Why Process Synchronization?
Background
-
Scalability : Hardware성능을 증가시켰을 때, Linear하게 Software적인 성능도 증가하는 것
-
실제로는 CPU에 개수가 어느 Threshold에 다가가게 되면 더 이상 성능이 증가하지 않는 문제가 생김
-
그 이유는 Synchronization 문제 때문에
-
Smartphone의 화면이 freeze된 상태 : Smartphone의 input key들을 누르면 interrupt가 발생하지만 interrupt 처리가 되지않음. 그래서 입력한 input이 Application에 전달이 안되는 것. 이것도 Synchronization 문제
-
- Process Synchronization : 여러 개의 process들이 interaction할 때 Resource를 공유하는 것
-
Synchronization Problem : 서로 interaction하는 process들이 Resource를 공유할 때, OS 차원에서 공유되는 Resource의 사용패턴을 잘 관리하지 않으면 program의 correctness가 깨지는 문제
- Process들이 interaction을 하는 것을 허용하는 이유 :
- Degree of Concurrency를 높이기 위해서
- Resource를 공유할 수 있기 때문에
- Resource를 공유하게 되면 interaction 문제는 피할 수 가 없음
- Process들이 interaction하게 되면 나타는 특징들 :
- Resource를 공유
- Computer system의 상태 (Main memory나 Register들 같이 기억할 수 있는 장치의 저장되어 있는 정보들) 를 공유
- Process의 수행이 non-deterministic 해짐 : Debugging할 때 어려운 문제가 발생
- Process들이 interaction을 하는 것을 허용하는 이유 :
- 우리가 Concurrency를 얘기할 때, Process간의 Concurrency를 얘기할 뿐만 아니라 Process와 interrupt service routine의 Concurrency도 같이 생각함
- interrupt service routine도 독자적인 Asynchronous한 수행 Entity로 간주함
-
Example. 원자로 Monitoring System
-
원자로 안에 온도센서 2개가 있어서 두 온도 센서의 값이 차이가 있다면 알람을 울리는 시스템
-
System의 2가지 Part
- 온도 센서의 값을 읽어서 내부적으로 data를 업데이트하는 부분 (Interrupt Service Routine으로 구현)
