Computer Vision Tasks
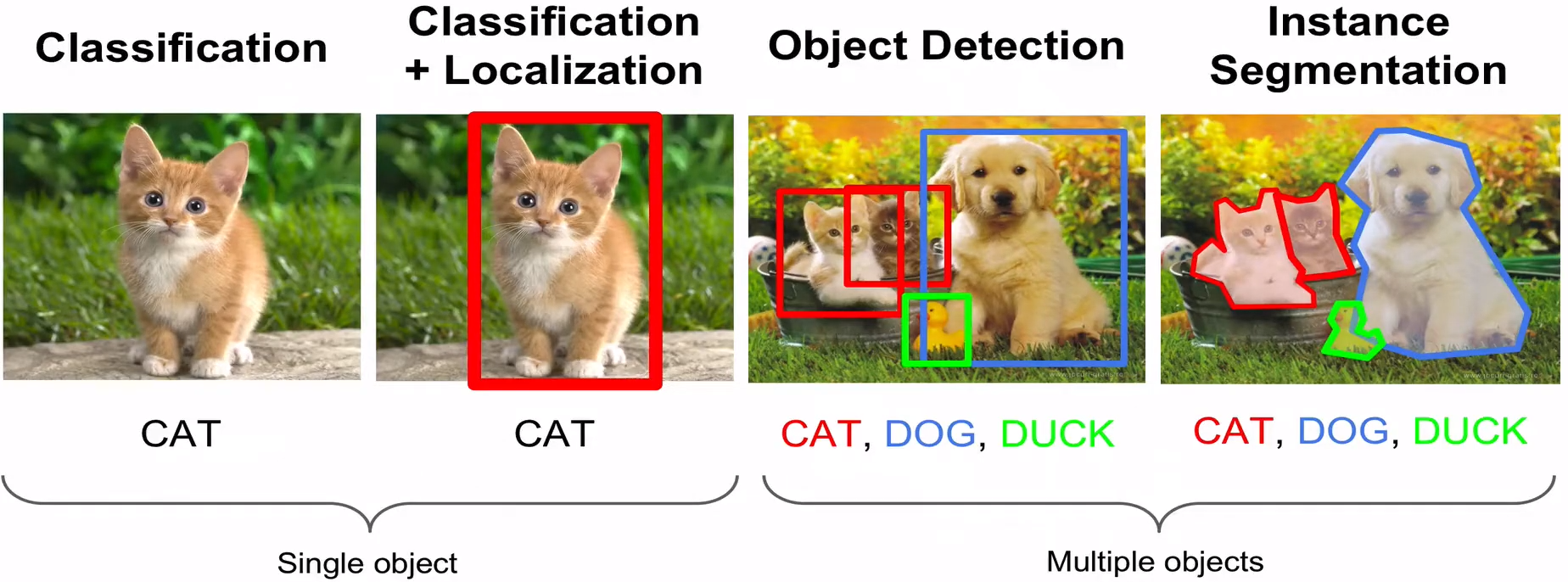
- Classification : 이미지를 보고 labeling하는 것
- Localization : 이미지에서 Boxing을 하는 것
- Detection : 이미지에서 여러가지 Object들을 모두 찾아내는 것
- Segmentation : 이미지에서 여러가지 Object들을 형상대로 따내는 것
Classification + Localization
Classification, Localization
| Classification | Localization | |
|---|---|---|
| Input | Image | Image |
| Output | Class label | Box in the image (x,y,w,h) |
| Evaluation Metric | Accuracy | IoU |
Localization as Regression
-
Steps :
-
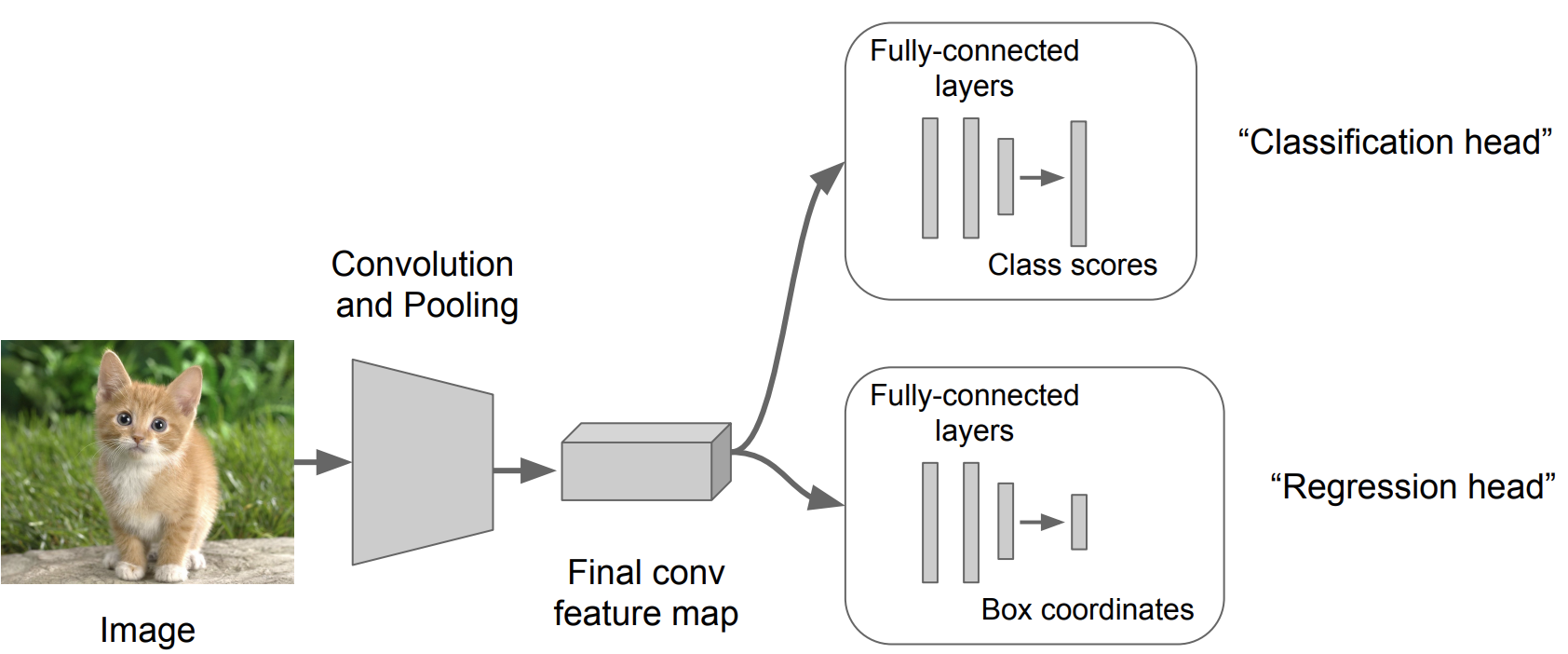
일반적인 Classification 모델(= “Classification head”) 을 훈련시킴
- Loss : Softmax Cross Entropy
-
Output이 Box의 좌표가 나오는 뒷단(= “Regression head”)을 추가시킴
-
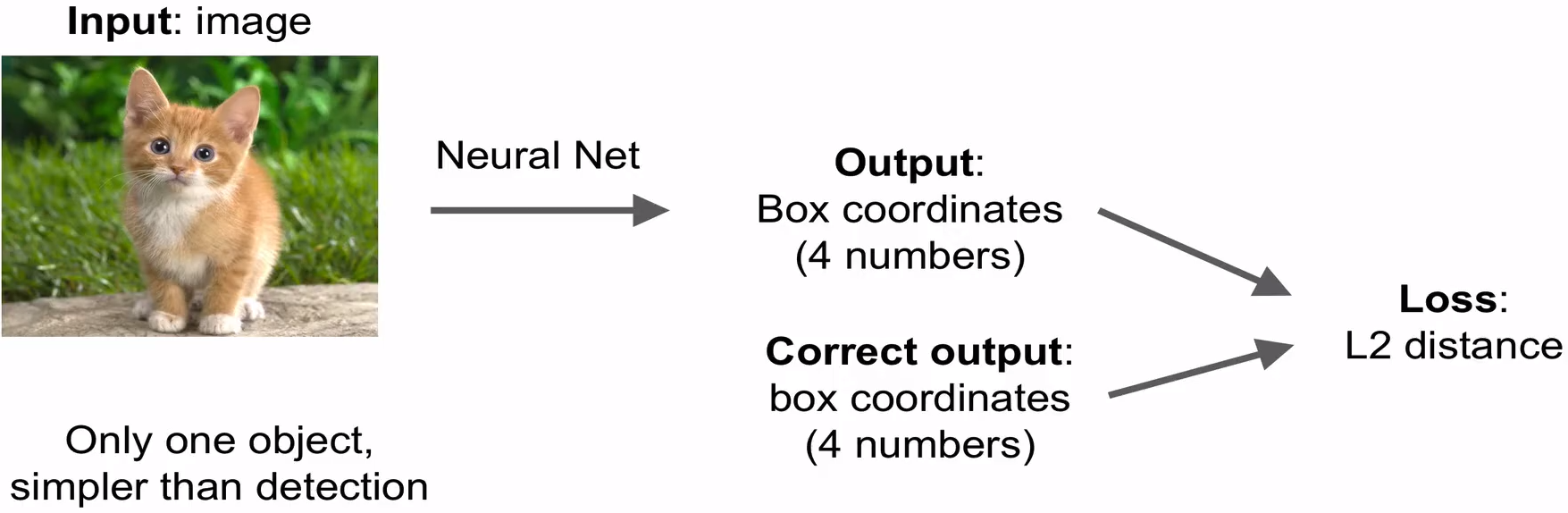
좀 전에 추가시킨 Regression head만 훈련시킴
-
Loss : L2 Distance
-
이때 훈련도 Regression때 처럼 하면됨
-
-
Test 할 때는 Classification head와 Regression head를 모두 이용해서 결과물을 산출함
-
-
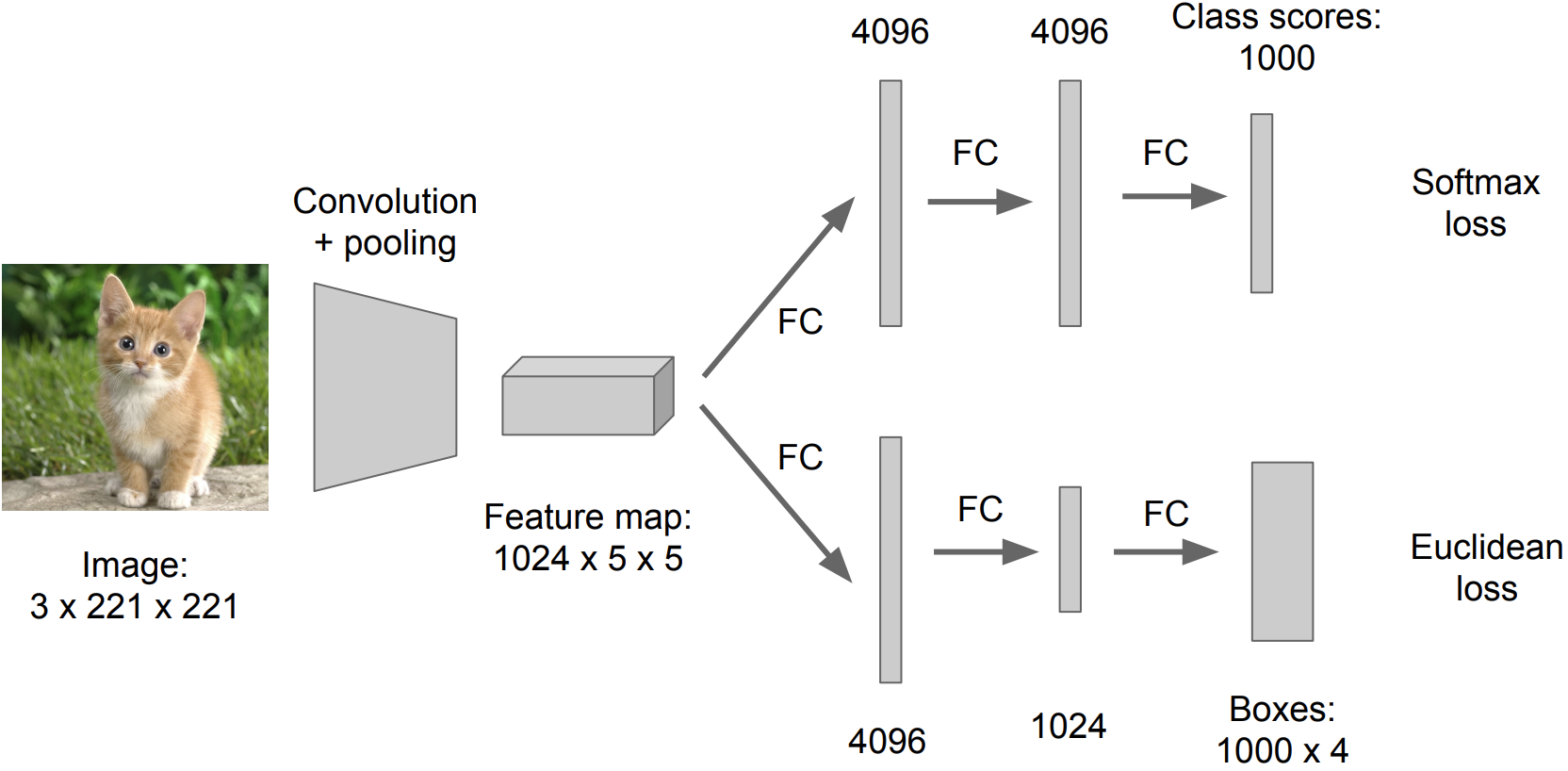
Regression head는 Model의 어디에다 붙일까?
