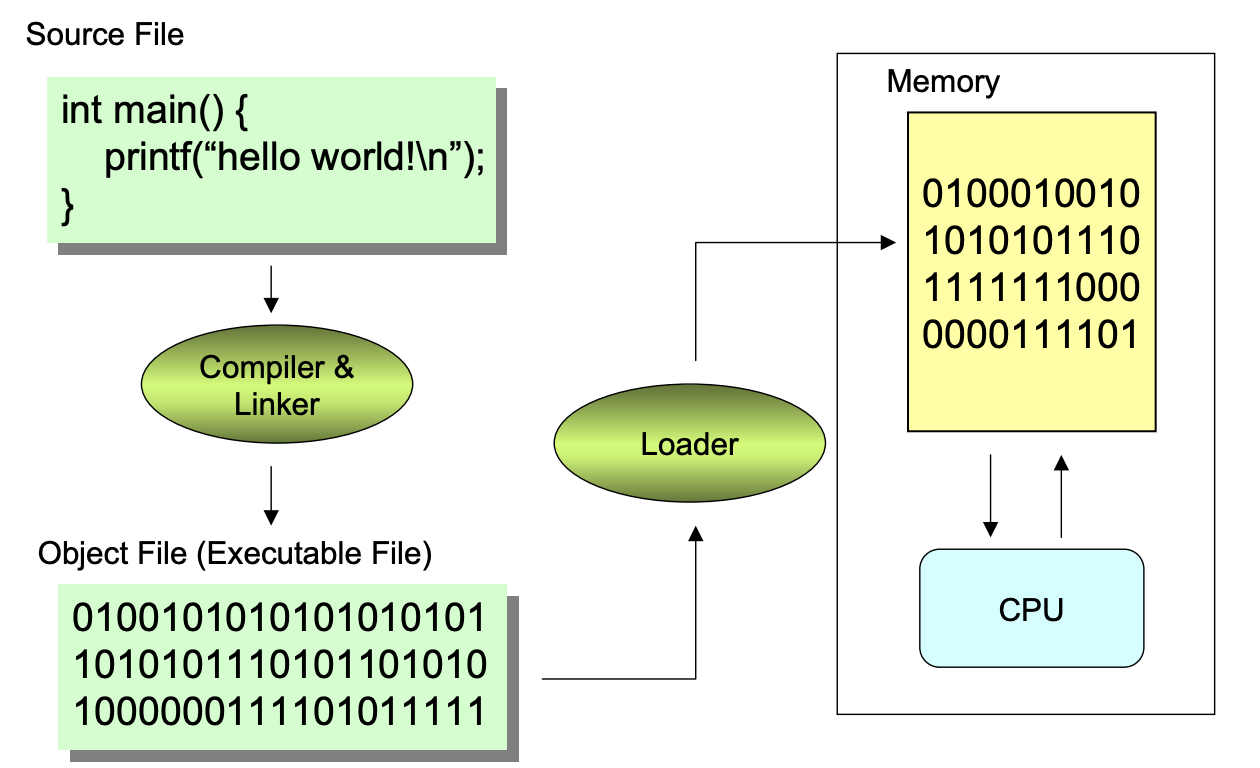
- Source file : 사람이 읽을 수 있는 형태로 적혀져 있는 파일
- Object file :
- 수행 명령, data, 그리고 이런 명령과 data가 메모리 어디에 저장 되어있는지에 대한 주소 정보가 있음
- Symbol Table도 있음
- Symbol Table : Program에서 사용하는 Symbol들에 대한 정보를 저장하는 자료구조
- Relocation Table도 있음
- Relocation information : Linker가 Program linking을 하기 위해서 사용하는 정보
- Relocation Table : Relocation information를 저장한 테이블
- Compiler : 각 Source file를 Object file로 변환시키는 역할
- Linker : 여러 개의 Object file를 묶어서 하나의 Executable file로 만들어 주는 역할
- Loader :
- OS의 한 부분
- UNIX의
fork()와exec()를 진행하는 역할 - Main memory에 Executable file에 있는 내용을 다 layout하고 Context를 빌드하고 수행시킬 수 있도록 하는 것
Linking Process
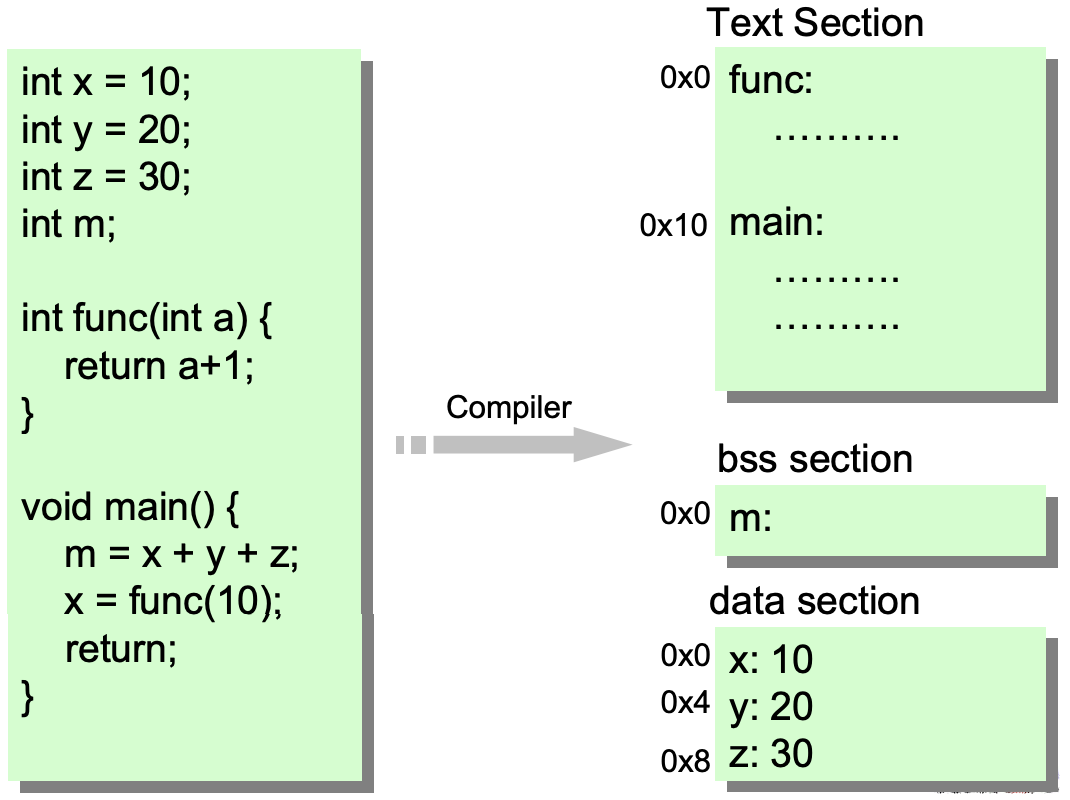
- Section :
- Object file을 구성하는 단위들
- 명령들이 모여서 하나의 Section를 구성, Data들도 별도로 Section를 구성, 등등..
- 각 Section들은 나중에 Memory에 저장될 때 독자적인 영역을 갖고 그 영역을 Segment라 부름
- 각 Section안에는 여러 Symbol들 (ex. 함수 이름, 변수 이름 ..)은 Section内에서의 자기의 위치 (Offset)을 주소로 갖는다
- Object file의 Section 들 :
- Text : Code section, 명령들이 들어가 있음
- Data : 초기화된 Global 변수들이 저장되어 있음
- BSS (Block Started by Symbol) : 초기화 되지 않은 Global 변수들이 저장되어 있음
- Others : Symbol Table, Relocation Table ..
❓왜 BSS와 Data를 구분했을까? :
💁🏻 초기화가 되지 않는 변수는 프로그램이 실행될 때 영역만 잡아주면 되고 그 값을 프로그램에 저장하고 있을 필요는 없으나 초기화가 되는 변수는 그 값도 프로그램에 저장하고 있어야 하기때문에 두 가지를 구분해서 영역을 잡는것이다. 따라서 이러한 bss영역 변수들은 많아져도 프로그램의 실행코드 사이즈를 늘리지 않는다.
-
Object file로 부터 Section들 생성
-
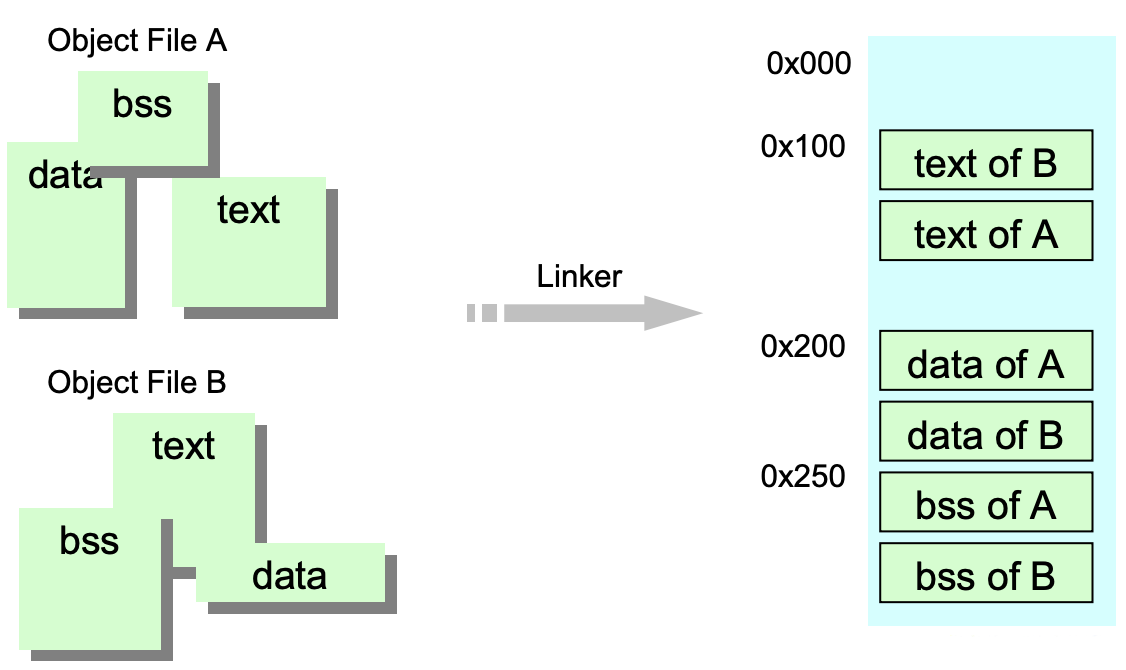
Linker의 역할
-
여러 Object file에 있는 동일한 Type의 section들을 다 merge를 함
-
Linker script : 각 section들이 몇 번지에 저장되야되는지에 대한 정보가 있음
-
GNU Compiler에는 default Linker script가 있어서 우린 그걸 계속 재활용하면서 사용해오고 있음
-
근데 Linker script를 왜 사용해야됨 ?