- data를 읽어서 값을 비교하는 부분 (main user process로 구현)

-
위에 Code의 문제점 :
-
iTemp0와iTemp1은 Correlated된 값들이다. 즉, 한꺼번에 같이 처리되야되는 데이터들. 하지만 데이터가 중간에 다르게 변질되면 문제가 발생함
-
-
수정된 Code V1

- 수정된 Code의 문제점 :
if(iTemp0 != iTemp1)부분을 Assembly code로 하면iTemperatures[0]Array index에서 Register로 읽어오고 다음iTemperatures[1]Array index에서 Register로 읽어오고 등등.. 여러 명령어 sequence 가 되기 때문에iTemperatures[0]과iTemperatures[1]이 한꺼번에 같이 처리 될 수 없다.
- 수정된 Code의 문제점 :
-
수정된 Code V2

-
iTemp0와iTemp1가 데이터를 읽어올 때, Interrupt를 안걸리게 만듬
-
-
- Atomic operation : 기능적으로 분할 할 수 없거나 분할 되지 않도록 보증된 조작
- ex. 어떤 Global Resource를 읽고 수정하고 다시 쓰는 전체의 과정을 쪼갤 수 없는 기본단위로 만드는 것
-
Example. Atomic operation을 구현하는 것은 Software으로만은 어렵다
-
몇개 Process들이 Buffer를 사용하고 싶은데 서로 같이 사용하는 걸 막기위해
BufferIsAvailflag 변수를 두어서 Buffer가 사용 가능할 때만 들어갈 수 있도록 약속함
-
Share 하는 Resource : Buffer와
BufferIsAvail변수
-
Proc1이BufferIsAvailflag 변수에 아무런 동작을 하지 않았기 때문에Proc2는BufferIsAvailflag 변수를 True로 보게 됨 - 이렇게되서 서로 같이 사용하는 걸 막지 못했음
-
-
-
Race Condition : 여러 Process들이 동기화 절차를 거치지 않고 동시에 자원을 사용하기 위해 경쟁함으로써 그 수행 결과를 예측할 수 없게 되는 상황
- Single processor system의 경우
- Process와 interrupt service routine간의 Shared resource문제 ,
- Process와 Process간의 Shared resource문제 (context switching이 발생할려면 꼭 interrupt가 필요)
- 모두 interrupt disable로 해결할 수 있다
- 하지만 interrupt disable이 항상 해결책이 될 수 는 없다