-
마지막 Convolution layer 뒤에다가 붙임
- Overfeat, VGG 인 경우
-
Fully connected layer 뒤에 붙임
- DeepPose, R-CNN 인 경우
-
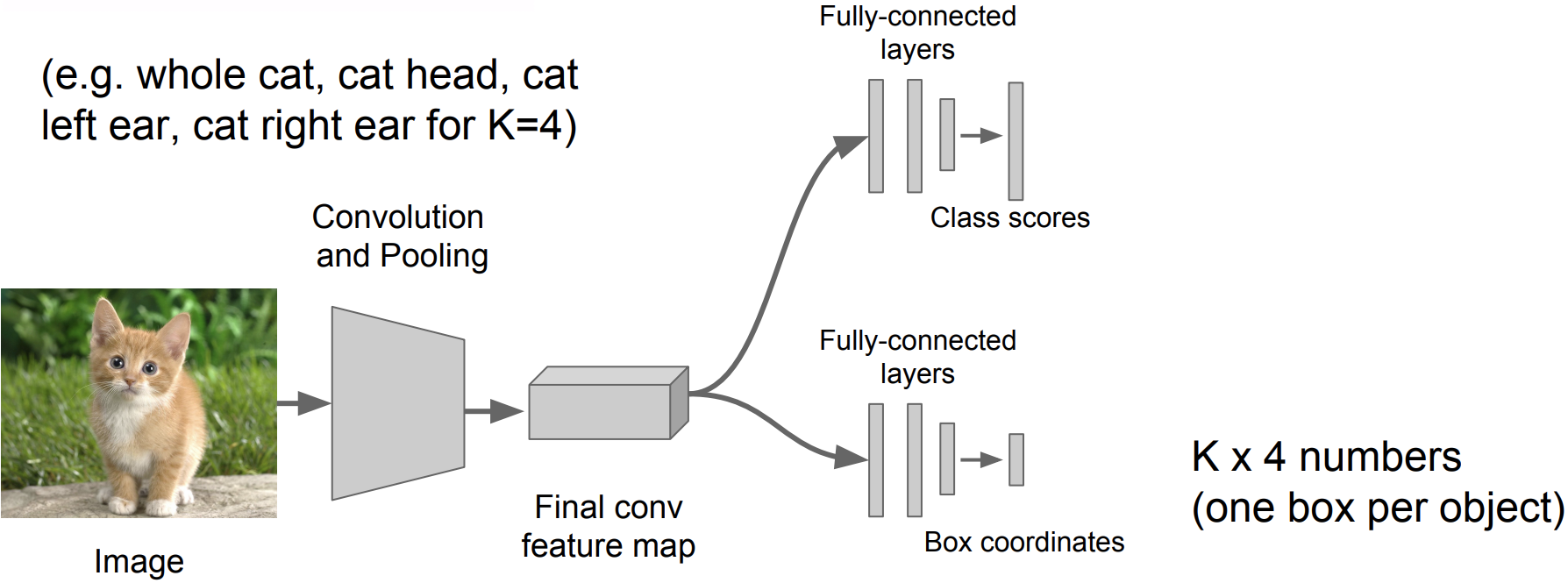
정해진 수의 Object를 Localizing 하는 것은 이 방법으로도 충분히 잘 동작됨
-
구지 Detection을 사용하지 않아도 Regression방법을 사용해 Simple하게 구현할 수 있음
-
-
사람의 자세를 평가해서 관절을 표시해주는 것도 Regression방법을 사용해 쉽게 구현할 수 있음
-
관절의 수는 정해져 있기 때문에
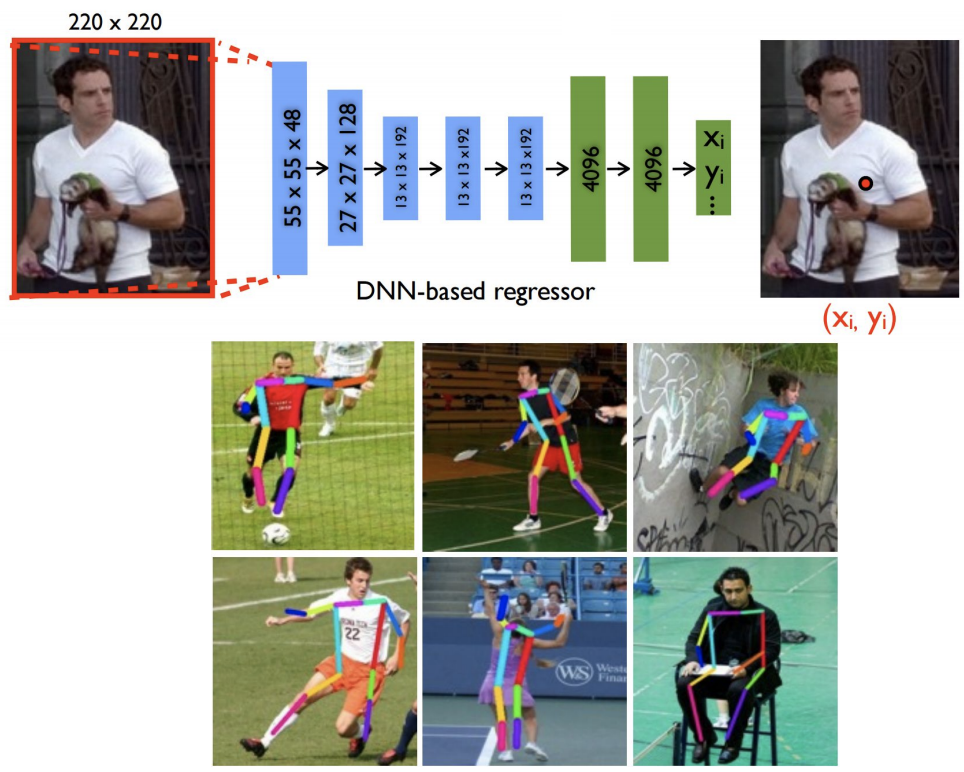
-
Sliding Window
-
특징 :
-
여전히 Classification head와 Regression head로 분리해서 진행하지만, 이미지 한번만 돌리지 않고 이미지의 여러군데의 위치에 여러번을 돌리고 그리고 나서 합쳐주는 기법
-
편의성을 위해서 Fully connected layer를 Convolution layer로 변환해 줘서 연산을 진행
-
-
대표작 : Overfeat
-
구조 :
-
좀 더 큰 size의 input 이미지로 진행하는게 도움이 됨
-
동작과정 :
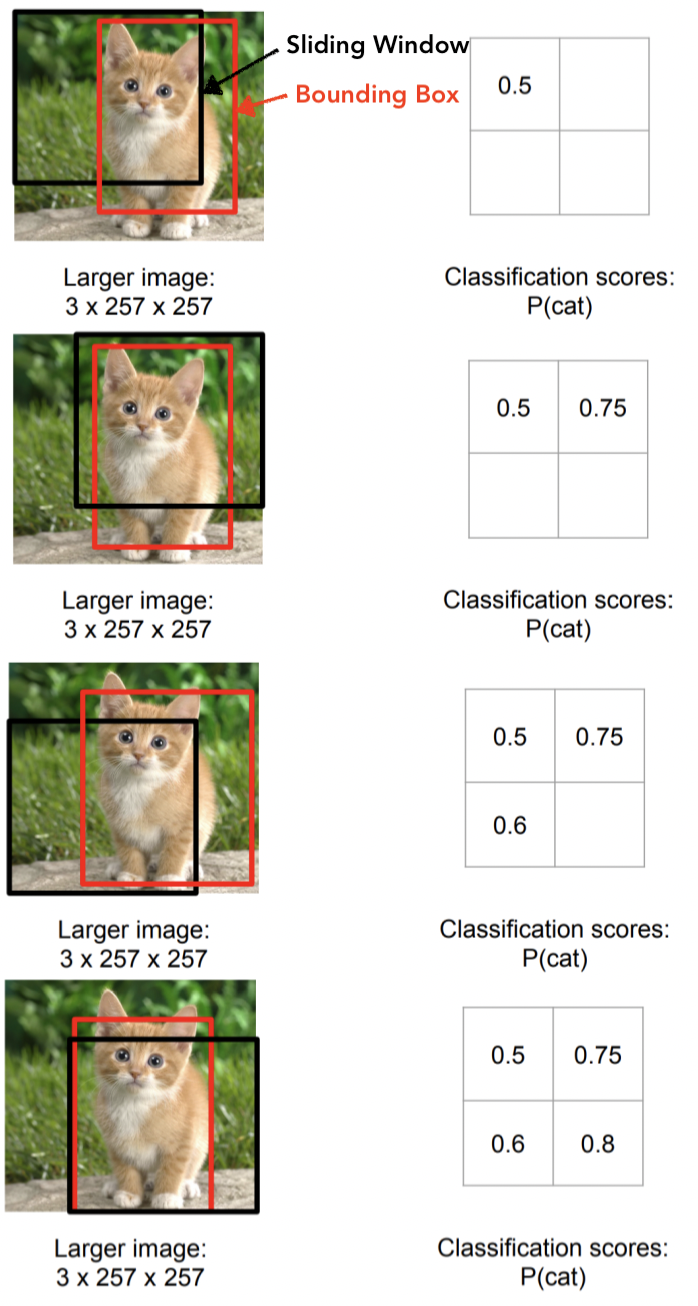
💁🏻 매번 Sliding Window를 이동하면 Regression head에 의해서 Bounding box를 만들고 Classification head에 의해서 고양이로 분류하는 score를 계산함
💁🏻 최종적으로 이동한 횟수 만큼의 Bounding box와 score를 얻어서 합침

-
실제로는 훨씬 더 많은 Sliding Window를 사용함
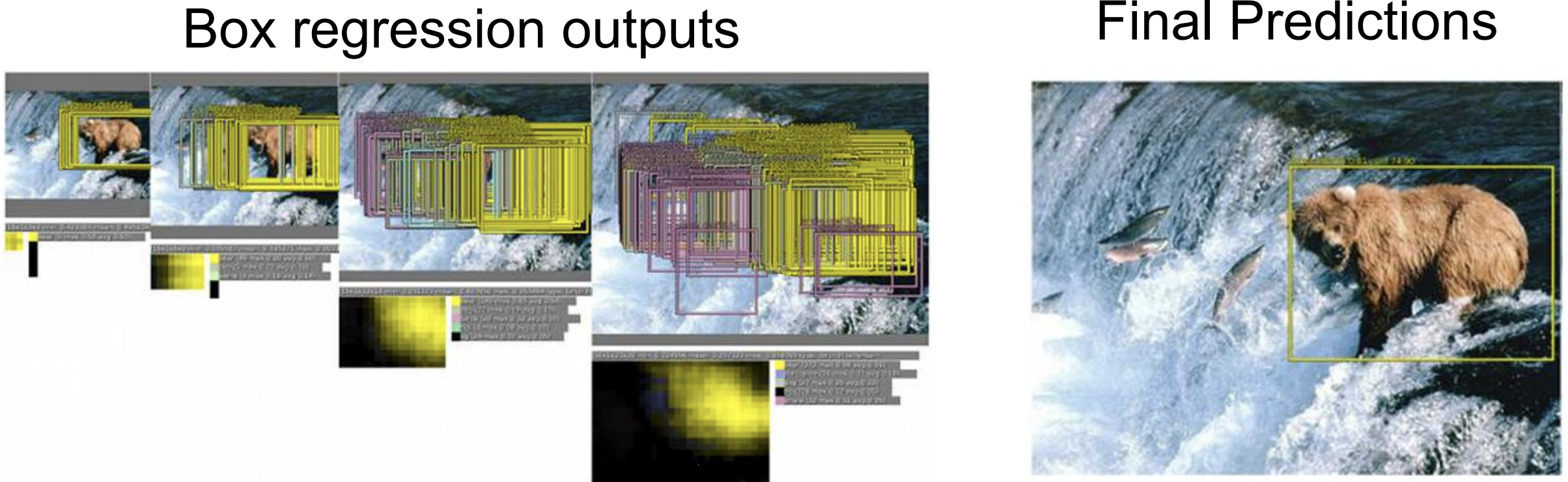
-
Network를 돌릴때 이렇게 수많은 Sliding Window을 사용하게 되면 연산이 너무 heavy해짐
-