Embedded System를 개발할 때, Custom hardware의 memory layout에 따라서 Linker script사용해 직접 조정할 수 있음
-
-
-
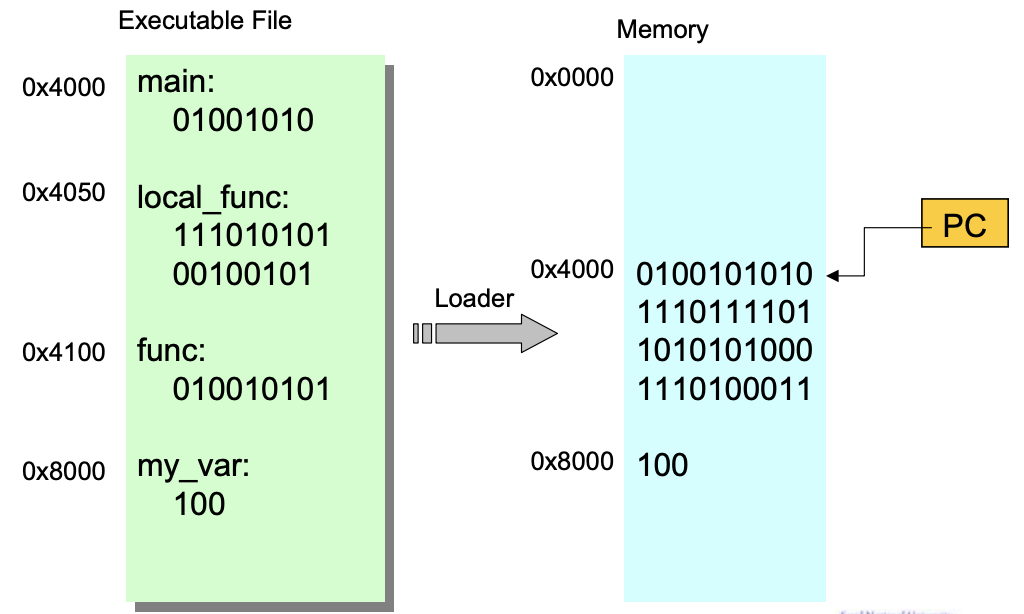
Loader의 역할
- Executable file을 깔아주는 방법
- Executable file에 이미 적혀있는데(code section은 몇번지에 저장하고 등..)로 읽어드린다
- 마지막에 Program Counter(PC)를 Executable file의 entry point로 설정하면 됨
- Executable file을 깔아주는 방법
Problems in Compiling and Linking
- Cross reference : Object file이 여러 개로 쪼개져 있기 때문에 compiler가 한 Object file을 만져있는 동안 다른 Object file에서 정의된 Symbol의 주소를 알길이 없음
Symbol Table
-
Symbol들이 나오면 그것의 주소와 기타 정보들을 一目了然하게 찾을 수 있도록 한 곳에 모아둔 역할
-
Symbol Table은 Symbol의 이름을 가지고 검색을 함
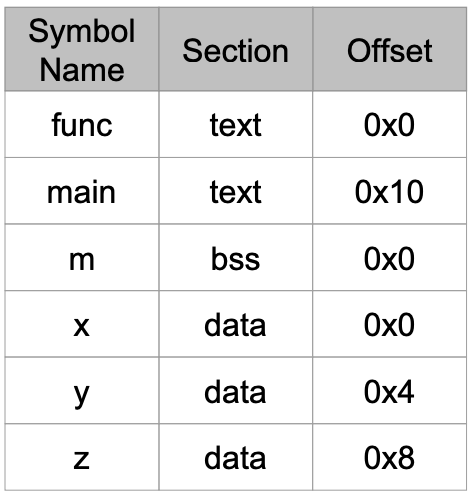
-
Compiler가 어떤 Symbol를 읽게되면 그 Symbol에 해당하는 Entry를 Symbol Table에 넣고 그것의 주소를 알 수 있으면 section 주소와 offset으로 채운다
Relocation Table
- 같은 section에 있는 Symbol들은 PC Relative 주소로 변경
-
call local_func
 call PC+0x1B
call PC+0x1B - PC Relative Addressing : 현재 PC값에다 Distance를 넣어서 jump
- Internal Symbol들에 대해 PC Relative Addressing를 하는 이유 :
- 전체 section의 위치에 관계없이 PC로부터의 상대적인 주소는 바뀌지 않기 때문
-
call local_func
- 다른 section에 있는 symbol을 Cross reference라고 한다
- Cross reference를 만나게되면 0을 써넣는다. 그리고 “이 0이 Cross reference를 모르기 때문에 check한 0이다” 라는 거를 Relocation Table에다 기재를 함
- Relocation Table에는 Cross reference가 나타난 위치를 기재함
- 다음 path에 Cross reference를 해결함
Example
1. Source file

-
extern: 외부 파일에 있는 변수를 사용하기 위한 keyword
2. Compiling Source file into Object file
[main.c ➡️ main.o]

-
call PC + 0x4C:local_func는 같은 section에 있는 symbol이기 때문에 PC Relative 주소로 변경 -
0x0: 다른 section에 있는 symbol(Cross reference)들은0x0로 표기하고 Relocation Table에다0x0를 표기한 위치를 기재를 함 - main.c는 lib.c (외부 파일)에 있는 변수를 사용하기 때문에 Relocation table에 lib.c의 변수 (Symbol)에 대한 정보만 포함되고 있다
[lib.c ➡️ lib.o]
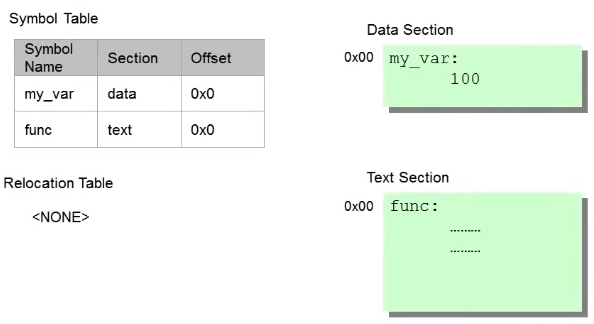
- lib.c에는 외부 파일 변수를 전혀 사용하지 않기 때문에 Relocation table 비어있다
3. Linking main.o and lib.o
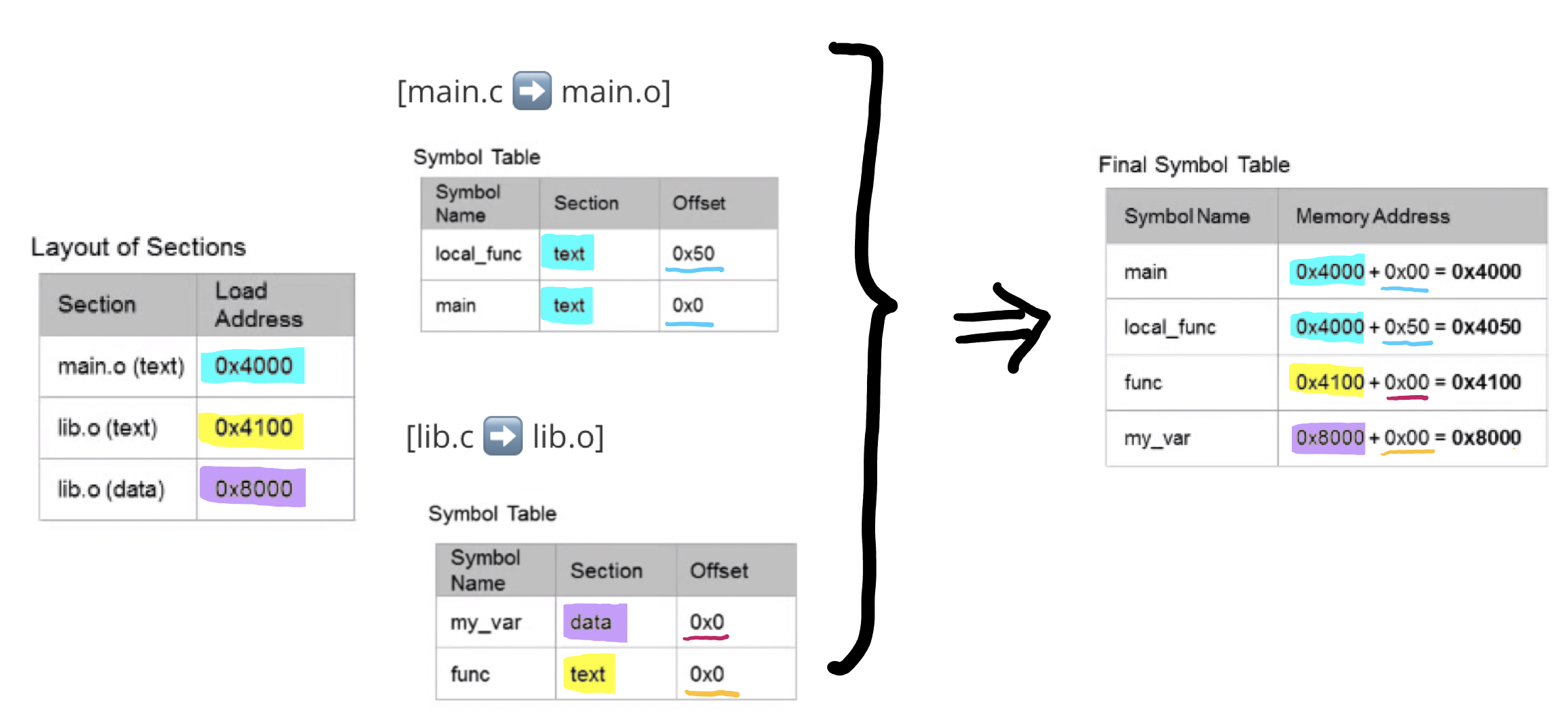
3.1 모든 Symbol들의 주소를 계산하여 Final Symbol Table을 만든다
- Linker가 section들을 다 Layout을 하게됨
- 실제로 Physically Layout하는 건 아니고 Section들을 그냥 산수에 의해서 위치를 정해줌
3.2 Final Symbol Table을 기반하여 Relocation table에 Check한 명령들( 0x0 로 표기된 곳)을 수정한다
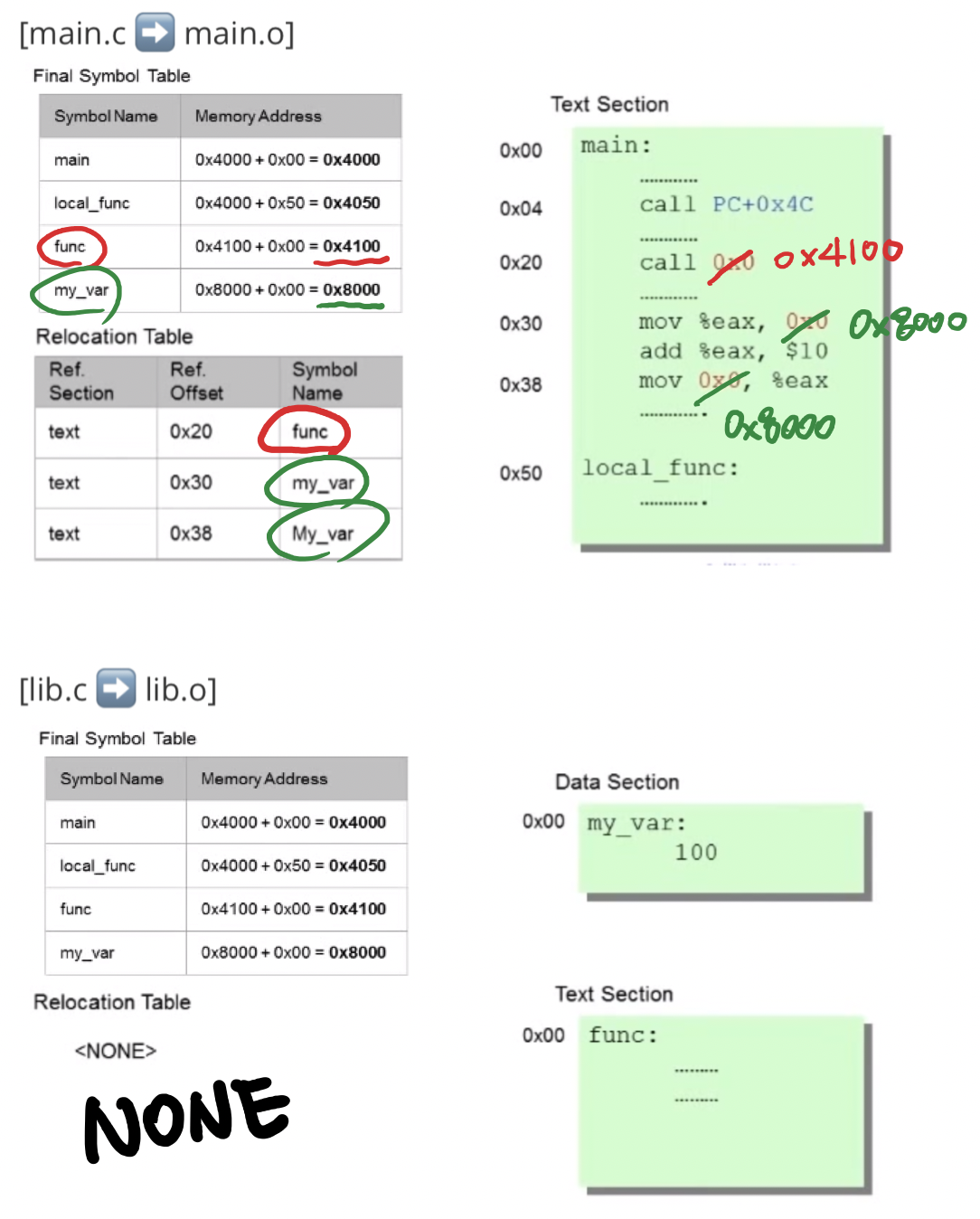
3.3 Execution file을 생성한다
-
흩어져 있는 Object file들을 읽어서 실제로 물리적으로 동일한 type의 section들을 다 묶어서 하나의 executable file로 만듬
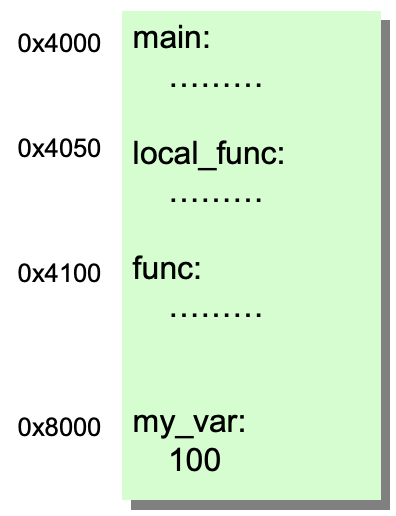
4. Loading
Conclusion
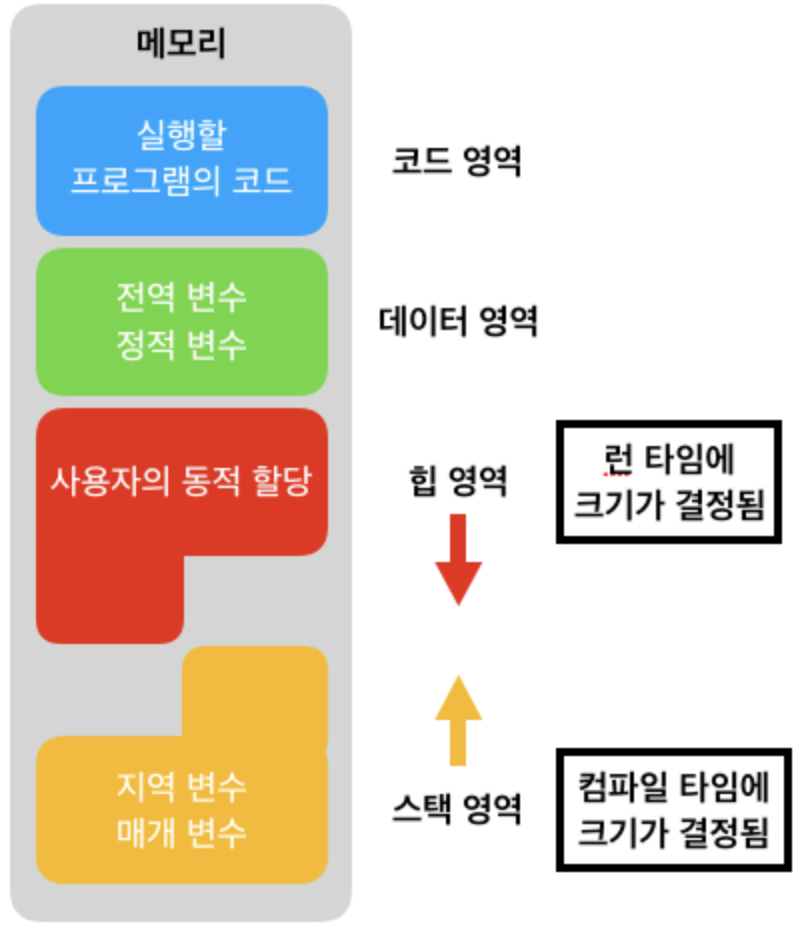
- Code segment와 Data segment에 정보가 들어오기 까지의 순서 :
- 각 Object file이 흩어져 있는 것을 Linker가 묶어서 executable file에 layout을 함
- executable file에는 section이란 이름으로 구성되어 있는데 그런걸 Loading할 때 Code segment와 Data segment에 넣어줌
- BSS는 Data segment로 Merge됨
- BSS로 잡혀진 영역은 0으로 zero fill을 한다
- Stack segment, Heap segment는 Loader가 loading하는 시점에 만들어줌
- Static storage allocation : Code segment와 Data segment는 프로그램이 loading될 때 1번 allocation됨 그리고 프로그램이 terminate될 때 Deallocate됨
- Dynamic storage allocation : Stack segment와 Heap segment은 필요한 만큼 할당 받음
Why Dynamic Allocation?
Background
- Static X :