- interrupt disable을 사용한 Synchronization의 문제 : interrupt disable은 시스템 전체에 영향을 미치기 때문에 상관없는 Process의 수행도 방해하게됨
- 명령어 1~2 cycle같이 짧은 시간 동안 interrupt disable를 진행시키면 괜찮다
Critical Section
- 어느 Code의 부분이 Non-interruptable하게 Atomic하게 만들 었을 때 그 Code section을 Critical Section이라 함
Mutual exclusion (Mutex)
- Critical Section안에는 Mutual exclusion현상이 나타나야됨
- 일단 한 Process가 들어왔으면 다른 Process들을 전부 배재시킬 수 있는 능력
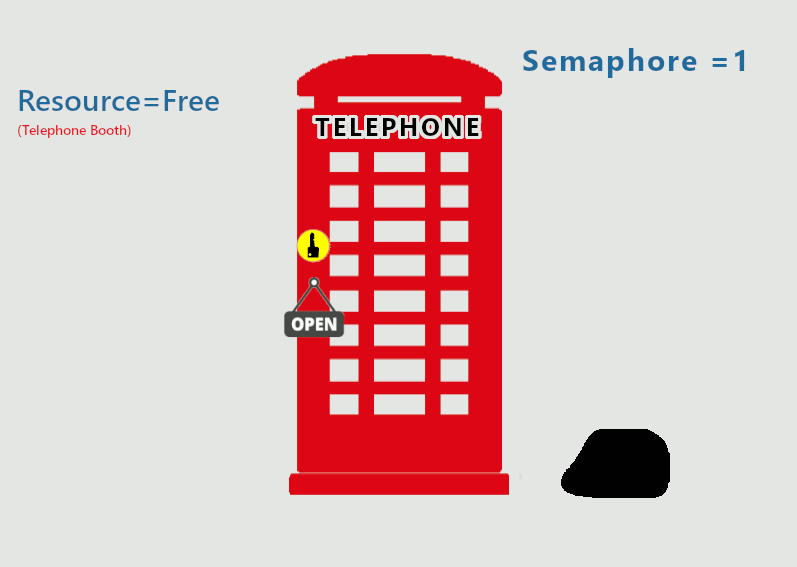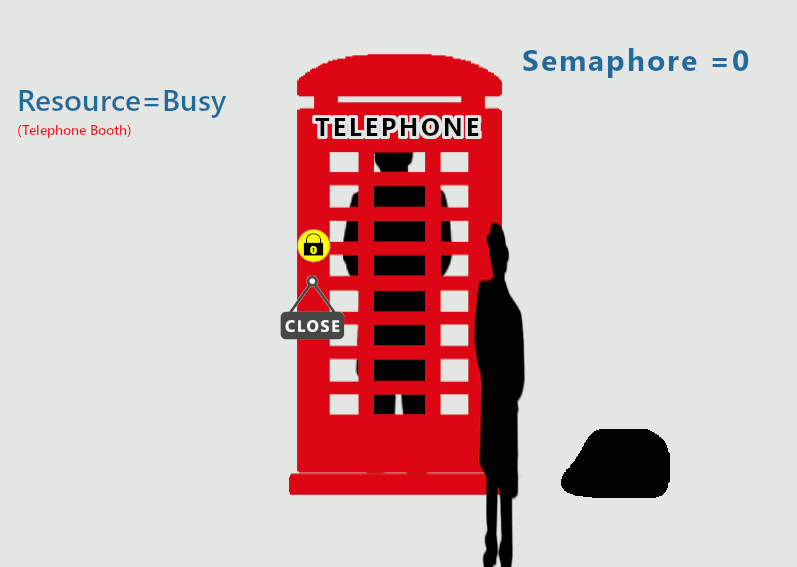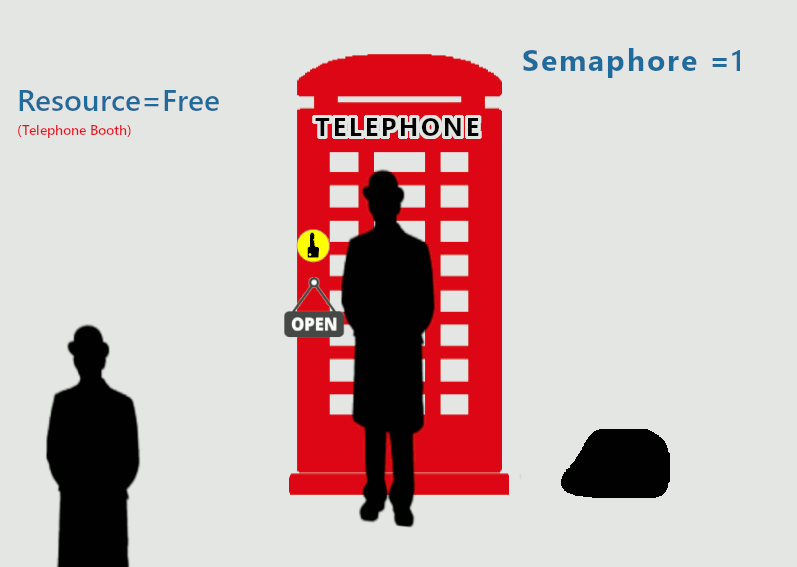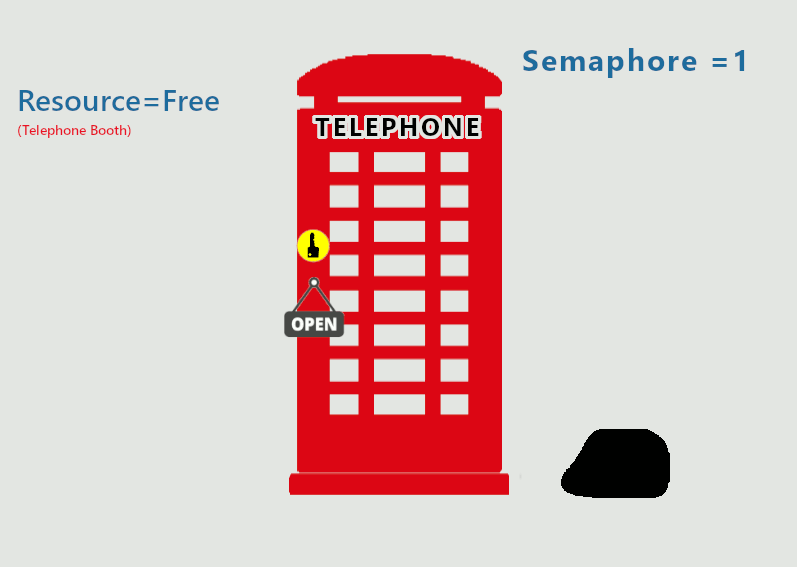
Semaphore
-
가장 대표적인 Mutual exclusion mechanism
-
Semaphore : Synchronization을 제공해 주는 integer형 변수
-
Semaphore의 역할
- Mutual exclusion 제공해줌
- Scheduling도 제공해줌
-
Semaphore의 종류
- Binary Semaphore : 있다/없다만 얘기하는 것
- Counting Semaphore : 여러개 있다를 얘기하는 것
Semaphore의 Operations
-
P( Semaphore ) = lock( Semaphore ) = wait( Semaphore )
-
V( Semaphore ) = unlock( Semaphore ) = signal( Semaphore )
-
Usage :

Examples
-
Semaphore Programming을 할 때
- 가장 먼저 Semaphore가 몇개가 필요한지 알아야됨
- Share되는 Resource의 종류만큼 Semaphore가 있어야됨
- 그 다음 그 특정 Type의 Resource가 몇개 있느냐를 알아야됨
- 가장 먼저 Semaphore가 몇개가 필요한지 알아야됨
-
Example. Semaphore가 Mutual exclusion를 제공 할 때
- Semaphore를 적용한 Buffer 예제
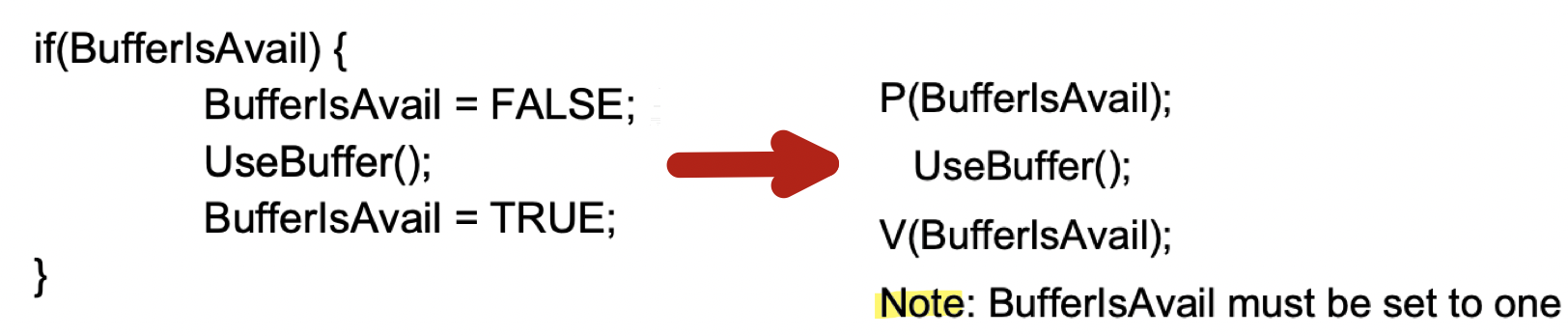
- 특징 :