그래서 효율적으로 Network를 돌리기 위해 Fully connected layer대신 Convolution layer로 변환
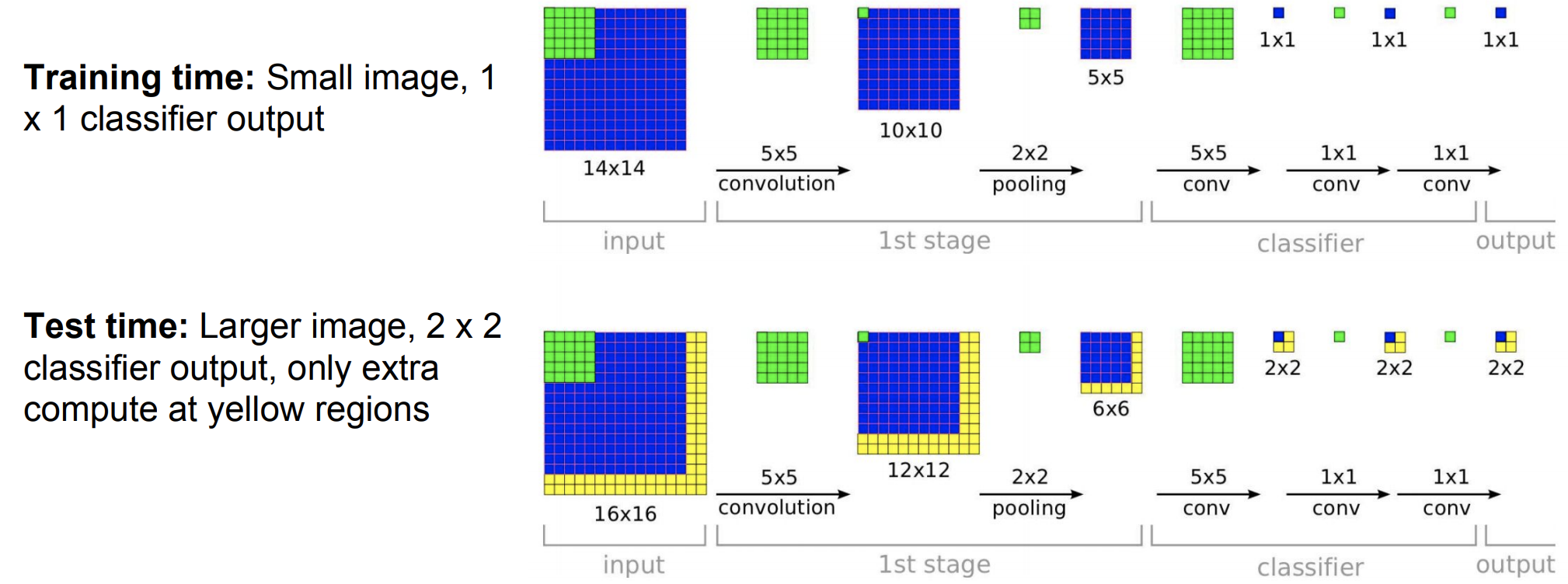
-
-
Object Detection
- 이미지에 따라서 Object의 개수가 달라지기 때문에 결국 Output의 개수가 달라짐 👉 Regression이 적합하지 않음!
- YOLO : Regression를 사용해서 Detection을 함
Detection as Classification
-
Black box 영역을 보고 Classification를 하는 것

👉 이렇게 해서 Output의 개수가 달라지는 것을 해결하겠다는 접근 방법
-
문제점1 : 많은 Black box window들에 대해서 test를 해야됨
-
해결방안 : 빠른 classifier로 그냥 돌려라
-
Histogram of Oriented Gradients (HOG)
- 다양한 resolution을 가지는 이미지들에 대해서 linear classifier를 돌린다
- linear classifier는 매우 빠르기 때문에 최대한 다양한 해상도와 영역에 돌려보는 방법
-
Deformable Parts Model (DPM)
-
HOG의 후속 연구
-
부분에 대한 template들을 가지고 있음
-
-
-
-
문제점2 : 무거운 classifier를 사용 할 경우, 이미지의 모든 영역을 보기에는 연산이 너무 heavy 함
-
해결방안 : 전 영역을 보지말고 의심되는 영역을 보게하자
-
Region Proposal

-
어떤 object를 포함하고 있을꺼 같은 이미지의 영역을 찾아내는 것
-
유사한 색이나 유사한 텍스쳐를 가지고 있는 영역을 찾는게 목적임 됨
-
장점 : 매우 빠르게 실행됨
-
Region Proposal 방식 : Selective Search
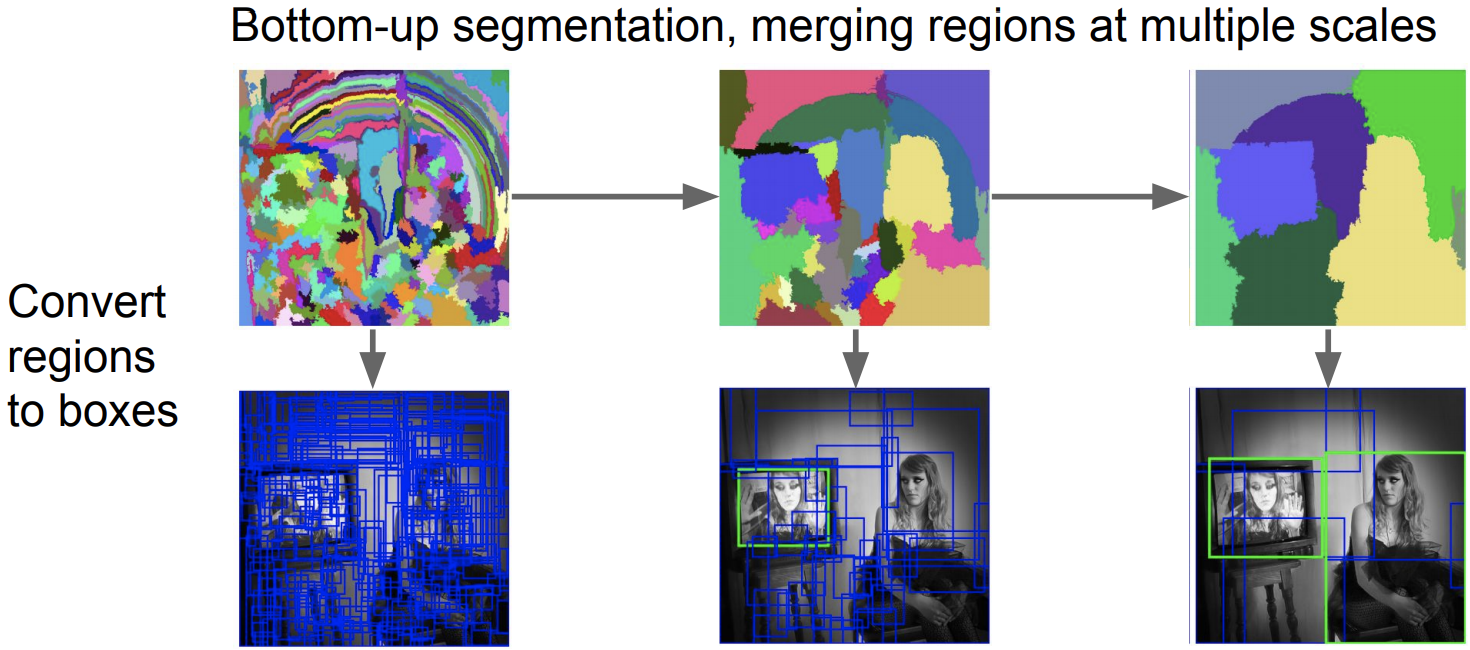
- 이미지의 pixel로 부터 시작하여 색상이나 텍스쳐가 유사한 pixel들 끼리 묶어줌