- Pre-runtime에 이루워지는 여러 가지 행위들
- Static Analysis와 Static Synthesis로 대표적인 것은 Compiler
- Static Allocation : 프로그램이 수행되기 전에 미리 메모리를 할당하는 것
- 대표적으로 Code segment와 Data segment
- 변수의 Lifecycle이 프로그램의 시작과 종료와 일치
- Dynamic X :
- Run-time에 이루워지는 여러 가지 행위들
- Activation Records (Stack Frames 또는 Activation Frames) :Procedure가 수행되기 위해 필요한 정보들을 저장하고 관리하기 위해 Stack에 저장되는 데이터 구조
- Stack에 새로운 함수가 호출이 되면 그 함수가 수행하기 위해서 필요한 공간들(parameter 전송, local 변수, return값을 저장하기 위한 공간)이 Stack에 잡히게 됨
- Activation Records의 생명 : 함수 호출 후 수행이 끝날때 까지
- Activation Records가 생성되는 건 Stack에 push, 사라지는 건 Stack에 pop과 일치
- PCB(Process Control Block) :
- Process 관리를 위해 OS가 유지해야 하는 정보들을 저장하는 data structure
- 왜 Dynamic Allocation를 하지?
- 예측불가능한 상황에서 필요한 만큼만 메모리를 할당해줘야 될 필요가 있기 때문에
- 수행중에 예측불가능성 : 함수의 Calling sequence, PCB를 위한 공간
- 예측불가능한 상황에서 필요한 만큼만 메모리를 할당해줘야 될 필요가 있기 때문에
- Dynamic Storage Allocation를 하는 방법 2가지 :
- Stack : 새로운 Record를 넣고 빼는건 top에서만 가능해서 굉장히 제약적임
- Heap : Stack보다는 General하고 Flexible함
- Dynamic Storage Allocation의 기본 Operation :
- Allocate(New) : 메모리 줘
- Free(Deallocate) : 메모리 반납
Heap
-
Heap : 초기에는 연속적인 memory block이고
malloc(...)과free(...)연산자를 제공한다.malloc(...)과free(...)를 반복하게 되면 Fragmentation문제가 발생할 수 있다 -
Heap을 쓰기 위한 방법 :
- C에서
malloc(...): 필요로하는 Byte수를 parameter로 주면, 그만큼 연속적인 메모리 chunck를 받아올 수 있다 - C++에서
new
- C에서
-
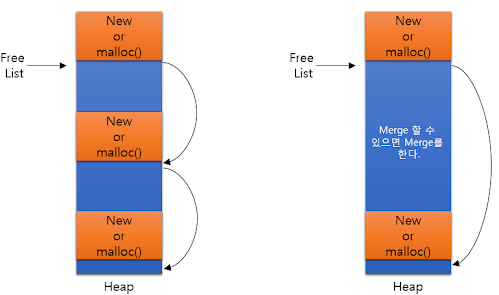
Free List : Heap의 사용 가능한 공간들을 연결한 list
-
free(...)의 역할 : Free List로 반환하는 공간이 기존 가용한 공간과 병합 가능한 경우 하나의 큰 공간으로 병합하고 아닌 경우 새로운 포인터를 추가 -
어떤 Process가
malloc(...)을 했을 때, 어떤 순서로 Free List의 조각을 할당해주면 좋을까?- Best-fit : Free List를 쫓아가면서 여분이 가장 적은 것을 찾아서 allocate해주는 것
- 시간의 지남에 따라 First-fit, Worst-fit에 비해 작은 크기의 hole들이 생성되기 때문에 Fragmentation문제가 더 심각해질 수 있다
- First-fit : 가장 첫번째꺼를 allocate해주는 것
- Best-fit보다는 크겠지만 average size의 조각들이 생길꺼임
- 즉, Memory Fragmentation문제는 이렇한 여러 Policy가지고는 해결 되기 어려운 일이다
- Best-fit : Free List를 쫓아가면서 여분이 가장 적은 것을 찾아서 allocate해주는 것
-
Free List Implementation :
-
Bit map
-
Memory Pool :
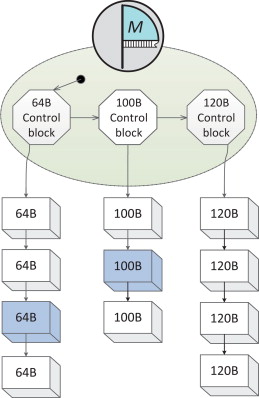
- 기본적으로 Unit size로 memory request 하게함 그대신 다양한 size를 허용함
- 여러 size의 Memory node들을 동일한 size별로 묶어서 할당하는 것
- 문제점 : 특정 size의 Memory node만 굉장히 요구를 하게 되면 불균형의 문제가 생김
-
-
-
Fragmentation : 잦은
malloc(...)과free(...)사용을 통해 작은 조각들이 많아지는 현상- Fragmentation이 발생되는 원인 : 결국은 free block과 memory request size가 딱 맞지않음
-
Fragmentation를 최소화 시키는 기법들 :
-
Buddy Allocator :
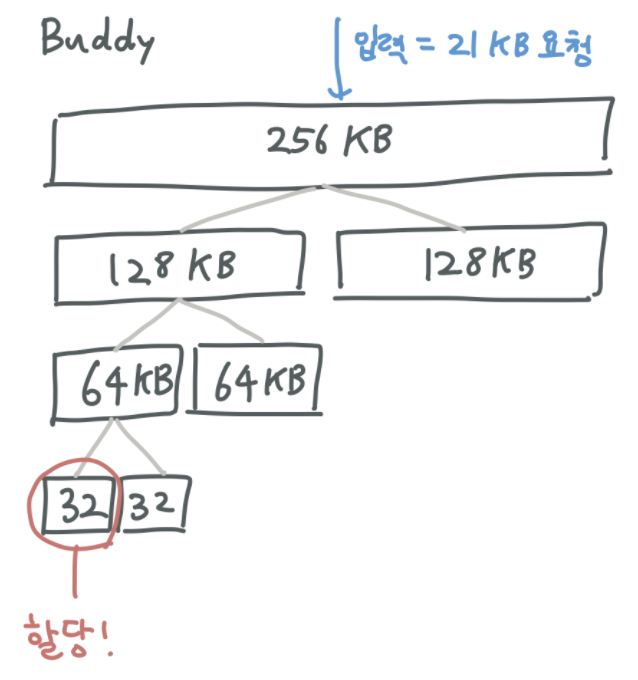
-
요청된 메모리 크기를 수용할 수 있는 최소 크기로 메모리를 쪼개어 할당하며 그러한 메모리 조각을 buddy 라고 부름
-
장점 :
인접한 buddy들이 可用상태인 경우 이들을 병합함으로써 쉽게 큰 크기의 可用한 메모리 공간을 확보할 수 있다
-
단점 :
buddy로 인해 internal fragmentation 이 생길 수 있다
buddy 생성 시 오버헤드가 크다는 점 (메모리를 쪼개야 하니까)
-
-
Slab Allocator : Linux에서 사용됨
-
Paging
-
Segmentation
-
Single Segment per Process : 한 User process의 memory section들(Text, Data, Heap Stack)이 하나의 Memory segment를 할당받음
- 하지만 Process의 여러 Memory section들의 특성이 다르다 : Data section은 Read/Write고 Code section은 Read only인데 다른 process들과 Sharing해야됨
- Single Segment per Process의 문제점 :