- Semaphore가 Critical section의 시작과 끝에서 Pair로 사용됨
-
Example. Semaphore가 Scheduling을 목적으로만 사용될 때
-
I/O Device를 통해서 입력을 넣게 되면, Interrupt service를 발생하고 그 값을 읽어가는 user process가 생성이 되게하는 프로그램
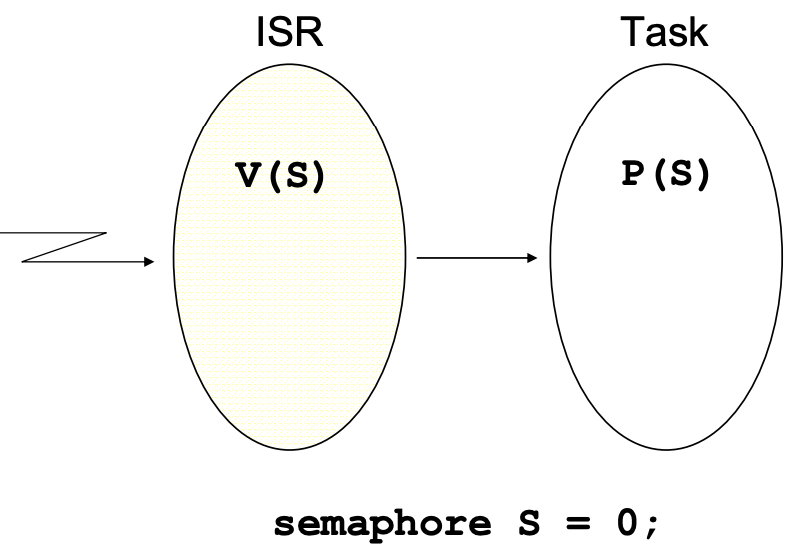
-
특징 :
- Task 시작부분에 P()를 넣어 waiting하게 하고 Interrupt service routine은 중간에 V()를 넣어서 이 Task를 깨우게 한다
- Semaphore의 초기값을 0으로 setting
-
-
Example. Producer/Consumer - Scheduling과 Mutual exclusion이 결합
-
Producer : 데이터를 끊임없이 생성하는 역할, 만약 Buffer가 꽉차면 생성 중단
-
Consumer : 데이터를 끊임없이 읽어가는 역할, 만약 Buffer가 비어있면 읽기 중단
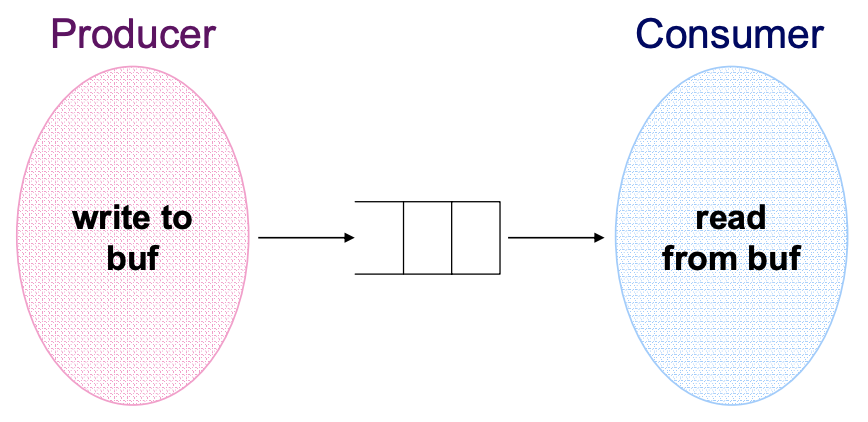
-
Share 하는 Resouce들 : Data와 Buffer
-
Buffer에 저장 될 수 있는 데이터의 개수가 1일 경우
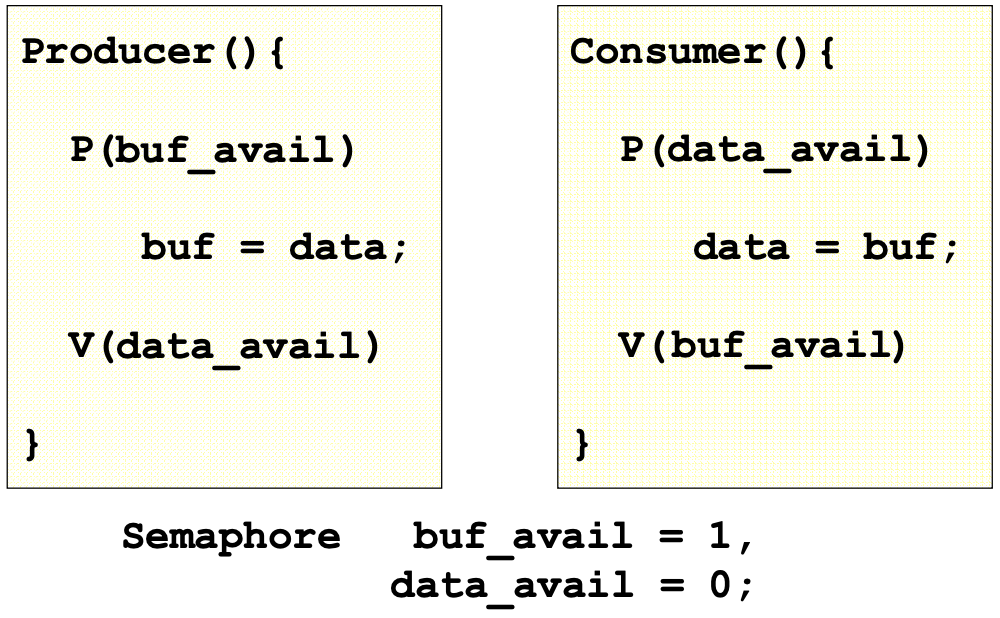
-
Semaphore의 단점
-
Unstructed Programming construct이기 때문에 Compiler등의 도구를 사용한 Debugging이 어려움
-
ex)
If () { }문이 있으면 만약 이 중{나(를 빠트릴 경우, Compiler가 error를 알려준다. 하지만 다음과 같은 경우 실행이 잘못되는데 Compiler가 error를 알려주지도 못하고 어디를 고쳐야 될지도 파악하기 힘듬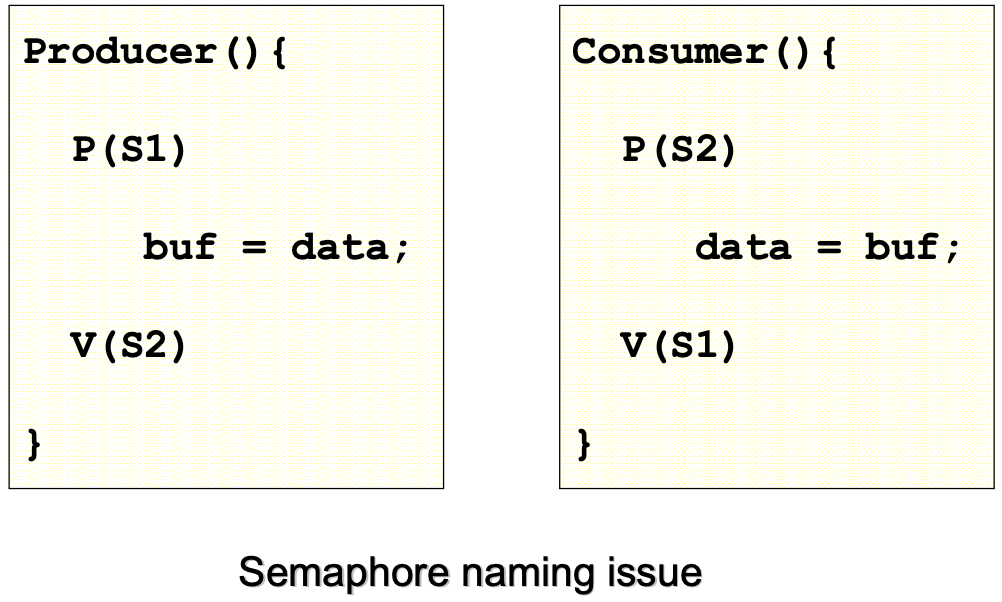
-
Semaphore 구현
-
Uni-processor Solution : ( Multi-proccesor용으로는 적용
 )
)struct Semaphore{ int cnt; Queue queue // Waiting Queue }-
semaphore변수는 모든 Process가 P()나 V() operation을 할 때 읽고 수정하는 Shared global 변수- 즉
semaphore는 원래 어떤 Shared Resource를 보호하기 위해 있는 것인데.semaphore이 변수 자체도 Shared global 변수임으로 어떤 보호가 필요하다. 그래서disableInterrupts()과enableInterrupts()를 사용하였다.