- 어떤 알고리즘을 사용해서 작은 묶음들을 좀 더 크게 묶어줌
- 최종적으로 box들이 나오게 됨
-
다른 Region Proposal 방식들
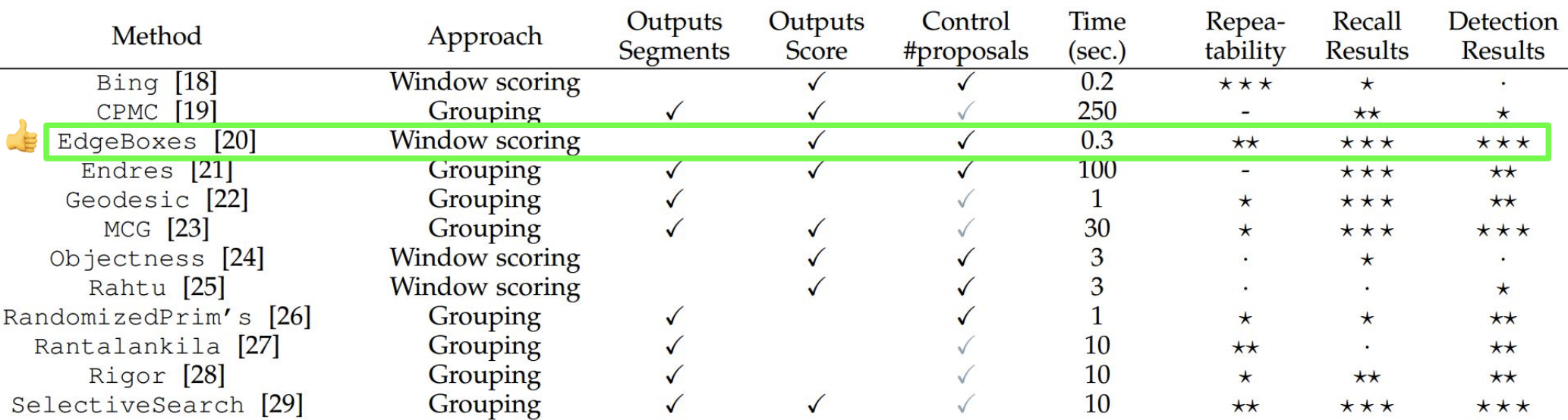
-
-
-
R-CNN (Region-based CNN)
-
Region Proposal + CNN = R-CNN
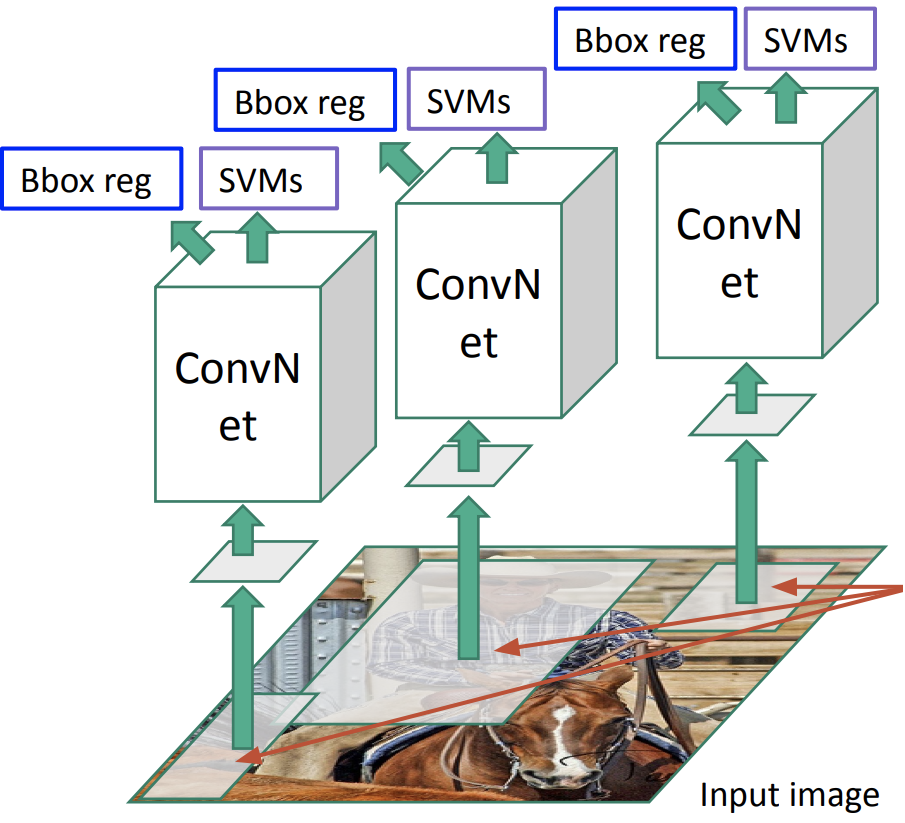
-
R-CNN 훈련 과정
-
ImageNet 데이터 셋으로 훈련된 Checkpoint를 가져옴
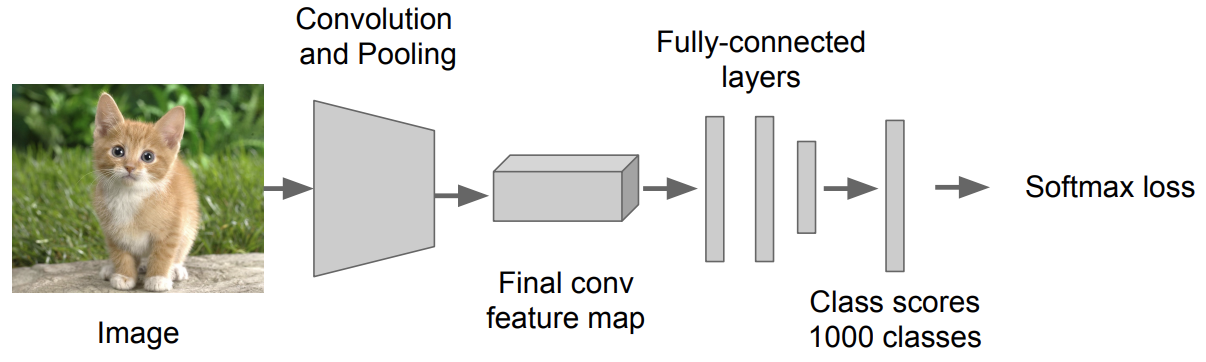
- ImageNet Dataset : 1000개의 class를 지님
-
21개의 class에 대한 예측을 할 수 있게 layer를 대체를 해줌
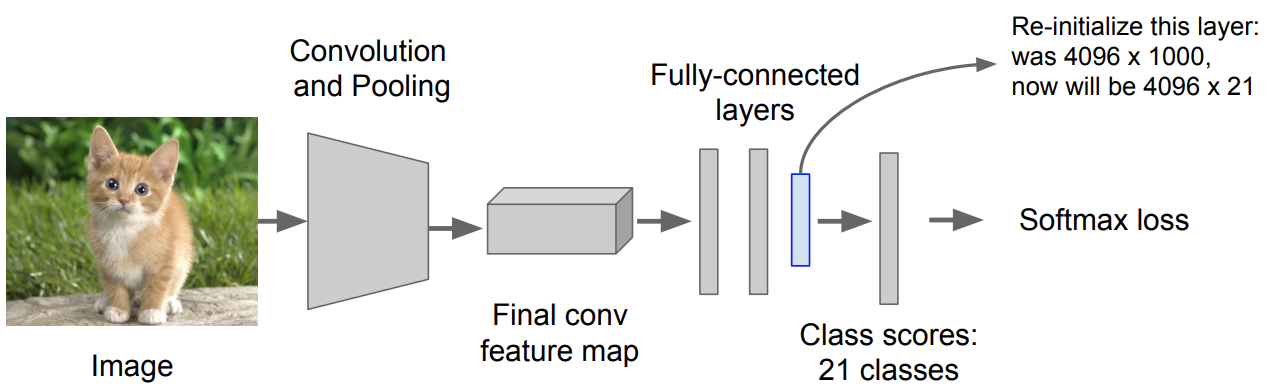
- 그리고 이후 이 모델은 이미지 전체에 대해 진행하는 것이 아니라 Positive / Negative region를 이용해서 training 모델을 유지해나감 (4번 단계에서 확인 할 수 있음)
-
Region Proposal를 추출해냄 (약 2000개) 그리고 각각의 Region에 대해서 CNN의 Input으로 들어갈 수 있는 Size에 맞게 warp함
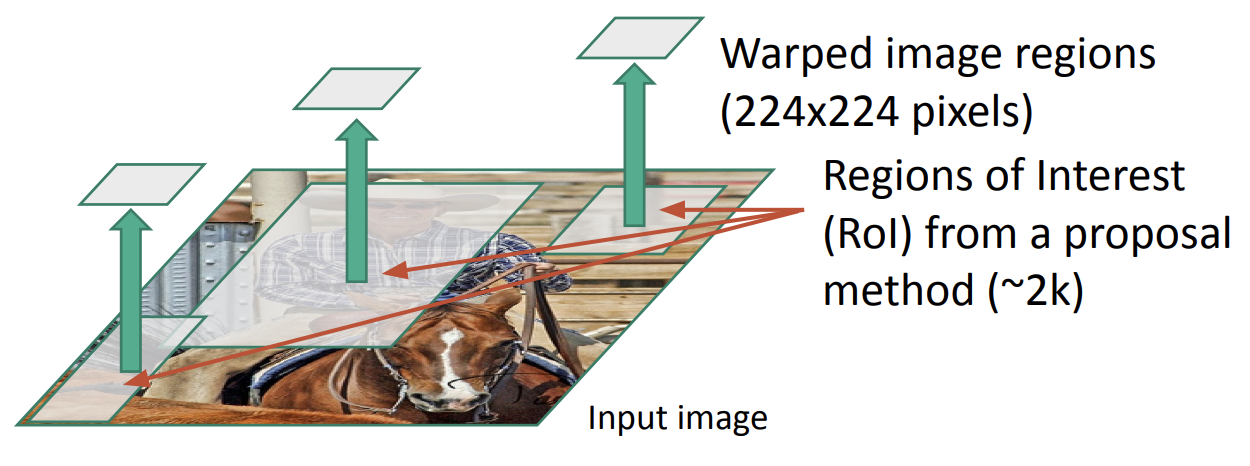
-
Warp한 Region Proposal를 이제 CNN에 돌림 그리고 AlexNet의 5번째 Pooling layer의 feature(Activation map)를 disk에 저장
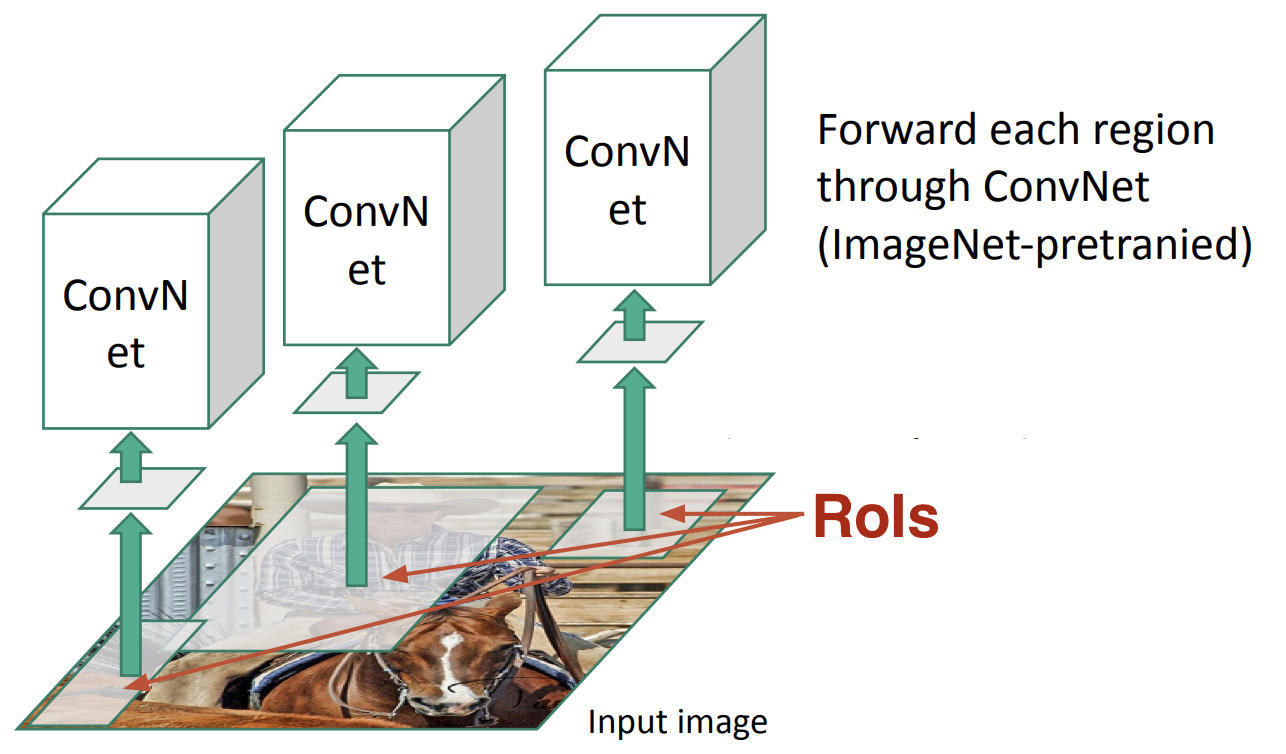
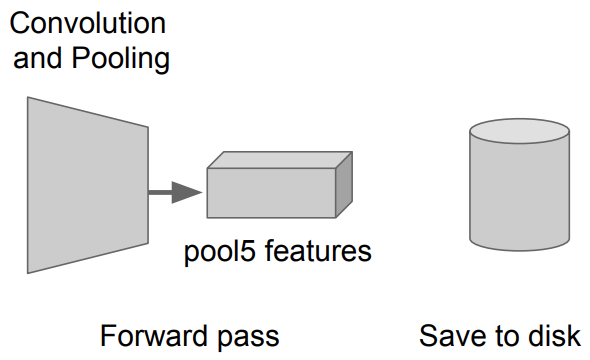
- disk의 size가 약 200GB 정도 필요함
-
Class 당 하나의 binary SVM을 이용해서 각 feature들을 classify하는 작업을 함
-
Example. Dog class 에 대한 binary SVM