- 두 user process가 동일한 코드(Text section)을 공유하기 힘들다
- 각 Memory section들에게 다른 Read/Write 권한을 설정하기 힘들다
-
Memory segmentation :
- 과거 Single Segment per Process의 문제점를 해결하기 위해서 속성이 다른 section들에게 다른 Memory segment를 할당을 해주자는 방법
- 문제점1 : 각 segment마다 별도의 base register와 bound register를 별도로 유지해야되서 address translation logic이 복잡해짐
- address translation : CPU에서 만든 Logical Address를 물리 Memory가 이해할 수 있는 Physical 주소로 변환하는 작업
- base register : Physical Memory에서 이 Segment가 어디서 부터 시작하는 나타내는 Base address가 포함됨
- bound(Limit) register : 이 Segment의 크기가 얼마인가를 나타내는 값이 포함됨
- MMU의 기능 :
- Table lookup을 하고 Base register값을 더한 다음에 compare하는 operation을 한다
- Table lookup을 하기 위해서 Main memory를 access할 수 있는 기능도 추가되야됨
-
MMU의 전반적인 동작 과정 :
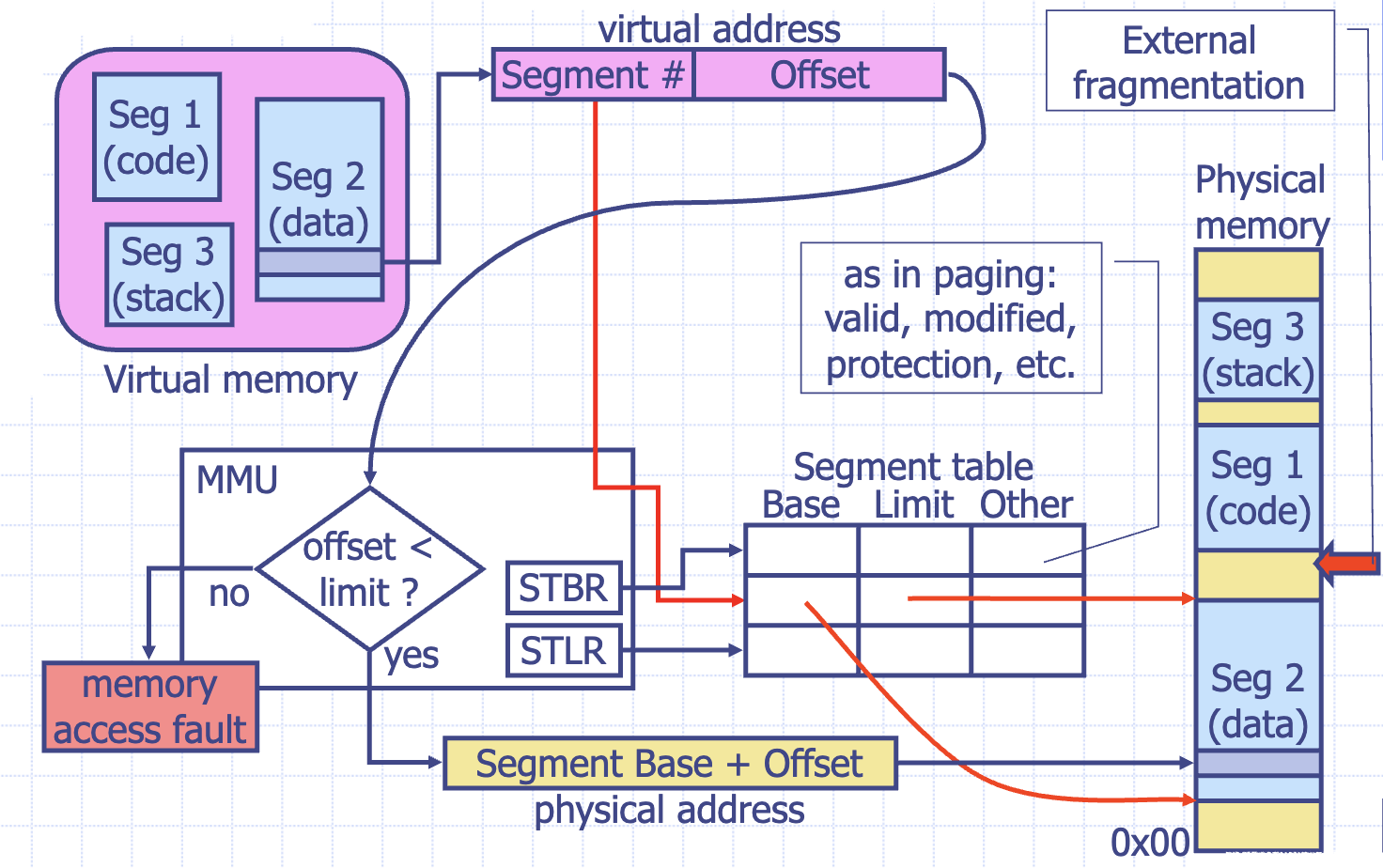
-
우선 어떤 Segment에서 나온 주소가 있으면 그 Segment가 무엇인지를 알아야된다
(ex. CPU에서 Instruction Fetch가 날라왔으면 이 Address는 text segment다)
(ex. CPU에서 Global variable를 access하는 Address가 날라왔으면 이거는 Data segment다)
알 수 있는 방법 : 논리주소의 상위 #bit는 그 Segment가 무엇인지 판단하는 ID로 사용되고 나머지 bit는
세그먼트의 offset(내부 주소)으로 사용 된다.
-
Segment Table에 가서 SegmentID에 따라 base address와 Limit를 가져와야됨
- Segment Table의 Base Addresss는 Physical Address이다
- Segment Table Base Register(STBR) : Segment Table의 시작 주소를 가르키는 MMU의 Register
- Segment Table Limit Register(STLR) : Segment Table의 한계를 가르키는 MMU의 Register
- 모든 Process는 자기만의 Segment Table을 가지고 있어야됨, 그리고 Process가 Context switching을 하면 OS가 MMU의 STBR에다 지금 들어오는 Process의 Segment Table의 시작 주소를 reload를 해줘야됨
-
base address와 offset을 더해서 limit보다 큰지 작은지를 판단
- limit보다 클 경우, Memory access fault 발생
- limit보다 작을 경우, base address + offset가 Physical address로 사용됨
- 문제점2 : Memory를 Access하기 위해서 실제로 2번의 Memory Access가 필요함
- 한번은 MMU가 Segment Table Entry를 가져오기 위해서 Memory를 Access
- 한번은 Address Translation한 다음 Physical Address가 되면 그 때 또 Memory를 Access
- 문제점3 : Segment가 Main memory에 많이 존재해서 Fragmentation문제가 발생
- 문제점4 : 주어진 Stack Segment보다 더 자라서 자기 공간를 넘어가게 되는 경우
- 해결방안 : 메모리를 더 필요로하는 이 Segment를 Disk로 보내고 나중에 충분한 공간이 생기면 불러드린다
- 문제점5 : 새로운 Process를 Main memory로 불러드리고 싶은데 그때 필요한 memory공간이 충분하지 않을 경우
- 해결방안 : Swapping을 통해 해결한다
- Segmentation의 장단점 :
- 장점 :
- 과거 Single Single Segment per Process의 문제점를 해결
- code section의 Sharing 을 원할하게 해줄 수 있다
- 단점 : External Fragmentation 문제점은 피해갈 수 없다
- 장점 :
Paging
-
Fragmentation 문제점을 해결하기 위해 Process가 사용하는 Memory의 Allocation을 Page라고 하는 Unit size로 하는 것
-
Page : Logical Address Space를 일정한 크기로 나눈 Memory Block
- 요즘은 Bus Bandwith와 Memory의 크기가 커져서 Page 크기가 커지고 있음
- 과거 Page size는 한번에 Swapping하는 size에 따라 결정했다
-
Frame : Physical Address Space를 일정한 크기로 나눈 Memory Block. Page크기와 동일
-
MMU가 Page Table을 이용해서 address translation을 하게된다
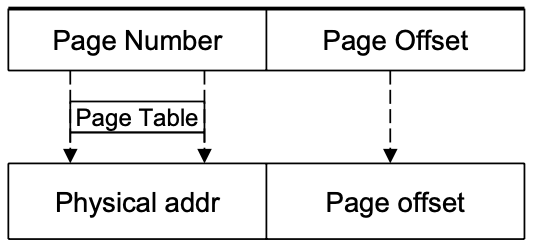
-
Page Table :
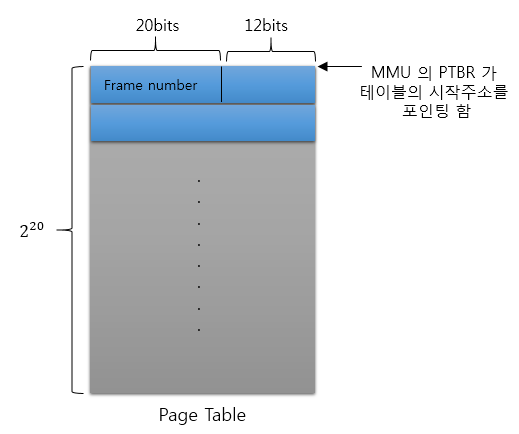
- Page Table의 Entry (즉, Page Table의 각 Record)는 word size로 되어있고 그 중 Frame Number가 있다
- Frame Number는 Physical Address와 다른다. Frame Number는 Frame의 boundary physical Address의 상위 # bit 로써 Frame Number뒤에 Page Offset을 concat할 때 physical Address가 생성이 된다