- 즉
-
semaphore.cnt의미- 0 이상인 경우 : 남아있는 Resource (열쇠)의 개수
- 0 이하인 경우 : 절대값을 취해면 Waiting Queue에서 대기중인 Process의 개수
-
P( )
P(semaphore){ disableInterrupts(); if(semaphore.cnt-- > 0){ enableInterrupts(); }else{ sleep(semaphore.queue); // 누군가 열쇠를 반납할 때 까지 Sleep함 } } -
V( )
V(semaphore){ disableInterrupts(); if(semaphore.cnt++ >= 0){ enableInterrupts(); }else{ wakeup(semaphore.queue); } } -
Sleep()
sleep(queue){ enqueue(current_process, queue); enableInterrupts(); yield_cpu(); } -
Wakeup()
wakeup(queue){ waiting_process = dequeue(queue); enableInterrupts(); reschedule(p); }
-
-
Multi-proccesor Solution :
- Multi-proccesor의 상황
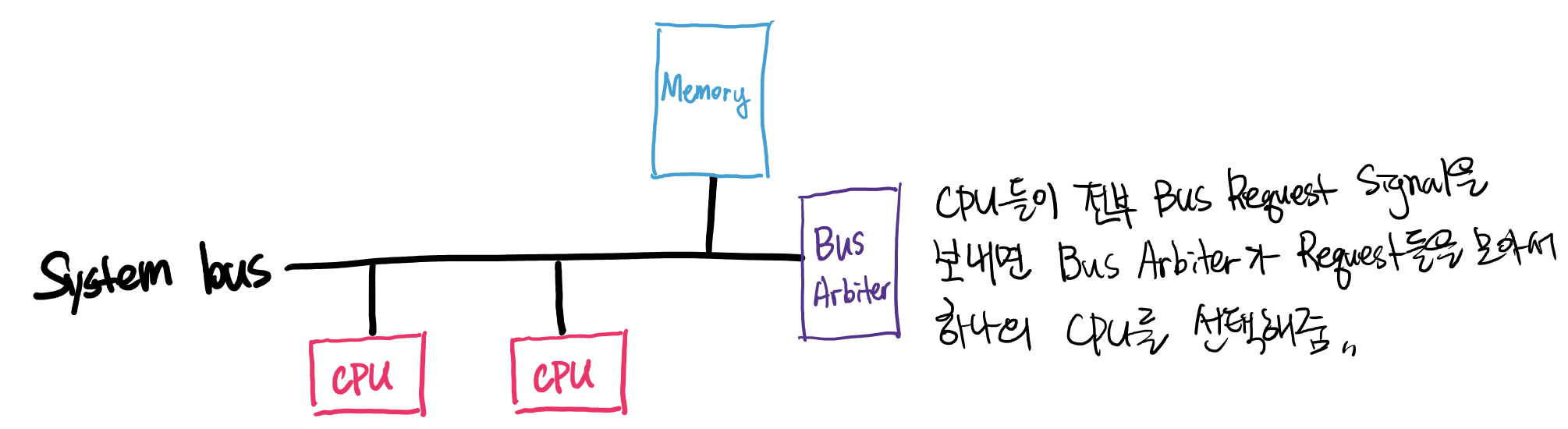
-
Multi-proccesor synchronization 을 하기 위해서는 Hardware적 support가 필요함.
- Multi-proccesor에서 Atomic operation을 구현 : Atomic operation을 수행하는 동안 Bus를 장악하여 다른 Processor의 Bus Transaction을 차단
-
Atomic operation Example : Test And Set 명령
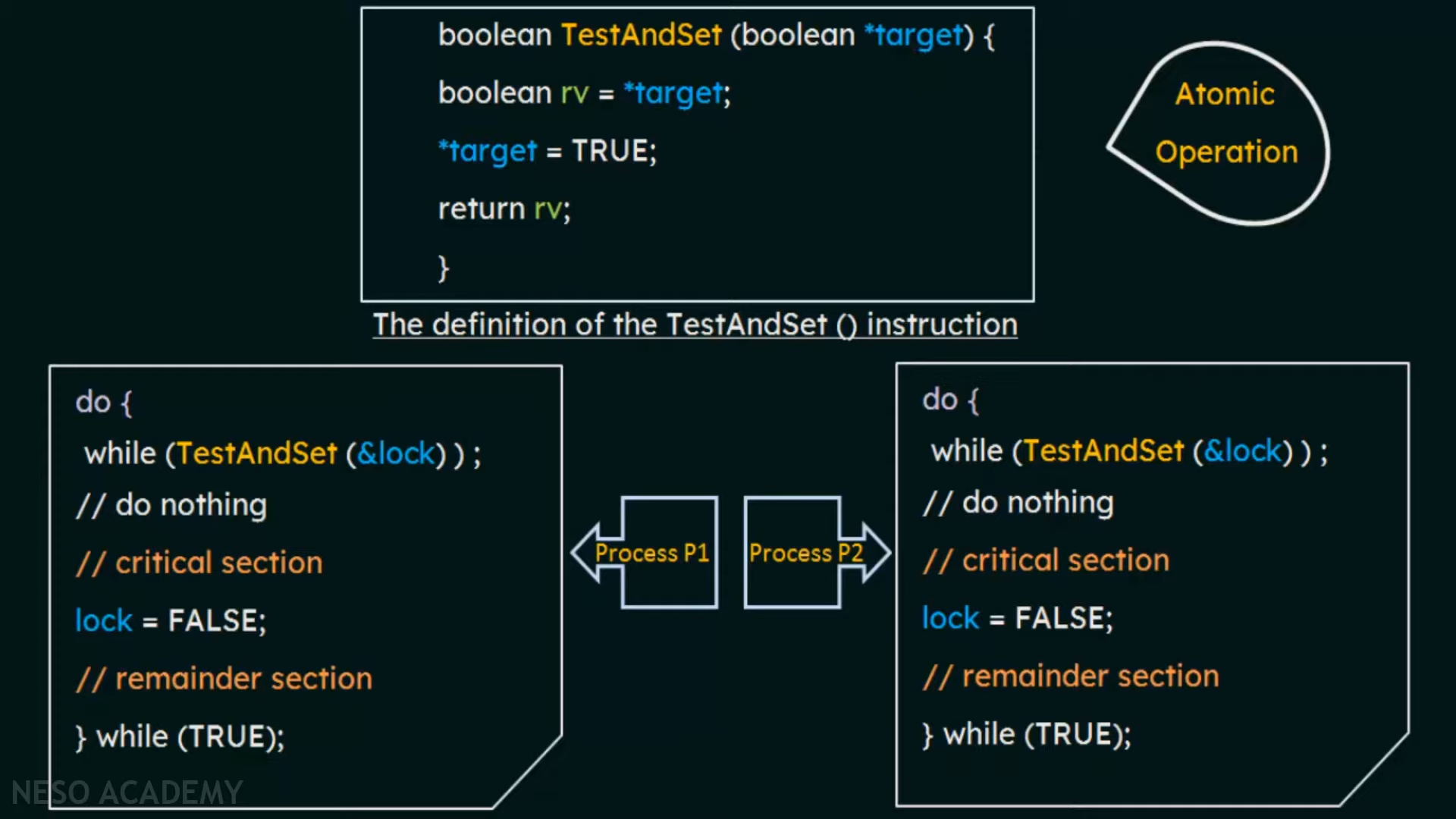
💁🏻
while(TestAndSet(&lock) == 0);일 때 while 다음 line을 실행할 수 있음💁🏻
while(TestAndSet(&lock) == 1);일 때는 다시 while line을 실행💁🏻
&lock안의 값이 Semaphore의 역할🔸 실행과정 : Process 1이 먼저 실행될 경우
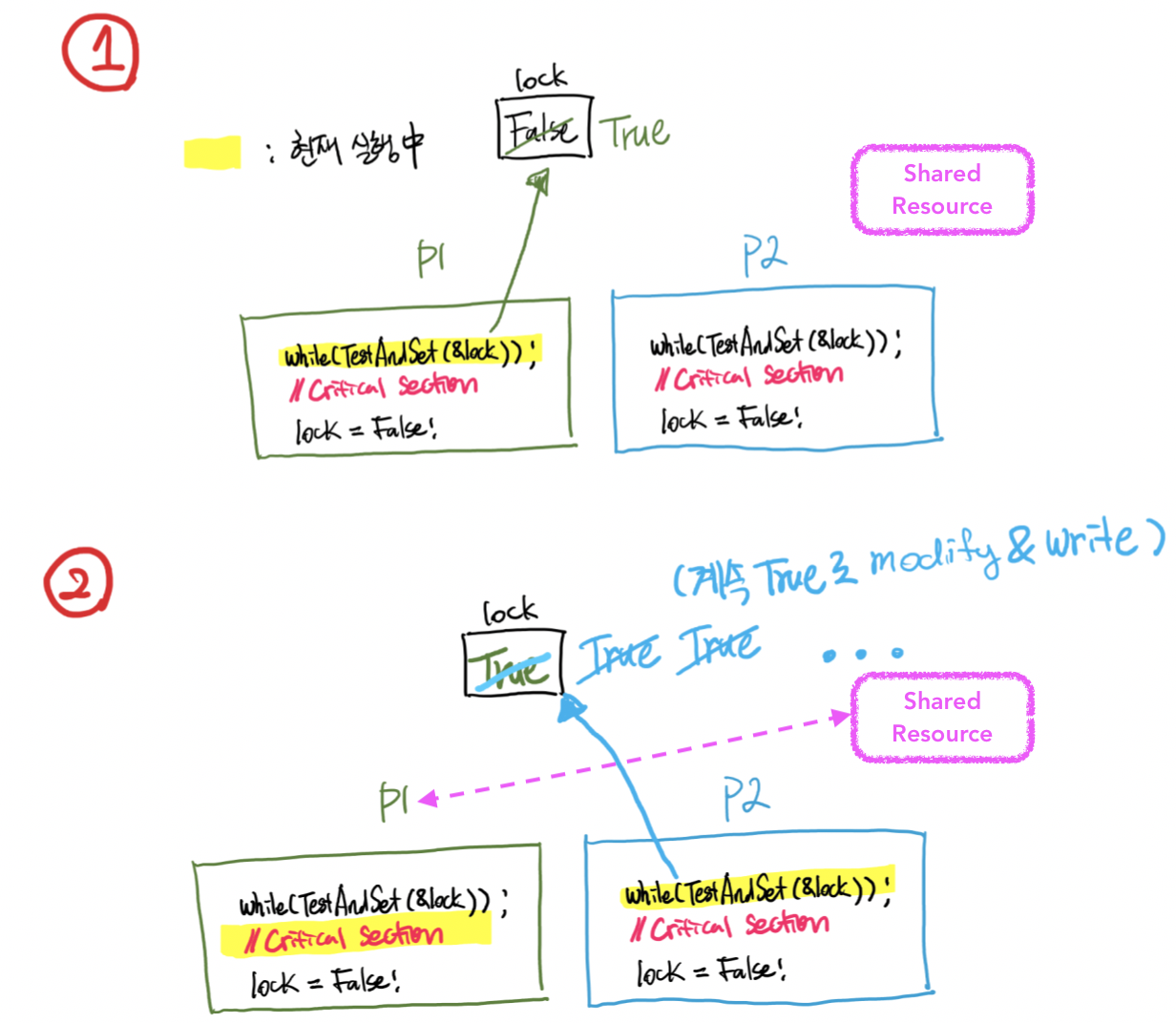
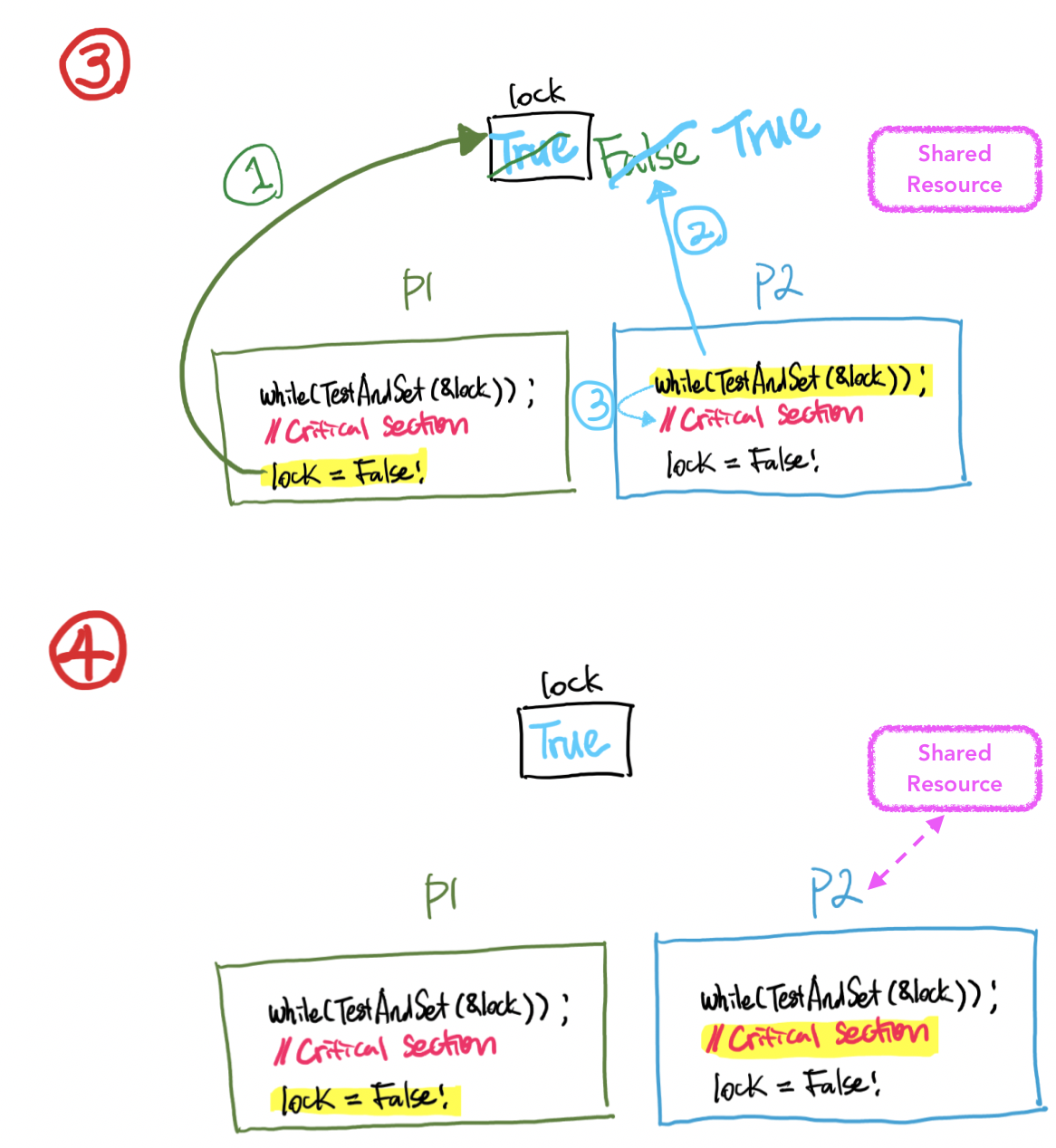