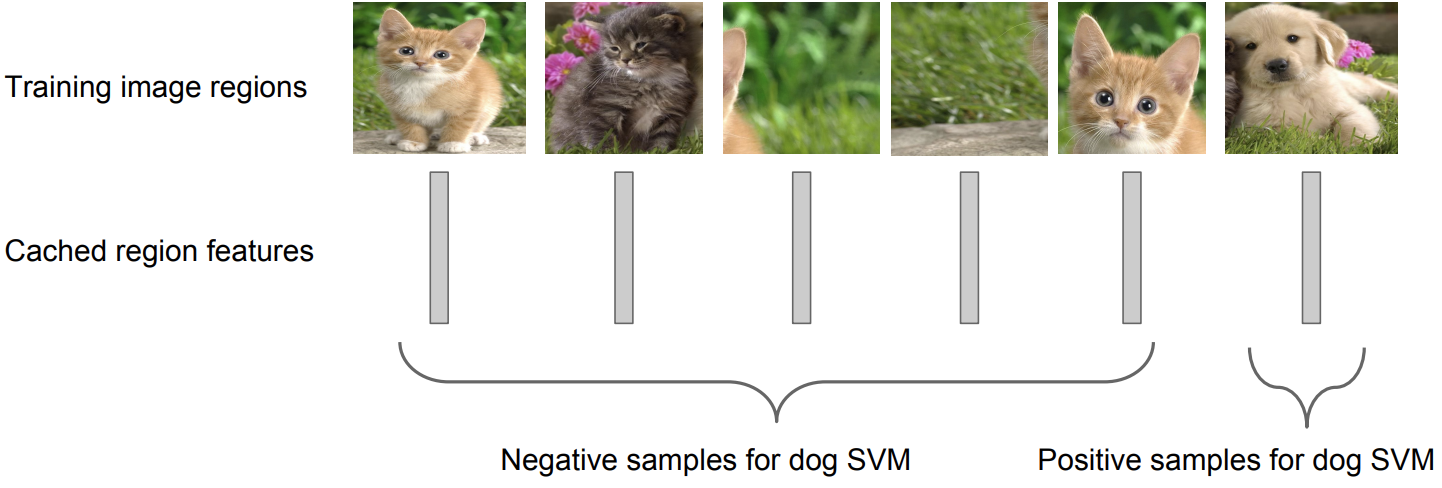
-
-
저장해논 feature로 부터의 regression을 이용해서 Region Proposal의 정확도를 높혀줌
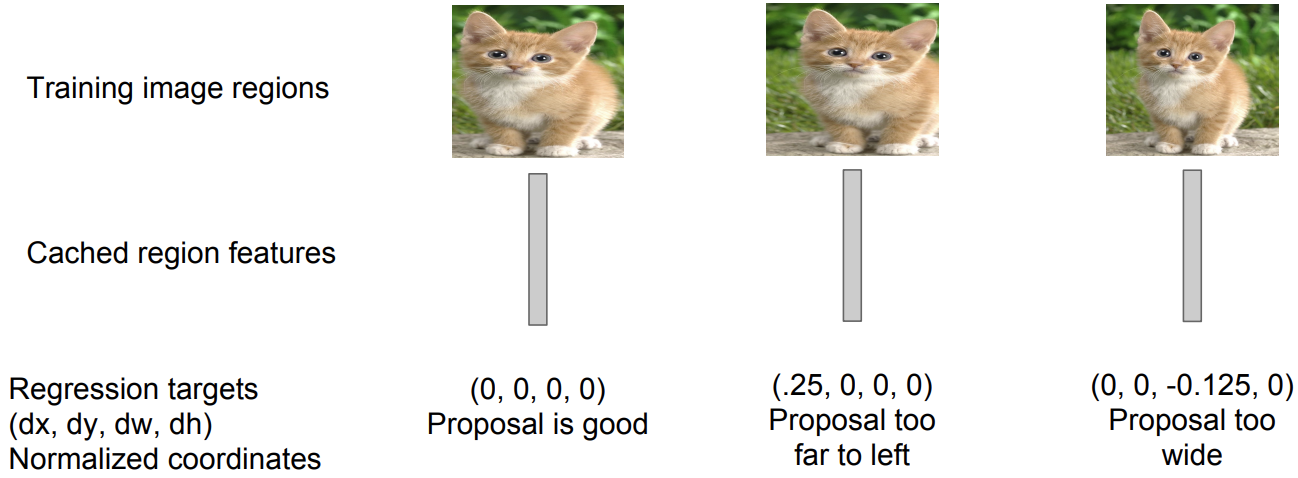
- 왼쪽 box는 잘 쳐짐
- 중간 box는 너무 왼쪽으로 처침 그래서 x 좌표를 추가해서 보정
- 오른쪽 box는 width를 넓게 잡아서 w 좌표를 추가해서 보정
-
-
R-CNN의 문제점
-
Test (runtime)할 때, 약 2000개의 Region Proposal에 대해서 CNN을 돌려야됨. 그래서 굉장히 느림
-
SVM와 regressor의 반응에 기반하여서 바로바로 업데이트할 수 없음
-
다단계의 훈련 단계를 가짐
-
Fast R-CNN
-
R-CNN과 반대로 CNN를 먼저 돌린 다음 Region를 추출함
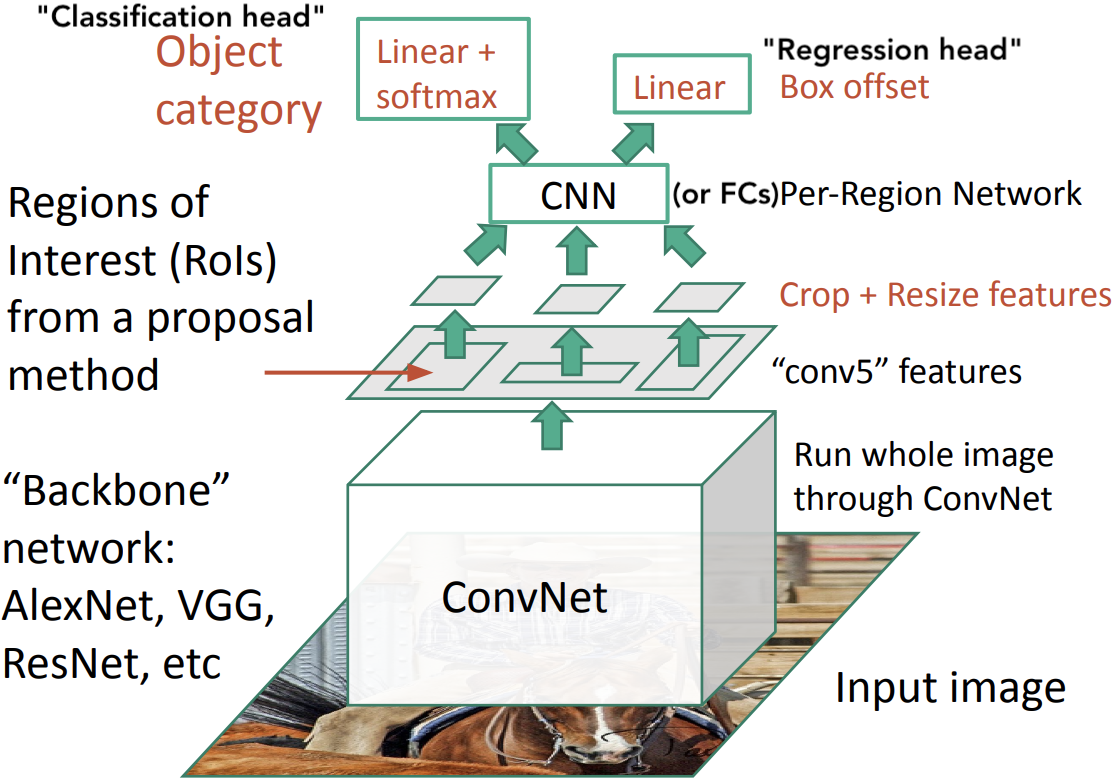
-
Test(runtime)할 때, input image에서 처음에 ConvNet 연산을 공유함으로 R-CNN보다 빠르게 동작할 수 있음
-
Train할 때, 전체 시스템을 End-to-end로 학습시킬 수 있어 편리해짐
-
RoI Pooling :
-
Based on Spatial Pyramid Pooling(SPP) (He at el. 2015)
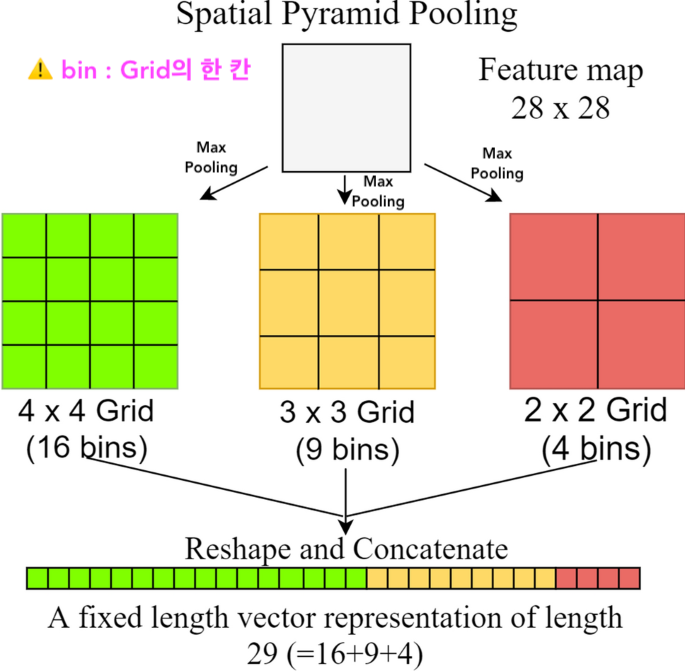
-
Input이미지의 크기에 관계 없이 Conv. layer들을 통과시키고, FC layer 통과 전에 Activation map(= feature map)들을 동일한 크기로 조절해주는 pooling을 적용
-
먼저 이미지를 CNN에 통과시켜 feature map을 추출하고 max pooling을 적용하여 각 4x4, 2x2, 1x1크기의 output 결과를 뽑아낸다. 각 피라미드 별로 뽑아낸 max값들을 쭉 이어붙여 고정된 크기 vector를 만들고 이게 FC layer의 input으로 들어간다.