-
MMU에 Page Table의 시작 주소를 가르키는 Page Table Base Register(PTBR)가 존재해야된다
-
OS는 Context switching이 발생할 때마다 PTBR값을 새로운 Process의 Page Table 시작주소로 loading해줘야됨
-
-
Segmentation과의 차이
- Segmentation에서는 실제 Segment의 크기는 可变적인다 (이걸 표현한 것이 Bound Register)
- Paging에서는 Page의 크기가 일정하다
-
Paging 의 장단점 :
- 장점 :
- External Fragmentation이 없고 Disk Block size와 Page size가 같아서 Swapping도 용이하다
- 단점 :
- Internal Fragmentation : Logical address space에 마지막 page가 page boundary에 딱 맞지않을 경우
- Memory를 Access하기 위해서 실제로 2번의 Memory Access가 필요함 (Page Table 가져오기, 실제데이터 가져오기)
- Page Table 크기가 방대해지는 문제가 생긴다
- 장점 :
Paged Segmentation
-
Paging만 한다는 거는 Fragmentation 문제는 해결 했지만 Process에게 Multiple Segment를 할당해야되는 원래의 목적은 달성하지 못함
-
Paged Segmentation :
- Segmentation과 Paging을 각각의 장점을 한꺼번에 얻기 위해 두 기법을 동시에 사용
- 이를 위해서 먼저 Segmentation을 수행하고 각 segment 별로 Paging을 수행
-
Paged Segmentation을 위해 기존 Segmentation에서 변경되는 부분 :
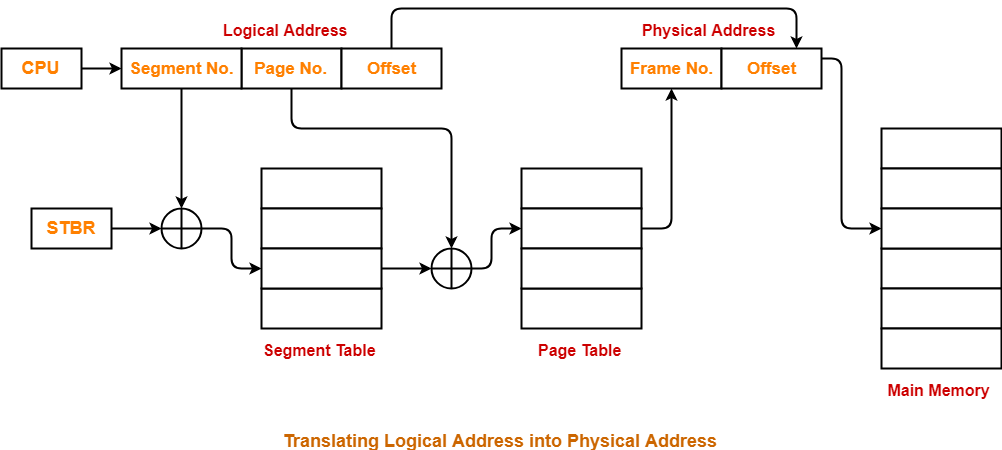
- Segment Table의 기존 Base Address 대신 해당 Segment의 Page Table 위치(주소)를 저장
- Segment Table의 기존 Bound(Limit) 값 대신 해당 Segment의 Page 개수를 저장
-
Address Translation :
- Segment Table과 Page Table을 사용한 주소변환은 MMU에 의해 Hardware적으로 수행된다
- 그러나 Process의 Context switching이나 새로운 Process의 생성등이 일어날 때, OS가 Base/Bound Register 및 Segment/Page Table들을 관리해야 하므로 OS에게 Transparent하지는 않음
Example. IBM 370 Machine : 24bit Address Bus width

-
Page의 크기 : 2^(12) = 4KByte
-
Segment당 최대 몇개의 Page : 2^8 = 256개
-
하나의 Process에게 부여할 수 있는 Segment 개수 : 2^4 = 16개
- Segment Table : 16개 Entry가 있음
-
ex. 0x002070
 addr = 0x003070
addr = 0x003070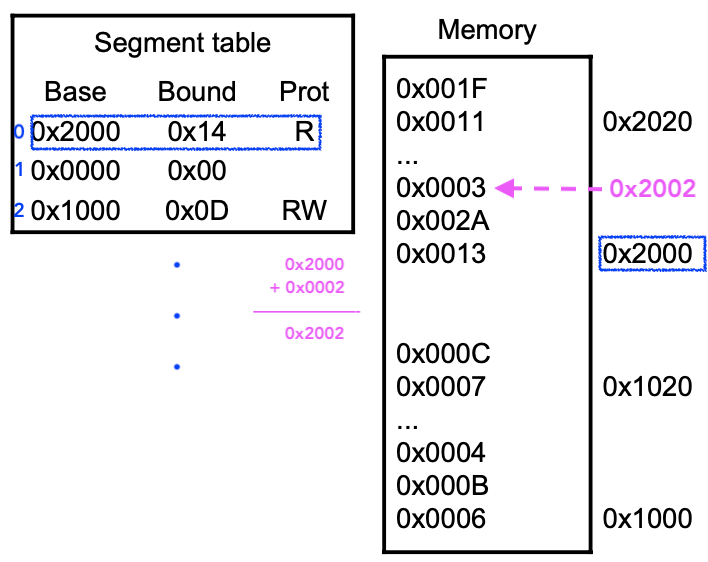
- Paged Segmentation의 장점 :
- Pure paging에 비교했을때, Page Table space를 줄일 수 있음.
- Pure paging만 하게 되면 어느 Page가 사용이 되고 안사용되는지 알기가 어렵다 (즉 Page가 사용 안되는 것들에 대해서 null을 넣는다 해도 그 Page에 대한 정보를 Page Table의 Entry로는 잡아놔야됨 )
- Paged Segmentation에서는 Segment table에 Segment 별로 Page 개수가 몇개인지 count해서 그 양만큼만 Page Table를 만듬
- Pure paging에 비교했을때, Page Table space를 줄일 수 있음.
- Paged Segmentation의 단점 :
- 이제는 CPU에서 Memory를 Access하기 위해서 실제로 3번의 Memory Access가 필요함 (Segment Table가져오기, Page Table 가져오기, 실제데이터 가져오기)
-
근데 Linux는 Pure Paging만을 사용함
- 과거에 Segment단위로 하던 Access Control을 Page Table로 다 내림
- Page 단위로 Control를 해서 Memory Access Control도 가능해짐
- Sharing도 Page 단위로 진행
- 그렇다고 완벽하게 Segmentation을 안하는 건 아니다 : OS가 software적으로 어느 Page가 data segment인지, code segment인지 그 region을 다 관리함
- 즉 Segmentation에 필요한 많은 일을 OS가 보충 대신에 Pure Paging만 한다
❓근데 왜 Paging을 선택했을까? :
OS에서 Machine-Independent한 Code의 비중을 가능한 높여서 OS의 Portability를 높이고 다른 Hardware에서도 동일한 OS를 사용하기 위해서
 Machine-Dependent한 대표적인 부분 : Context switching code, Task creation code, I/O device driver, Memory management Intel processor는 태생적으로 Paged Segmentation을 지원하는 Segmented Architecture로 되어있음 ARM은 Segmented Architecture을 가지고 있지 않음
Machine-Dependent한 대표적인 부분 : Context switching code, Task creation code, I/O device driver, Memory management Intel processor는 태생적으로 Paged Segmentation을 지원하는 Segmented Architecture로 되어있음 ARM은 Segmented Architecture을 가지고 있지 않음 - Page table space 문제 :