- Test And Set 명령의 문제점 : Busy Waiting (Critical section에 들어가기 위해서 계속 CPU를 활용하게됨)
-
while(TestAndSet(&lock));💁🏻 Spin Lock
정리
- Synchronization을 제공하기 위해서 OS차원의 mechanism이 Semaphore이다
- Semaphore를 구현할려면 Hardware적인 Preemetive가 필요하다
- Single Processor일 경우, Interrupt Enable/Disable
- Multi Processor일 경우, Test and Set 같은 Atomic operation
- Test And Set 명령을 이용해서 loop를 만들면 Spin Lock을 구성할 수 있고 Spin Lock은 성능에 나쁜 영향을 준다
Monitor
-
Semaphore mechanism이 Unstructed Programming construct이기 때문에 등장하게 됨
-
Monitor는 Abstract Data type의 구조에 기반해서 구현이 됨. 그리고 Synchronization과 Scheduling의 필요 때문에 몇 가지 operator를 더 추가함
monitor QueueHandler{ struct { ... } queue; //shared data AddToQueue(val) { // code to add to shared queue } int RemoveFromQueue() { // code to remove } } -
Monitor라 하는 것은 기본적으로 큰방에 들어가는 것
- Process가 혼자들어가기 때문에 Monitor안에서 정의된 Shared된 variable은 더 이상 Synchronization 문제를 고민하지 않고 작성하면 된다
- 그대신 Monitor안에서 어떤 조건 때문에 더 수행을 할 수 없는 경우를 대비해서 condition 변수라는 새로운 개념을 만들었고 거기에 wait()와 signal() operator를 만들었다
-
Monitor의 condition 변수 : 어떤 조건이 충족되기를 기다리고 있는 Process들의 Waiting queue
-
Monitor 내부의 공유 변수들을 따로 보호하지 않는 이유 : Monitor는 한번에 하나의 Process만 내부의 method를 수행 할 수 있도록 허용하기 때문
-
2가지 Style의 Monitor :
-
Hoare Style Monitor (Signal-and-Urgent-Wait Monitor)