-
-
RoI Pooling 과정
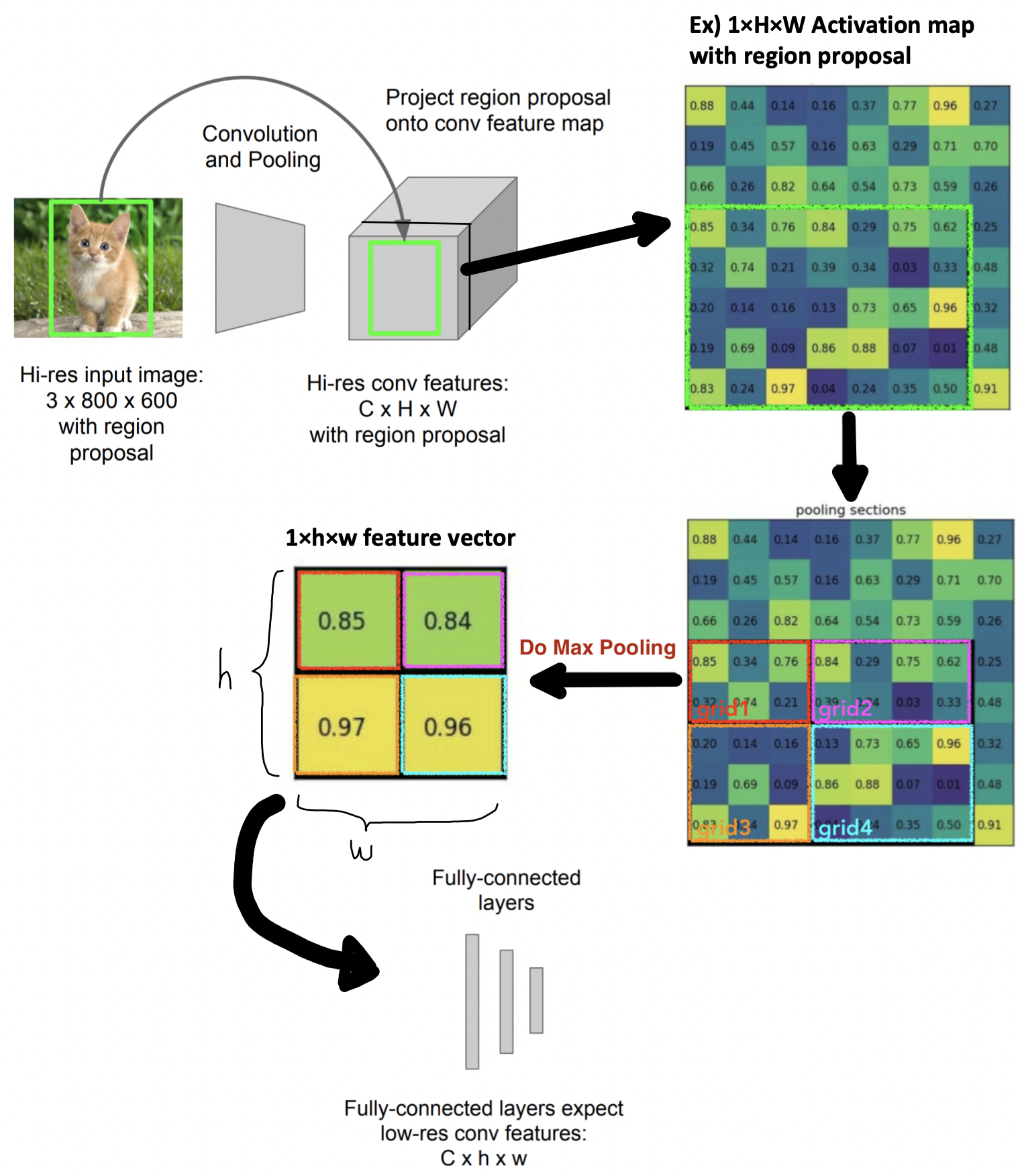
-
먼저 input 이미지는 ConvNet을 통과하여 Activation map을 추출
-
이전에 미리 Selective search로 만들어놨던 region proposal을 Activation map에 투영시킨다
-
미리 정해놓은 grid크기로 투영된 region proposal 를 split함
-
각 grid 칸마다 max pooling을 적용시켜 하나의 값을 추출함
- RoI pooling을 이용함으로써 원래 input 이미지를 ConvNet 에 통과시킨 후 나온 Activation map에 이전에 생성한 RoI를 projection시키고 이 RoI를 FC layer input 크기에 맞게 고정된 크기로 변형할 수가 있다
- Max pooling의 장점 : Backpropagation할 때 문제가 없음, 그래서 End-to-End 훈련이 원할하게 진행할 수 있음
-
-
R-CNN과 차이점
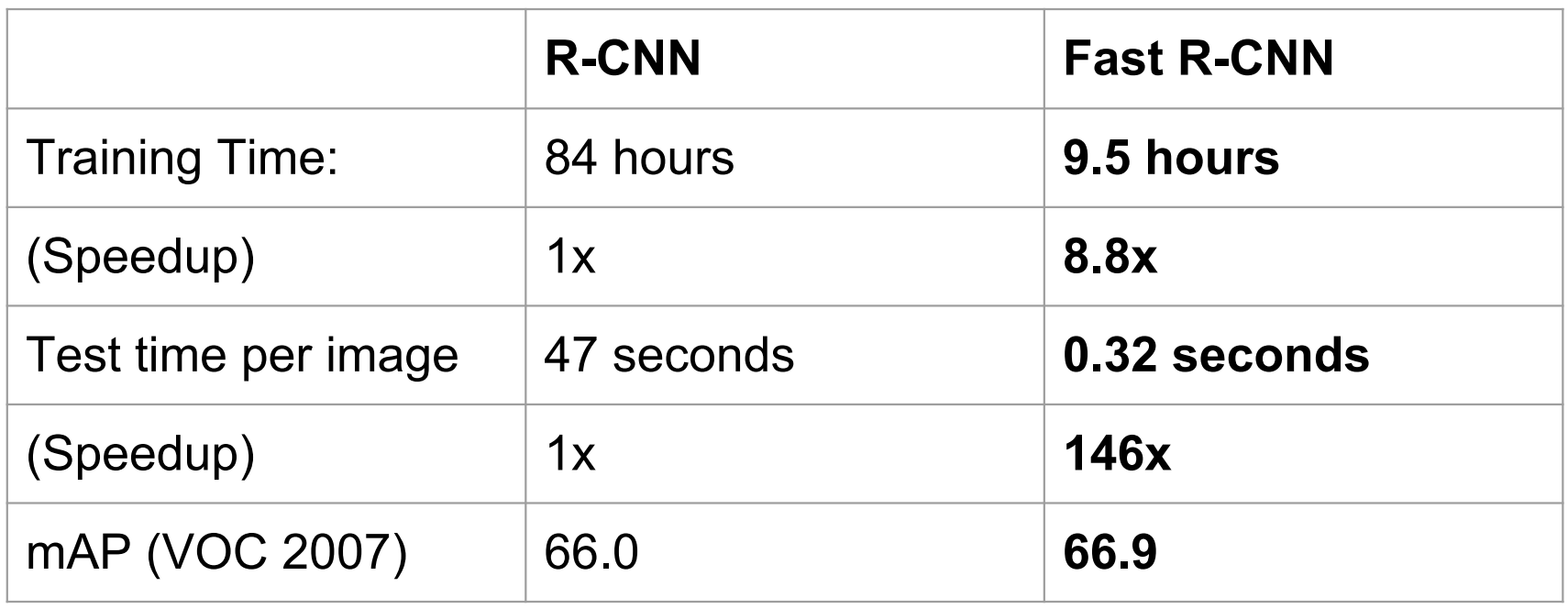
-
Fast R-CNN의 문제점
- 1개 이미지 마다 Selective search 가 포함되지 않은 test time은 0.32초가 걸렸지만 Selective search 가 포함된 test time은 2초가 걸림. 그래서 실시간 detection으로 사용하긴 힘듬
Faster R-CNN
-
Idea : 우린 CNN을 사용해서 Regression도 했고 Classification도 했으니깐 region proposal에도 CNN을 적용해보면 어떰?!