- 요즘은 Memory address space 가 64bit 가 되버려서 엄청나게 큰 space가 table로 사용됨
-
Page table는 Physical memory에서 연속적으로 있어야됨
-
Large Page table space 문제의 해결 조건
- Page Table의 크기를 줄임
- Physical memory에서 연속적인 메모리 공간 요구량을 줄임
-
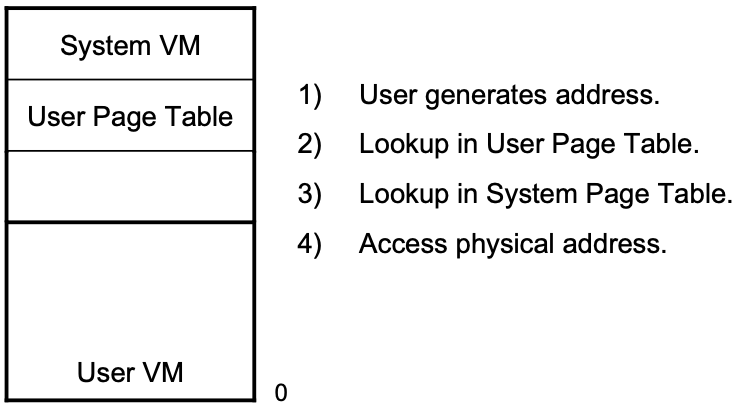
[1980년대] VAX(Virtual Address Extension) Computer Architecture, VMS OS
-
연속적인 Large Page table의 문제를 해결 할려 했음
-
Virtual Address space를 4개의 Segment로 나눔
-
System(OS에게 할당, User Page Table이 있는 곳), P0(User에게 할당), P1(User에게 할당), Unused Segment
-
-
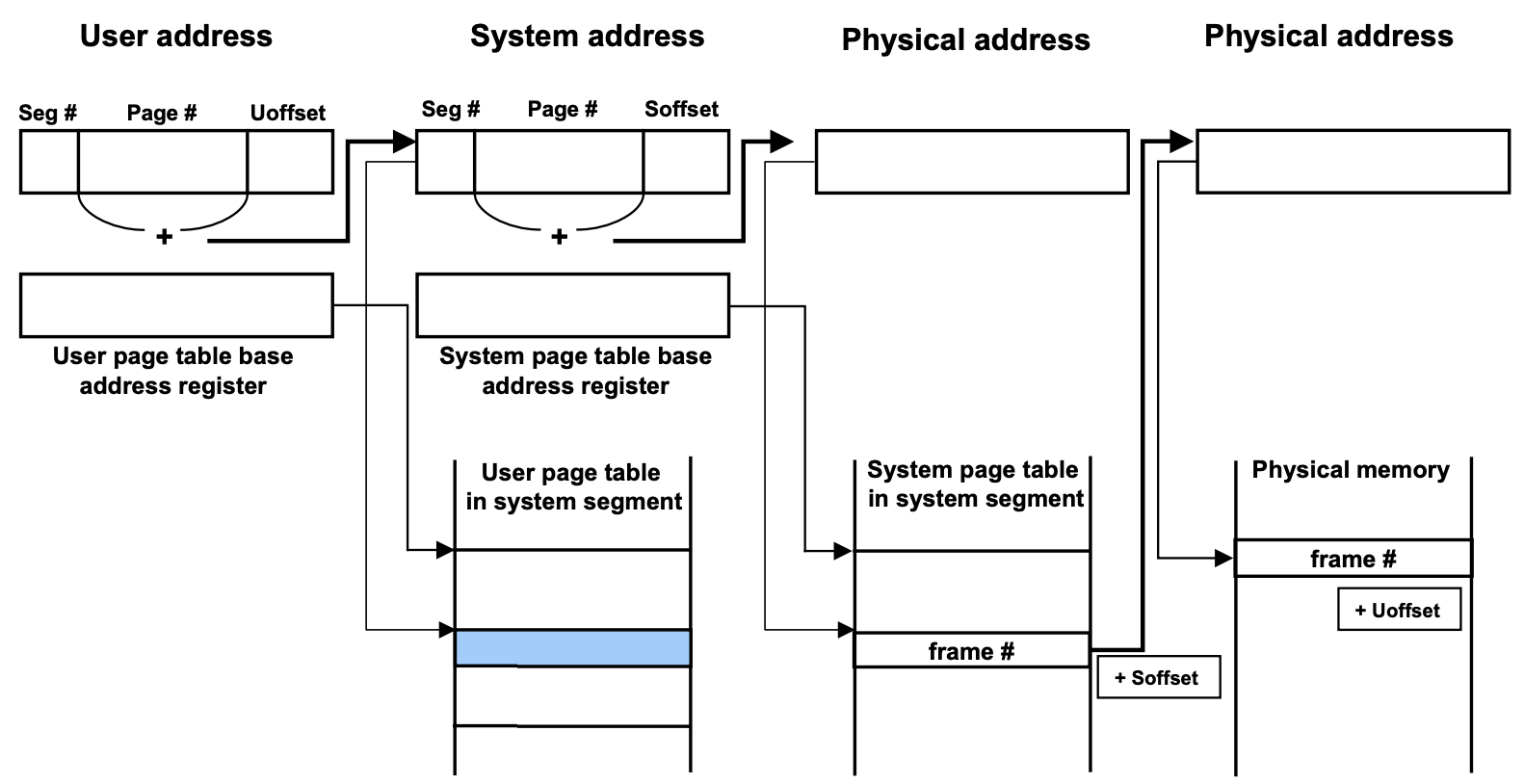
Virtual Address space상에서는 Page table space가 연속적이지만 Physical Address space상에서는 뛰엄뛰엄 Page단위로 나눠져 있을 수 있음 (Physical memory에 있는 Page Table은 OS에 주소를 번역해주는 Page Table 딱 하나만 Physical memory에 연속적하게 있어야되고 나머지는 흩어져 있어도 된다 )
-
Address Translation하는데 Overhead가 많이 들지만 Large Page table의 연속적인 allocation문제는 해소 할 수 있다
-
-
성능저하의 문제
-
Translation Look Aside Buffer (TLB) : Logical Address에서 Physical Address를 얻어올려면 반드시 Page table look up을 해야되는데 그 중에 자주 look up되는 page들의 entry를 갇다논 Cache (Hardware)
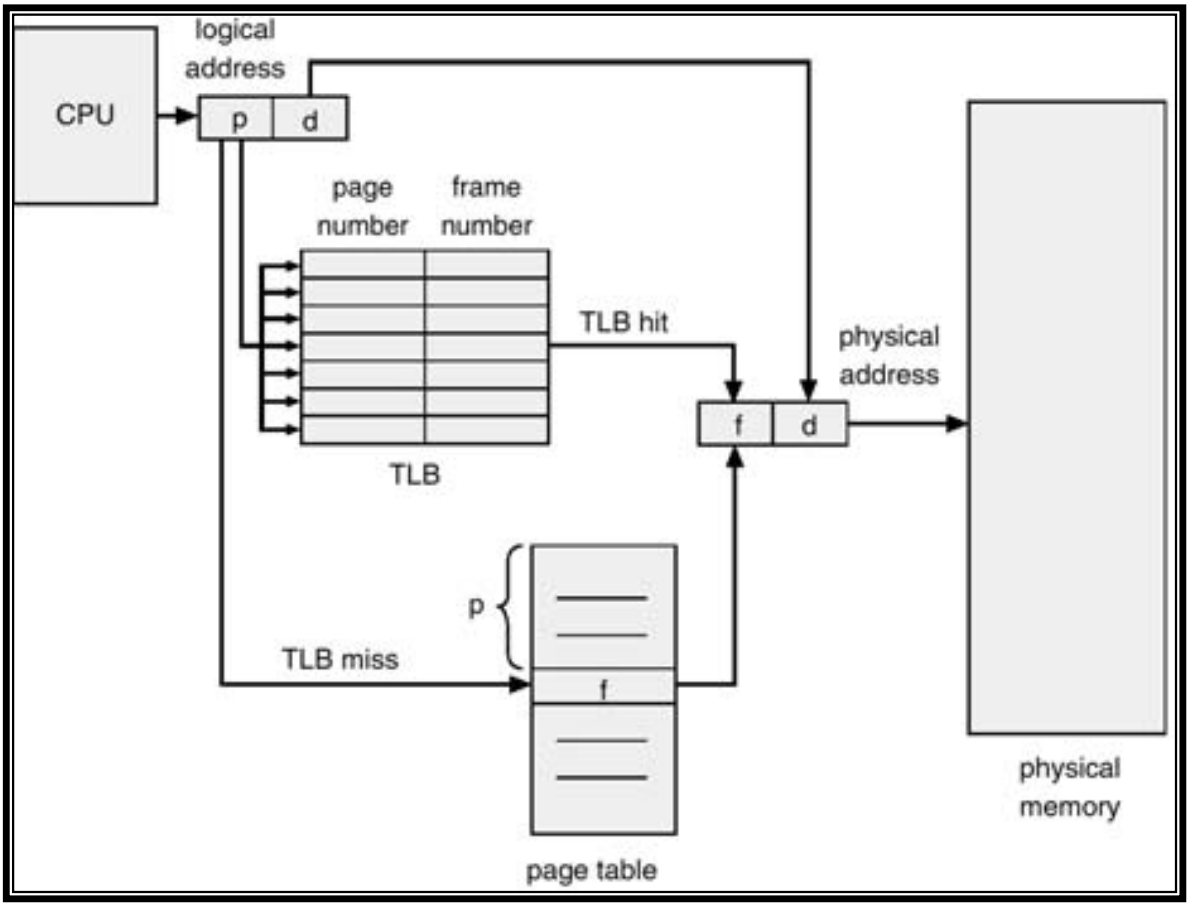
- TLB는 OS에게 Transparent하지는 않음 : Context switching이 발생하여 다음 Process가 들어와 TLB를 접근했을 때, Hit가 생겨서 Physical Frame number를 얻어왔는데 중요한건 이 Frame number는 이전 Process의 것이지 현재 Process의 것이 아니다. 그래서 OS는 Context switching이 발생했을 때 TLB를 flush시켜야됨
- 하지만 MIPS micoprocess의 경우 TLB line에 Process ID(PID)를 추가적으로 사용해서 TLB look up을 할 때 Page number 뿐만 아니라 지금 수행하고 있는 Process의 ID까지 Tag로 사용해서 이 둘의 정보가 TLB line과 일치할 때 valid한 entry라 간주한다 💁🏻 이렇게 되면 OS는 TLB에 대해서 신경 안써도됨
-
Page Size를 키우면 한 Page entry가 cover하는 address space가 커지니깐 TLB의 Hit rate이 높아진다
-
TLB의 Hit rate을 높이기 위해 TLB size를 적당히 크게(64개~128개) 만들어도 된다 :
-
이유 : Locality
[1] Spatial Locality : 한 명령이 수행이 됬으면 그 명령의 위나 아래 명령이 수행될 가능성이 높다 (ex. Loop와 function call 때문에)
[2] Temporal Locality : 한번 수행이 된 명령은 매우 짧은 시간안에 다시 수행이 될꺼다 (ex. Loop 때문에)
-
-
TLB의 구성 :
-
TLB를 어떻게 빨리 검색해서 Data를 넘기느냐?
[1] Sequencially Table search : 不太好
[2] Directed mapped cache : Page Table entry가 있으면 특정 영역에다만 mapping을 시킴
[3] Fully associative cache : cache line에 전부 comparator를 설치해서 Page number가 들어오면 병렬적으로 비교함
-
-
TLB line에 포함된 정보들 :

-
Demand Paging
-
Demand Paging :
- MMU Mechanism을 사용해서 여러 Process가 System의 memory를 효율적으로 공유할 수 있도록 하는 기술
- Page가 요구 될 때 RAM에다가 불러오는 정책
-
Demand Paging이 가능한 이유 :
Program이 Locality를 가지고 있기 때문이다
Background
-
MMU Mechanism의 특징 :
MMU가 들어옴으로써 Physical Memory와는 별도로 Logical Memory라는 것이 생김
- Physical Memory Space : 컴퓨터 시스템 마다 달라서 다양한 모습을 가지고 있음
- Logical Memory Space : 컴퓨터 시스템과 무관함
❓Program이 필요로 하는 모듬 메모리 (Code segment, Data segment, Stack segment)가 Physical Memory에 있어야 하는가?
💁🏻 그렇지 않다. 왜냐하면 Program은 Locality를 가지고 있기 때문이다
💁🏻 근거 : Knuth가 Program을 임의의 순간에 세워봤더니 Program이 10%의 고정된 공간에 항상 있었다
💁🏻 90/10 Rule : 불과 10%의 코드가 Program 총 수행시간의 90%를 차지함
❓현재 Logical Address Space에 있는 Page들 중에서 Physical memory에 들어있지 않은 놈들은 어디에 있어야 될까?