Wait Queue에서 깨어난 Process가 바로 Monitor 내부로 진입하는 방식의 Monitor
-SU.png)
💁🏻 1개의 condition 변수가 있는 Hoare Style Monitor
💁🏻 Signaler Queue (s) : Signal을 보낸 Process가 Monitor 밖에서 대기하기 위한 Queue
-
Brinch-Hansen Style Monitor
Wait Queue에 Signal을 보낸 Process가 수행을 계속하는 방식의 Monitor
-
-
Monitor의 장점 :
- Monitor안에서 정의된 Shared된 variable은 더 이상 Synchronization 문제를 고민하지 않고 작성할 수 있다
What is Deadlock?
-
Resource를 Share할 경우에 Deadlock가 발생할 가능성이 높다
-
Resource Allocation Graph :
-
사각박스 : Process
-
둥근박스 : Resource
-
Resource ➡️ Process : 자원이 프로세스에 할당되었음을 표현
-
Process ➡️ Resource : 프로세스가 자원을 사용하기 원하는 상황을 표현
-
-
Deadlock 탐지 방법 : Resource allocation graph내에 cycle이 존재 할 경우 Deadlock가 존재. 단, Resource를 관리하는 Semaphore가 Binary Semaphore인 경우에만 반드시 Deadlock이 발생
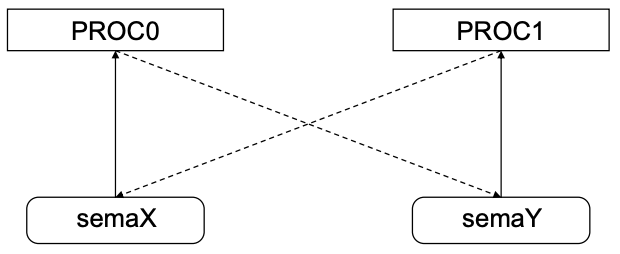
-
Deadlock: 자원을 공유하는 프로세스들이 서로가 원하는 자원을 분점하고 있기 때문에 더 진행하지 못하는 것
- Deadlock에 관련된 Process는 수행하지 못하지만 Resource를 낭비하지 않음 (CPU관점예서). 왜냐하면 Process 자기가 원하는 Resource를 기다리면서 전부 waiting상태에 있기 때문
-
**Livelock : **Resource을 계속적으로 사용하지만 아무런 일도 하지 못하는 상황
-
Indefinite postponement : 절대 일어날 수 없는 이벤트를 기다리는 상황
- 보통 혼자서 발생됨
- ex) 어떤 Process부터 메세지를 기다린다고 할 때, 그 Process가 문제가 생겨 terminate되었을 경우 indefinite postponement에 빠지게 된다.