-
Fast R-CNN + Region Proposal Network (RPN) = Faster R-CNN
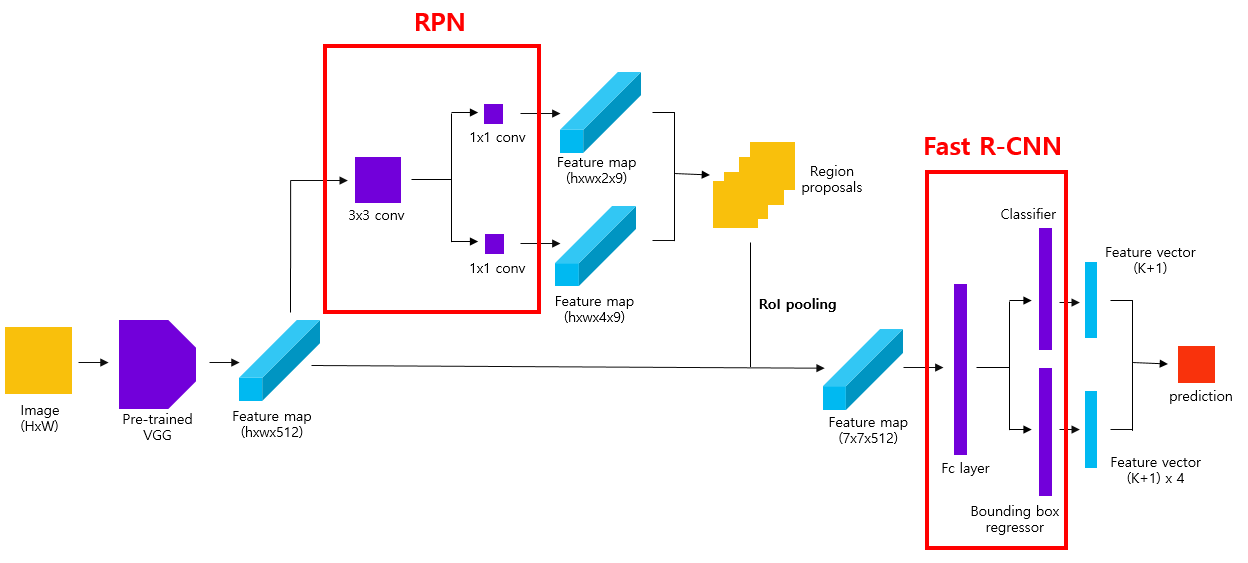
- RPN도 CNN 구조
- RPN 이후에 과정들은 Fast R-CNN의 과정과 동일하게 진행
-
Region Proposal Network (RPN)
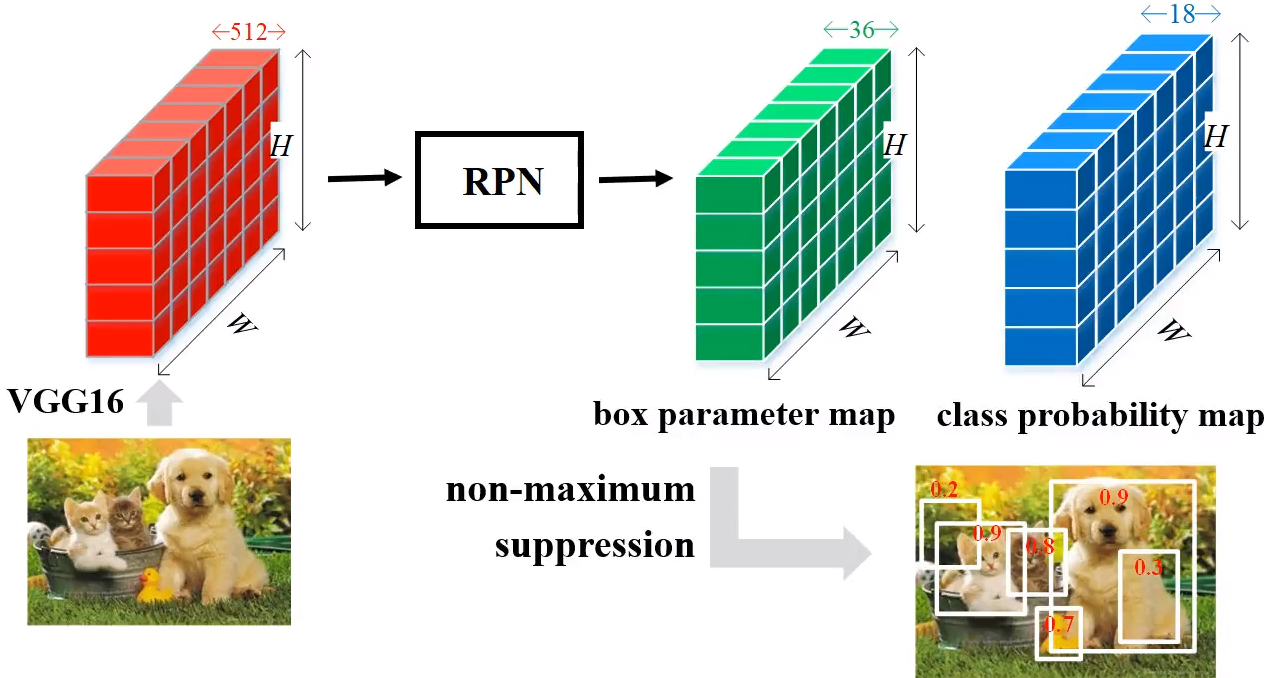
-
RPN : 원본 이미지에서 region proposals를 추출하는 네트워크
- 원본 이미지에서 anchor box를 생성하면 수많은 region proposals가 만들어짐
- RPN은 region proposals에 대하여 class score를 매기고, bounding box coefficient를 출력하는 기능을 함
- RPN의 input은 image의 Feature Map이고, output은 Object proposal들의 Sample
-
Anchor :
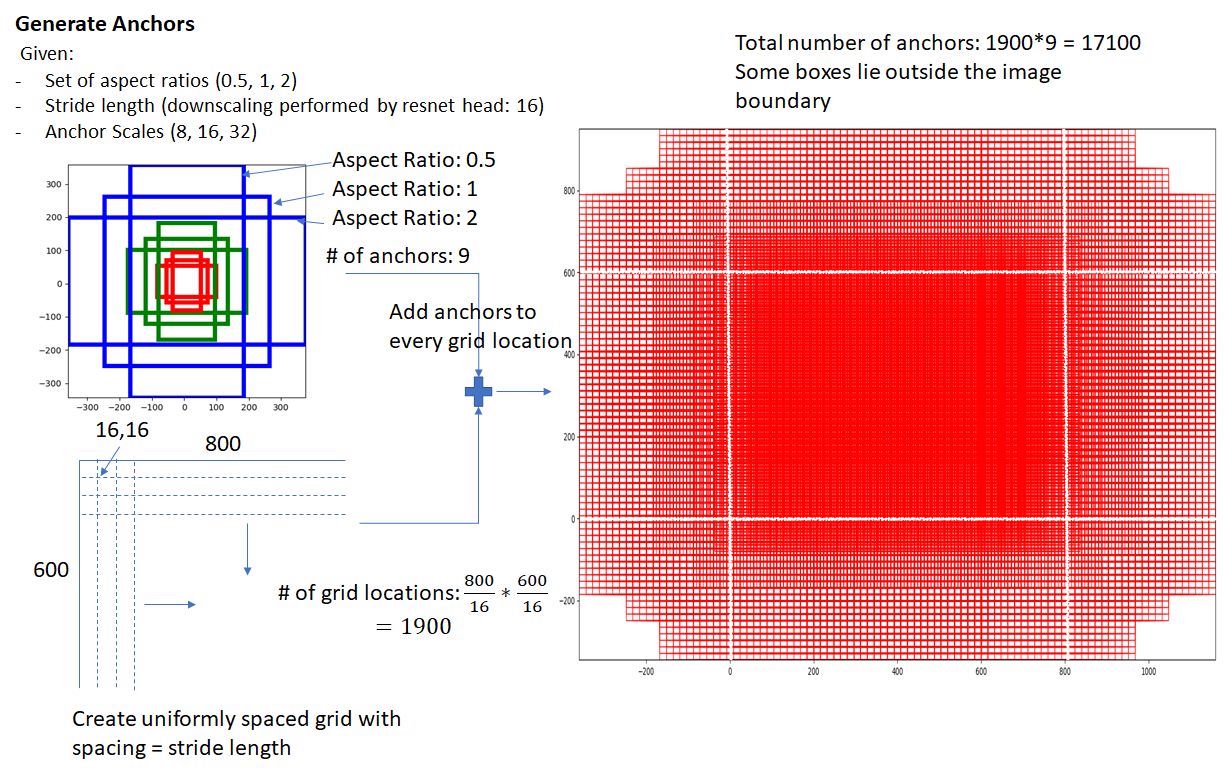
- sliding window의 각 위치에서 Bounding Box의 후보로 사용되는 상자
- Feature map에 Sliding window 방법으로 각 중심 좌표를 중심으로 k=9개의 Anchor box들을 만들어 놓음
-
RPN 동작 과정 :
-
원본 이미지를 pre-trained된 VGG 모델에 입력하여 feature map을 얻음
-
얻은 feature map에 대하여 3x3 conv 연산을 적용합니다.
(이때 feature map의 크기가 유지될 수 있도록 padding을 추가)
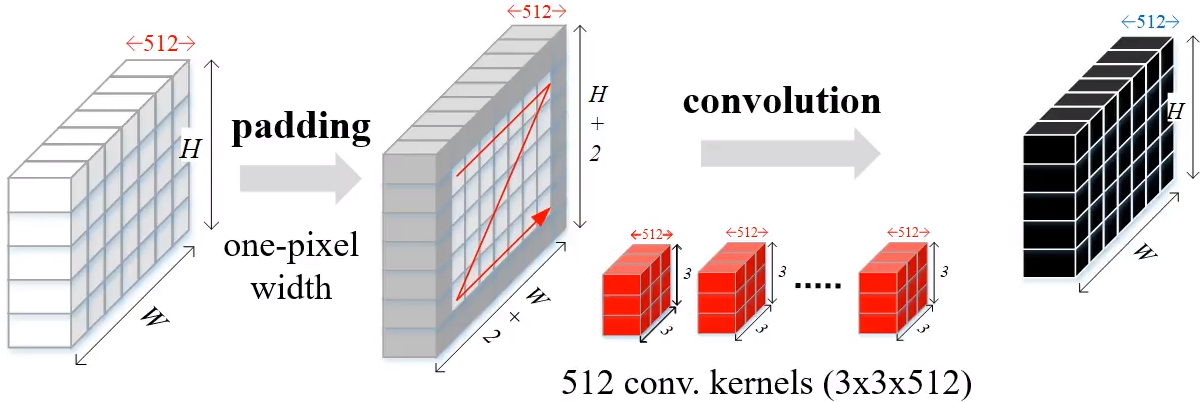
-
2가지 output
 이 Feature Map을 k개의 Anchor box를 통해 영역을 정하고 class 확률을 매기기 위해서 feature map에 대하여 1x1 conv 연산을 적용
이 Feature Map을 k개의 Anchor box를 통해 영역을 정하고 class 확률을 매기기 위해서 feature map에 대하여 1x1 conv 연산을 적용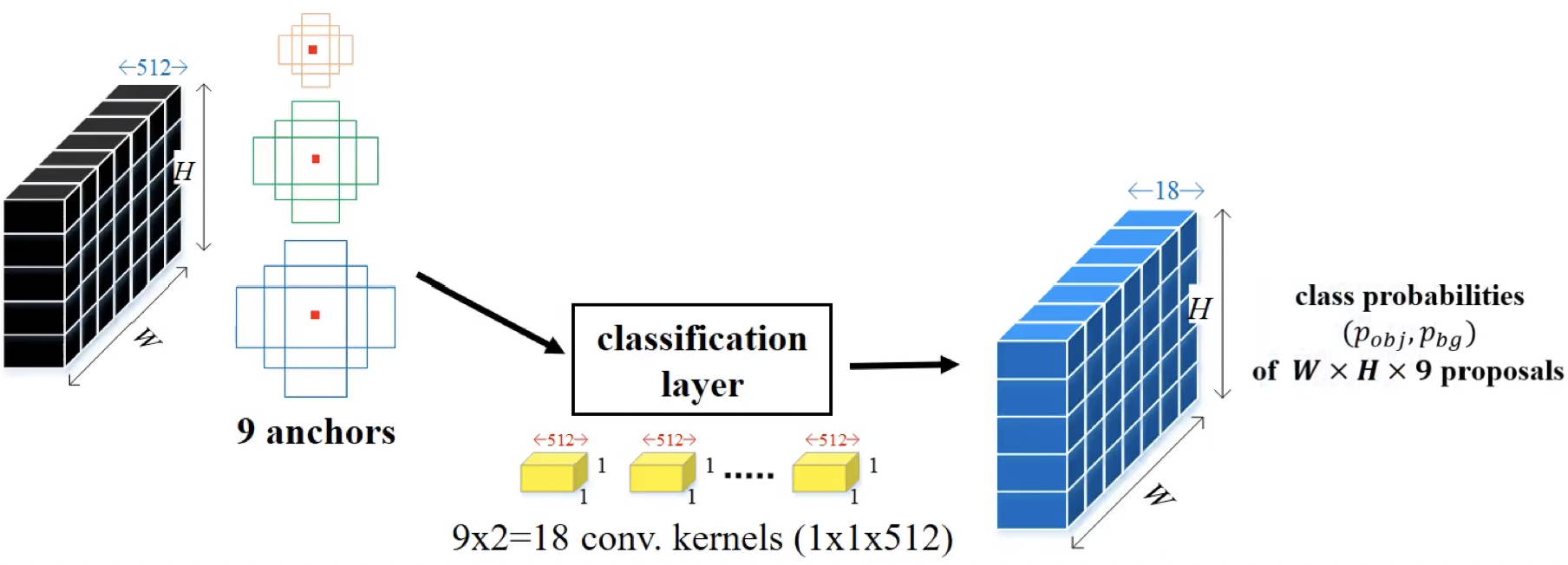