💁🏻 Physical Memory의 Swap area에 있어야됨
-
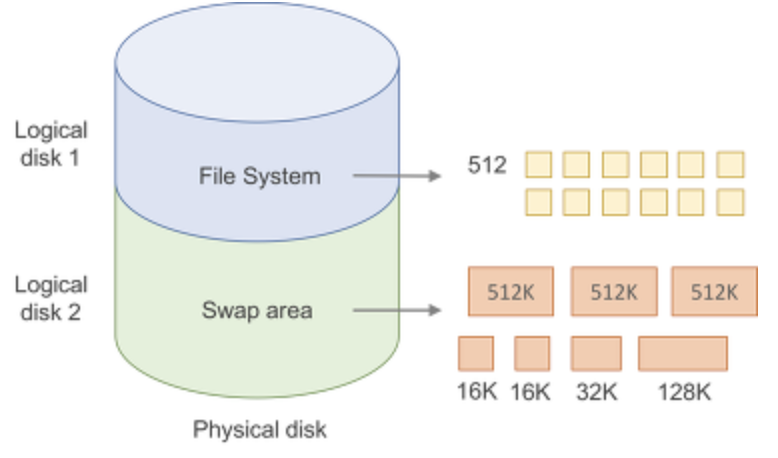
Swap area (Swap Device) :
- Physical Memory에 저장되지 못한 Page들을 저장하는 Disk 공간으로 File에 비해 OS가 직접 빠르게 접근 할 수 있음 (그래도 Swap Device와 Physical memory사이의 transfer operation는 느리기 때문에 빈번하게 발생하는게 안좋음 )
- Swap Device가 가득 차는 경우, 예외적으로 File을 만들어서 Page들을 저장할 수도 있음
- Physical Memory 에서 Swap Device로 Write back하는 일 : 새로운 Page를 Physical Memory에 저장해야 하는데 빈 공간이 없고, Physical memory에서 쫓아내려는 Page가 Dirty Page인 경우
-
Demand Paging Policy의 목적 :
Pysical memory와 Swap Device사이의 Data transfer를 최소한으로 발생하도록 함
-
Jim Gray의 Memory Access Latency :
- Register : 1 Cycle
- L1 Cache : x Cycle
- L2 Cache : x0 Cycle
- Main memroy : x00 Cycle
- Disk : x,000,000 Cycle
-
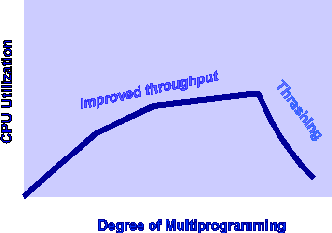
Thrashing :
Process들이 사용하는 Page들의 크기보다 사용가능한 Physical Memory의 크기가 작을 때, 사용하려고 Swap-in하는 Page에 의해 앞으로 사용할 Page가 Swap-out되면서 반복적으로 Page Fault가 일어나는 현상
-
이상적인 Demand Paging의 동작 : (근데 사실 상 불가능)
(Clairvoyant Replacement Algorithm) 앞으로 사용될 Page와 사용되지 않을 Page를 미리 알아서 Physical Memory로 불러들이거나 Swap Device로 내보내는 것
-
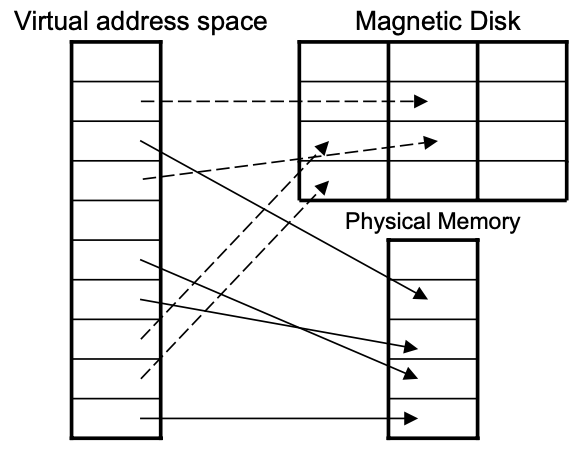
Residence Bit :
대상 Page가 Physical Memory에 있는지 Swap Device에 있는지를 표시하는 Page Table의 Flag
-
정리
- 과거에는 Program이 수행될 때 Program의 Code나 Data 등 관련된 모든 메모리가 전부 Physical Memory안에 잡혀있어야됬음
- 이렇게 수행시키면 메모리 값도 비싸고 Program의 Locality 때문에 효율적이지 못함
- 그래서 비싼 RAM에는 조금 갖게 하고 싼 Disk를 Swap Device로 사용하는 기법들이 생김 (Virtual Memory Management)
- Virtual Memory Management는 Logical Address를 Physical Address로 Mapping시켜주는 MMU라는 하드웨어의 지원이 꼭 필요함
💁🏻 요즘은 Smart Phone, TV로 인하여 Swap Device를 쓸 수 없는 상황이 다시 생김
- Smart Phone안에는 Disk가 없고 대신 Secondary storage로 Flash Memory를 사용
- Flash Memory는 Erasable ROM인데 Erase 횟수가 제한이 있기 때문에 Swap Device로 사용할 겨웅 수명이 급 격히 줄어들게 됨
Issues
Page Fault Handling
-
Page Fault : Virtual Address가 가르키는 Page가 Physical Memory에 없어서 Process가 더 이상 진행할 수 없는 상태를 OS에게 알려주는 Interrupt
- Page가 Physical Memory에 없다는 사실은 Page Table의 Residence Bit를 통해 알 수 있음
-
Page Fault Handler : Page Fault가 뜨면 OS가 실행시키는 Interrrupt Service Routine
-
Page Fault Handling 동작 과정 :
- Page Fault를 만든 Process는 중단시키고 그 Process의 Context를 저장
- 그 Process는 Sleep상태로 전환됨 (Disk Operation이 끝날 때 까지)
- Page Fault Handler는 DMA Controller에게 해당 Page의 주소를 전달
- DMA Controller는 해당 Page를 Physical Memory로 Load
- DMA Controller의 작업이 끝나면 Interrupt 발생
- OS는 Page Fault를 일으킨 Process의 수행을 재개
-
Page Fault Handling의 문제 :
-
Interrupt를 인지하는 시점 : 현재 명령의 수행이 다 종료되고 다음 명령이 수행되기 전에
-
Page Fault의 처리가 다른 Interrupt에 비해 어려운 이유 :
수행 중인 Instruction에 의해 변화된 상태를 되돌렸다가 Page Fault 처리가 끝난 후 해당 Instruction을 재개해야 하기 때문
-
-
Demand Paging에서 고민해야되는 Issue들 :
[1] 어떻게 하면 Page Fault가 최소화될 수 있는가
[2] Page Selection Policy :
어떤 Page를 언제 Physical Memory로 불러들어 올 것인가
[3] Page Replacement Policy :
Page Frame이 부족해서 어떤 희생자를 골라서 Swap Device로 보내야되는가
[4] Page Replacement Style :
Replacement를 할 때 전체 Process 중에서 고를 것인지 또는 특정 Process 중에서 고를 것인지 결정해야되는 문제
[5] Page Placement Style :
Page Frame을 어떤 Process한테 할당할 때, 어떻게 할당을 할 것인가
Page Selection Policy
- Pure Demand Paging :
- Process가 시작을 할 때 RAM에 0개의 Page로 시작을 함. 즉 초반에 Page Fault를 야기시켰다가 충분한 Page가 들어오게 되면 원할하게 돌 수 있음
- 단점 : Process가 시작을 할 때 시간 너무 오래걸림
- Prepaging :
- Pure Demand Paging의 문제를 해결하기 위해 앞으로 사용될 Page를 예측해서 미리 Main memory로 load하는 기법
- 효과적인 Prepaging 방안 : Spatial Locality에 기반하여 Page Fault가 발생한 근처에 있는 Page들을 Main memory로 load
- Request Paging :
- 논리적으로 연관성이 있는 Page들을 미리 Main memory로 load하는 기법
- 요즘은 잘 사용되지 않는 기법
Page Replacement Policy
-
Random :
🔸 Page Replacement를 하드웨어적으로 구현할 때 많이 사용됨
-
FIFO (선입선출)
🔸 Queue를 Linked list로 만들어서 구현하면됨
-
Optimal :
🔸 가장 먼 미래동안 전혀 사용되지 않을 Page를 골라서 내보냄 (입력값으로 log를 받음)
🔸 자기가 개발한 알고리즘과 성능을 비교할 때 사용됨
-
LRU :
🔸 최근에 가장 사용되지 않은 Page를 골라서 내보냄
🔸 Loop가 존재하는한 대부분 LRU가 잘 먹힘
🔸 Reference Bit (Use bit) : Main memory에 load된 Page가 Access되면 하드웨어적으로 1로 Set되고 Access되지 않으면 0으로 Set되는 Bit flag
🔸 LRU의 예측 구현 방법들 :
[1] Reference Bit을 두고 8bit register를 붙힌 방법 : 비용에 비해서 크게 효과적이지 않음
[2] Clock Algorithm : (Reference Bit만 가지고 처리 방법)
-
Reference Bit의 의미 == 특정 시간 간격 내에 이 Page가 사용된적이 있는지 없는지를 표시
-
UNIX계열 OS에서 사용됨
-
LRU를 정확히 예측하지 못하지만 구현이 단순하고 명쾌하다
-
교체할 Page를 선택하는 방법 :
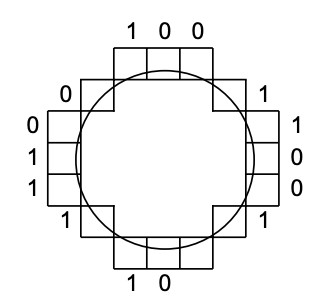
- Clock hand가 가르키는 Page의 Reference bit가 1인 경우, 0으로 바꾸고 Clock hand가 다음 Page를 가르키도록 한다
- 이 과정을 반복하다가 Reference bit가 0인 Page를 만나면 해당 Page를 교체한다
-
모든 Page들이 다 Access되서 Reference bit가 1인 경우 :
- Main memory가 작아서 모든 Page들이 빈번하게 Access된다는 것. 이럴때 Clock hand가 더 빠르게 돌아감 (Clock hand가 도는 속도가 성능척도로도 사용됨)
- 모든 Page들이 다 Access되서 Reference bit가 1인 경우 Clock hand가 한바퀴를 다 돌았으면 FIFO로 전향됨
[3] Enhanced Clock Algorithm : (Dirty bit까지 보는 방법)
- 고르는 순서
- Reference 안되있고 Clean한 Page
- Reference 안되있고 Dirty한 Page
- Reference 됬고 Clean한 Page
- Reference 됬고 Dirty한 Page
- Mac OS에서 사용됨
- 문제점 :
- Clean page가 code page여서 빈번하게 사용이 된다면 이 알고리즘이 옳지못함
-
Belay’s anomaly : Memory를 늘렸음에도 불구하고 Page Fault가 더 많이 발생하는 현상
-
Stack Algorithm :
🔸 N개 Frame으로 구성된 Memory에 load된 Page들이 항상 N+1개의 Frame으로 구성된 Memory에 Load된 Page들의 부분집합이 되는 Algoritm (Belay’s anomaly가 절대 발생하지 않음)
🔸 LRU도 Stack Algorithm (즉 오래동안 사용되지 않는거만 와따가따하지 나머지 String들은 substring로 존재함 )
🔸 FIFO는 Stack Algorithm가 아님
-
Frame Buffering :
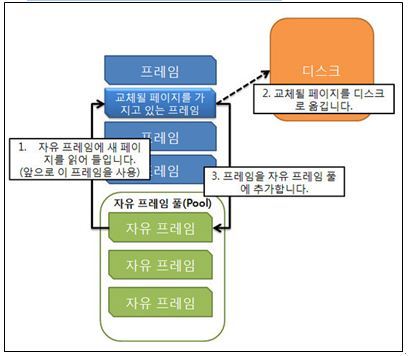
🔸 Hardware적으로 Reference bit를 제공해주지 않으면 FIFO Replacement 기법을 사용함
🔸 FIFO Replacement 기법만 가지고는 여러 부작용이 발생해서 Frame Buffering을 사용함
🔸Clock Algorithm 과 유사한 성능을 얻을 수 있음
Page Replacement Style
-
Global replacement :
🔸 메모리를 지나치게 낭비하는 놈이 있으면 전체가 다 나쁜 영향을 미친다
-
Per-process replacement
🔸 어떤 Process는 여유있게 쓰는데에 비해 어떤 Process는 쪼달리게 쓰는 불공평한 사례가 발생할 수 있음
🔸 Dynamic Adjustment를 고려해야됨 : 어떤 놈이 너무 Page Frame을 많이 받았다면 동적으로 Page Frame 개수를 줄여줘야되고 어떤 놈이 너무 Page Frame을 적게 받았다면 동적으로 늘려줘야됨
🔸 효과적인 Adaptive Allocation을 위해 Process가 현재 Memory가 부족한지 아닌지를 판단하는 방법 : 단위시간 동안 Page fault 발생 횟수를 확인
-
Per-job(User) replacement
Thrashing and Working Set
- Thrashing이 발생하는 과정 :
- System에 충분히 많은 Process가 동작 중
- 동작 중인 Process가 요구하는 Memory가 可用한 Physical Memory보다 많아서 Page Fault가 발생
- Page Fault를 처리하는 동안 Process는 block당하게 되므로 CPU Utilization이 낮아짐
- CPU Scheduler는 System이 한가한 것으로 판단하고 더 많은 Process들을 동작시킴
- Memory가 더욱 부족해짐으로써 악순환이 반복
❓ Per-process 나 Per-job(User) replacement를 통해 Thrashing을 해결할 수 있는가?
💁🏻 해결할 수 없다.
💁🏻 특정 Process가 과도하게 Memory를 사용하여 다른 Process가 영향을 받는 현상은 막을 수 있지만
💁🏻 시스템의 Memory가 부족한 상황인 경우 어떤 Process가 충분한 Memory를 확보하고 있더라도 Memory가 부족한 다른 Proces에 의해 Page Fault 처리가 지연되게 됨으로써 성능이 급격히 나빠지는 현상이 발생한다
- PC에서 Thrashing이 발생하면 안쓰는 Process를 terminate시키면 된다
❓ Smartphone처럼 Swap Device가 없는 경우 많은 Process로 인해 Memory가 부족하면 어떻게 처리하는가?