-
Deadlock이 생기는데 필요조건 4가지 (모두 만족해야됨)
- **Mutual exclusion **: 어떤 한 Process가 Resource를 점유하는 데 일단 점유되면 그 Resource는 다른 프로세스에게 공유가 안됨
- No preemption: 내가 Resource를 장악하면서 상대편 Resource를 원할 때 내 Resource를 포기하지 않는다
- Hold and wait(Multiple independent requests): 내가 Resource를 가지고있는데 다른 Resource 원하는 상황에서 내 Resource는 점유하면서 원하는 Resource도 계속 원하고 있는다
- Circular wait: Resource를 점유하고 원하는 상황이 서클이 되야 한다
- Deadlock을 처리하는 방법
[1] Prevention : 교착상태 예방 기법은 교착상태가 발생하지 않도록 사전에 시스템을 제어하는 방법으로 교착상태 발생의 4가지 조건 중에서 어느 하나를 제거함으로써 수행됩니다. 자원 낭비가 가장 심한 기법입니다.
[2] Avoidance : 교착상태가 발생할 가능성을 배제하지 않고 교착상태가 발생하면 적절히 피해나가는 방법
[3] Detection and recovery : Deadlock 상황이 발생하면 그 상황을 바로 인지해서 Deadlock을 깨버리는 방법
Deadlock Avoidance
- Process가 System에 존재하는 Resource들을 점유하고 있으면 그 상태를 2가지로 나눔
-
Safe State : 시스템이 Deadlock 상태에 빠지지 않는 상태
-
Safe State Sequence가 1개라도 존재한다면 Safe State입니다.
-
Safe State Sequence : 바로 이전 프로세스가 수행을 마치고 반납한 자원과 현재 할당 가능한 자원을 이용해 현재 프로세스에게 할당이 가능한 프로세스의 자원 할당 순서
(당장 할당이 불가능해도 이전의 프로세스들이 반납을 함으로써 할당이 가능하다면 그 순서 또한 Safe State Sequence라고 함)
-
만일 Safe State라면 Deadlock은 반드시 일어나지 않음
-
-
Unsafe State : 시스템이 Deadlock 상태에 빠질 가능성이 있는 상태
- Unsafe State에 들어갔다해서 그 System이 꼭 Deadlock에 들어가나?
- Unsafe State에 들어갔다해서 그 System이 꼭 Deadlock에 들어가나?
-
Banker’s Algorithm
-
직접적으로 Safe State 인지를 검사하는 알고리즘으로 Safe State Sequence를 찾는 알고리즘

-
Example. Youtube
-
단점 :
-
항상 Unsafe State를 방지해야 하므로 Resource 이용도가 낮음
-
최대 자원 요구량을 미리 알아야됨 (그래서 실제 프로그램에 적용하기 어려움)
-
Deadlock Detection and Recovery
Deadlock Detection
-
Single Resource일 경우
- Resource Allocation Graph를 그려서 사이클이 발생하면 Deadlock이다
-
Multiple Resource일 경우
-
Banker’s Algorithm을 약간 변경시킨 알고리즘을 이용해서 Deadlock Detection을 한다

1단계 : Allocation != 0 then Finish[i] =false; Otherwise Finish[i] = true
💁🏻 Allocation이 0이라는 것은 현재 이 프로세스에 할당된 자원이 없다는 뜻이고 이것은 Deadlock이 발생하기 위한 조건 중 Hold & Wait를 위배하므로 이 프로세스는 Deadlock을 유발하지 않는 프로세스라는 뜻. 그러므로 Finish[i] = true로 만들어주어 검사를 하지 않게 됨.
2단계 : Banker’s Algorithm과 같음
3단계 : Banker’s Algorithm과 같음
4단계 : 할당해줄 것을 모두 할당해주고 Finish[i] = false인 프로세스가 존재한다면 그 프로세스는 Deadlock에 빠져있는 프로세스이므로 이러한 방법으로 Deadlock에 빠져있는 프로세스를 찾아냄.
-
Deadlock Recovery
-
Deadlock을 감지한 다음 Deadlock을 해소해야된다
-
보통은 PC에서는 사용자가 알아서 Deadlock 문제 해결(Process Kill) 하지만 Server에서는 문제가 됨
- Server에서는 복잡한 방법으로 Deadlock을 찾기보단 Process의 response-time을 모니터링하는 Time-out loop(흔히 watchdog timer)를 둔 다음 Process가 일정 시간 안에 끝나지 않았으면 Process Kill 한다.
-
종료의 비용이 큰 경우(Deadlock을 감지해서 바로 kill할 수 없을 경우) CPR를 사용한다
-
Checkpoint and Resume - CPR
앱이 동장 중에 일정 시간 간격으로 앱의 모든 상태를 디스크에 저장하고, 문제가 발생했을 때 저장된 앱의 상태를 사용해 앱의 수행을 재개하는 기법
-
-
Kernel이 Deadlock 상태에 빠지는 경우 : 일정 시간동안 Kernel이 반응하지 않으면 Watchdog Timer가 동작하여 Kernel을 종료하고 재시작 시킴
《Reference》