💁🏻 Android의 Low Memory Killer와 같이 동작중인 Process를 강제로 종료시켜 완전 Memory에서 제거할 수 밖에 없음
-
Effective memory access time :
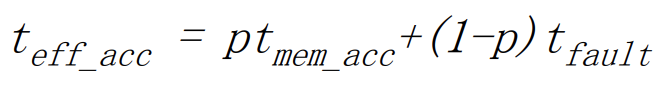
- p : Page가 Memory에 Load되어 있을 확률
- 1-p : Page Fault가 발생할 확률
-
Thrashing 현상을 방지하기 위한 방법
-
Working set : 어느 시점에 특정 Process가 Access하는 Page들의 집합
- Program이 수행하는 전체 Lifetime 동안에 jump나 subroutine call이 발생하여 Working set은 변한다
-
Working set 모델에서는 process의 working set 전체가 메모리에 올라와 있어야 수행되고 그렇지 않을 경우 모든 frame을 반납한 후 swap out
- Thrashing을 방지하고 degree of Muliprogramming 를 결정한다
- A solution proposed by Peter Denning:
- Working set을 알아낸다는 것은 불가능함으로 그 대안으로 과거에 빈번하게 사용된 Page들을 알면 working set에 포함시키지 않음 (담고있는 가정 : 어느 정도 stable한 Locality가 현재 main memory에 들어와있음)
- Working Parameter : 현재부터 과거 t time unit동안 access된 page들을 working set이라고 말함
- t가 무한대 일 경우, Process가 한번이라도 터치한 모든 page들이 다 working set에 들어감
- Parameter 튜닝하는게 어려운 일임
- 이 방법은 구현을 가능하게 만들지 못함
-
Working set을 구현하기 위한 실제 방법 :
[1] Resident Set
-
Resident Set : 어떤 Process가 어느 시점에 Main memory에 가지고 있는 Page들
- 기본적인 가정 : 현재 active한 process들이 Thrashing을 만들지 않고 잘 돌고있다면 현재 Main Memory에 있는 Page들이 그 Process의 Working set일 가능성이 높다
- 그래서 OS는 Page Fault가 얼마나 발생하는지를 확인하여 현재 특정 Process가 Thrashing을 만들지 않고 잘 돌고 있는지를 판단할 수 있다
- Page Fault 발생 횟수에 따른 OS의 Memory 할당 정책 :
- Threshold보다 많이 발생하는 경우 : 해당 Process에게 더 많은 Memory를 할당
- Threshold보다 적게 발생하는 경우 : 해당 Process에게 할당한 Memory를 회수
-
-
Miscellaneous Issues
- Physical Memory가 커짐
- Page Frame이 넉넉하니깐 Page Replacement 알고리즘이 덜 중요해짐
- Virtual Address Space가 커짐
- 64bit Machine에서 Page size를 4K로 했을 때, 각 Process들이 가지고 있어야 될 최대 Page table의 size는 64KTB가 됨
- 큰 Virtual Address Space를 어떻게 관리해야되는 것이 이슈가 되고있음
- 큰 Page Table을 handling하는 것
- 큰 Page Table의 문제
- Page Table을 유지하기 위해 필요한 공간이 너무 큼
- Page Table이 Physical Memory의 연속적인 공간에 존재해야 함
-
3가지 접근 방법 :
[1] Hierarchical Page Table :
-
Table Space를 줄이지는 못하지만 Page Table들이 Physical Memory상에 조각으로 나눠져서 분산될 수 있게 허용
-
Example. 32bit Machine에서 Page size는 1K (=2^10)
💁🏻 Logical Address는
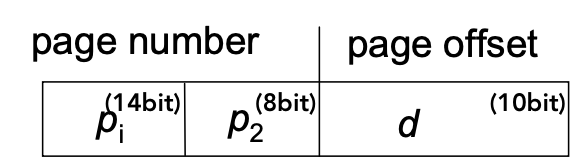
- first level index : 14bit
- second level index : 8bit
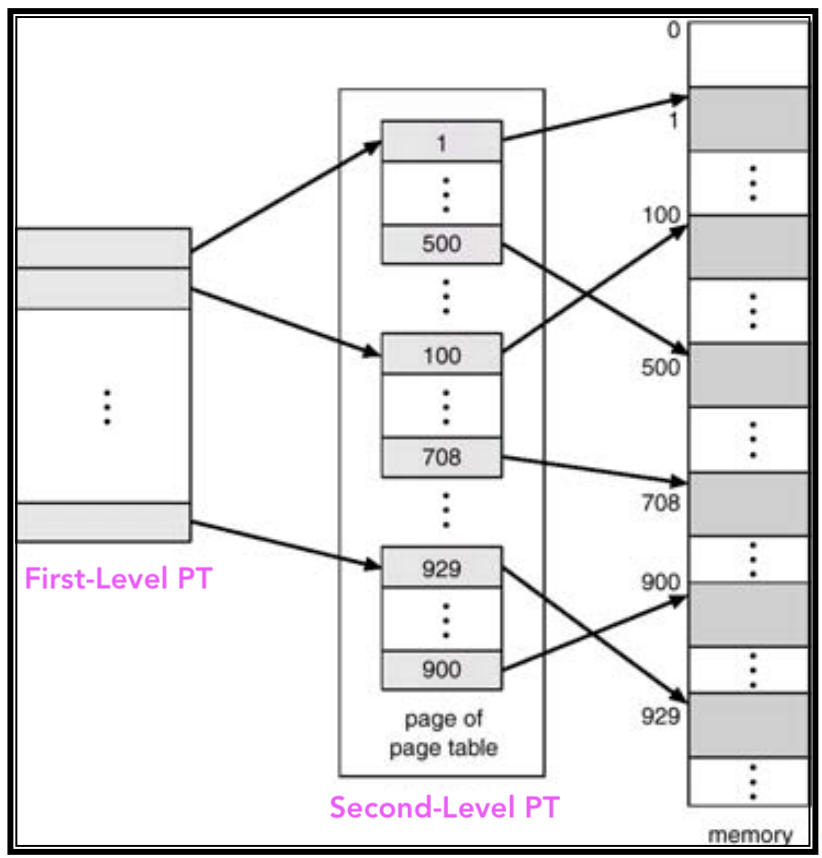
- First Level Page Table에서 2^14개의 Page들을 지적을 하고 있고 각 Page들이 256(2^8)개의 Page Table entry들을 가지고 있음 - First Level Page Table은 연속적이여야 되지만 Size가 작아서 OS가 충분히 handle할 수 있는 규모다 -
문제점 : Performance overhead - Page Table access하기 위해서 2번의 Memory reference가 필요함
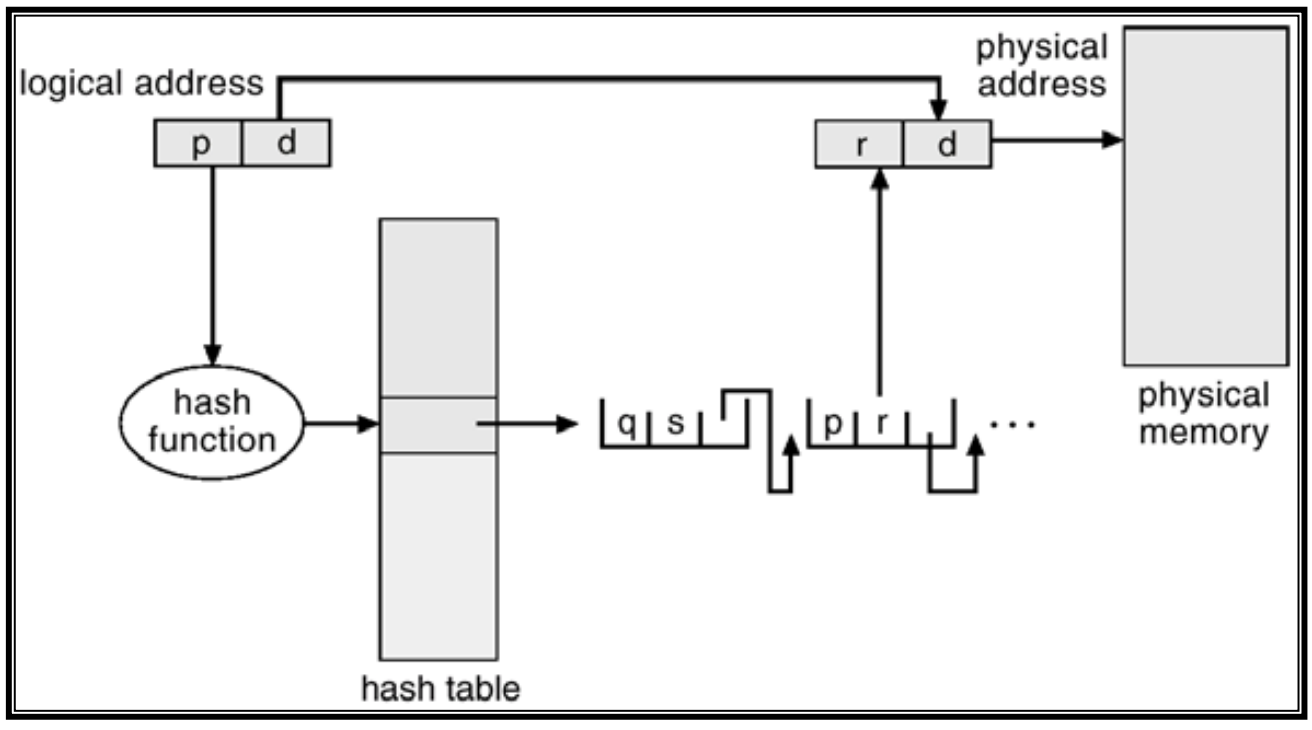
[2] Hashed Page Table :
-
Page Number를 hash table을 통해서 해당하는 entry들을 얻어옴
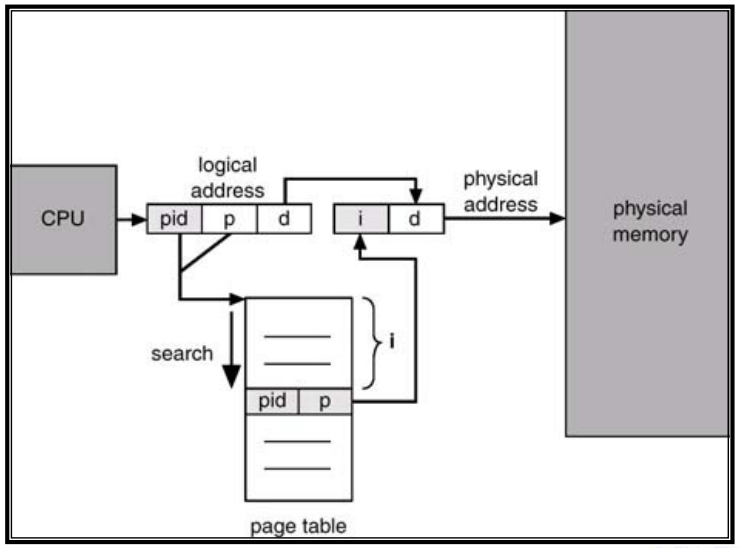
[3] Inverted Page Table :
-
Address space 만큼 Page table을 갖는게 아니라 Physical Memory 만큼 Page table을 갖는다
-
CPU는 Page number와 offset을 주소로 내는데 이 Page number와 이 주소를 발생시킨 process의 id를 key로 해서 Hashing을 하게됨. Hashing을 통해 들어간 entry에는 Physical Frame number가 있음
-
이 Mechanism이 잘 동작할려면 Hash function의 성능이 좋아야된다
-
《Reference》