- 이 때 출력하는 feature map의 channel 수 = 2 k (즉 1x1 filter 개수)
- 2 : 후보 영역이 배경일 확률과 객체가 포함되어 있는 여부에 대한 확률
- k : 각 grid cell마다 anchor box k개
bounding box regressor를 얻기 위해 feature map에 대하여 1x1 conv 연산을 적용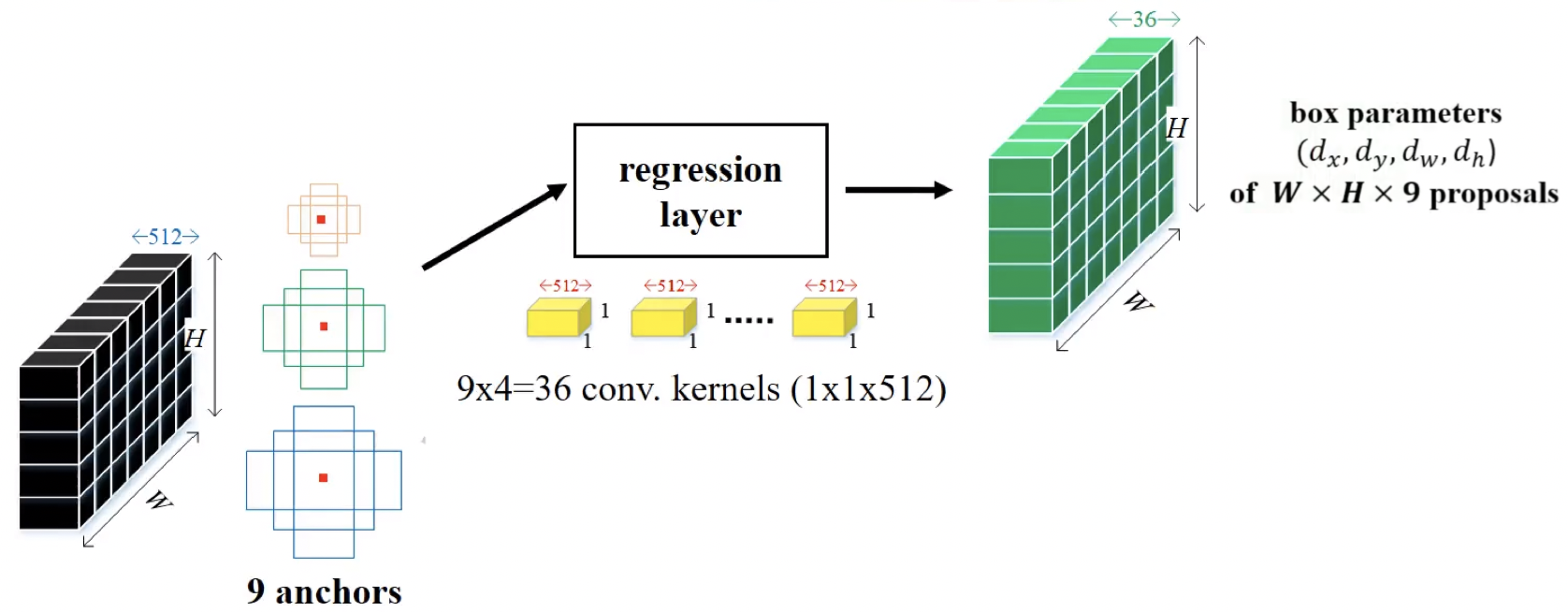
- 이 때 출력하는 feature map의 channel 수 = 4 k (즉 1x1 filter 개수)
-
4 :
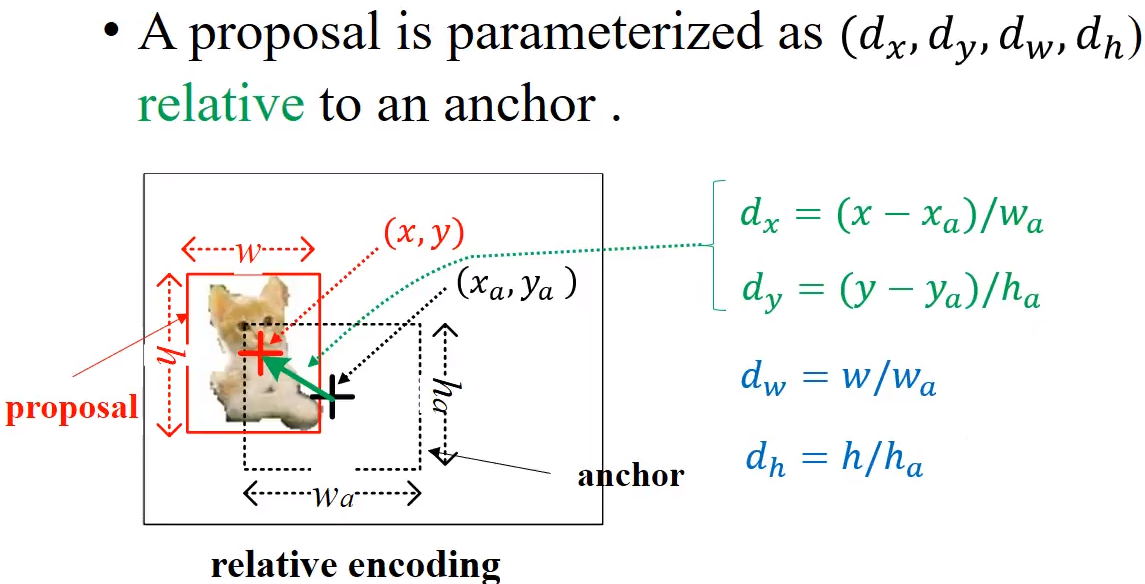
- k : 각 grid cell마다 anchor box k개
-
4 :
- 이 때 출력하는 feature map의 channel 수 = 2 k (즉 1x1 filter 개수)
-
-
NMS (non-maximum-suppression) :

- Detail : Blog
-
-
Training :
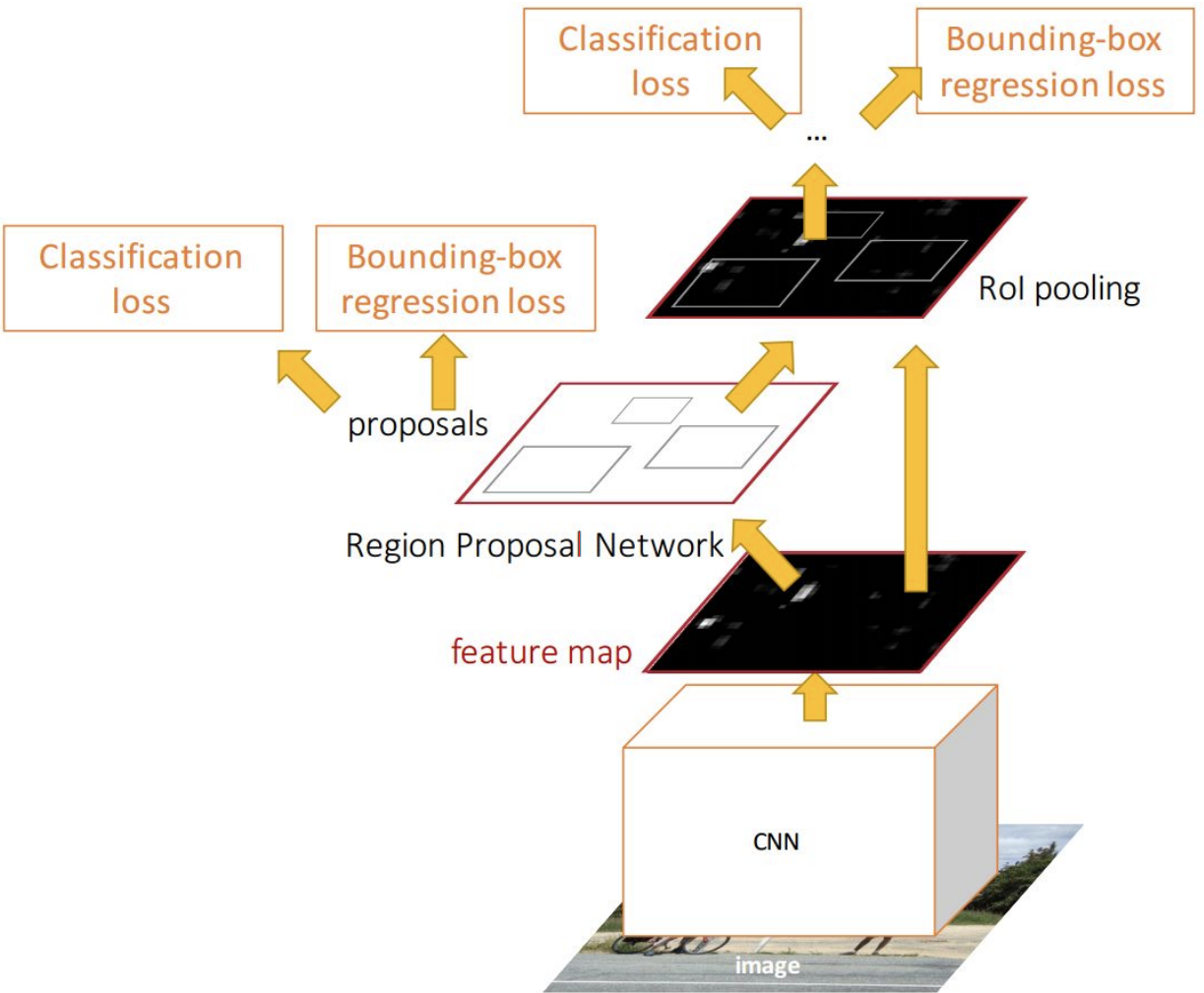
- RPN에서의 Loss
- Classification loss : 각각의 Region Proposal이 Object인지 아닌지
- Bounding box regression loss : Anchor box로 부터의 거리값을 주게됨
- Fast R-CNN에서의 Loss
- Classification loss : 해당 object가 어떤 class 인지
- Bounding box regression loss : Region Proposal상에서 보정
- RPN에서의 Loss
-
Fast R-CNN과 차이점
Detection as Regression
YOLO
- 우선 이미지를 S×S grid로 나눔
- 각각의 grid에서 2가지를 예측함
- 4개의 좌표와 confidence score를 가지는 box B개
- Class score를 나타내는 숫자 C개
- input 이미지로 부터 7×7×(5×B+C) tensor를 output함
- 성능 : 굉장히 빠름(실시간 object detection 가능) , 하지만 Faster R-CNN보다 정확도 떨어짐
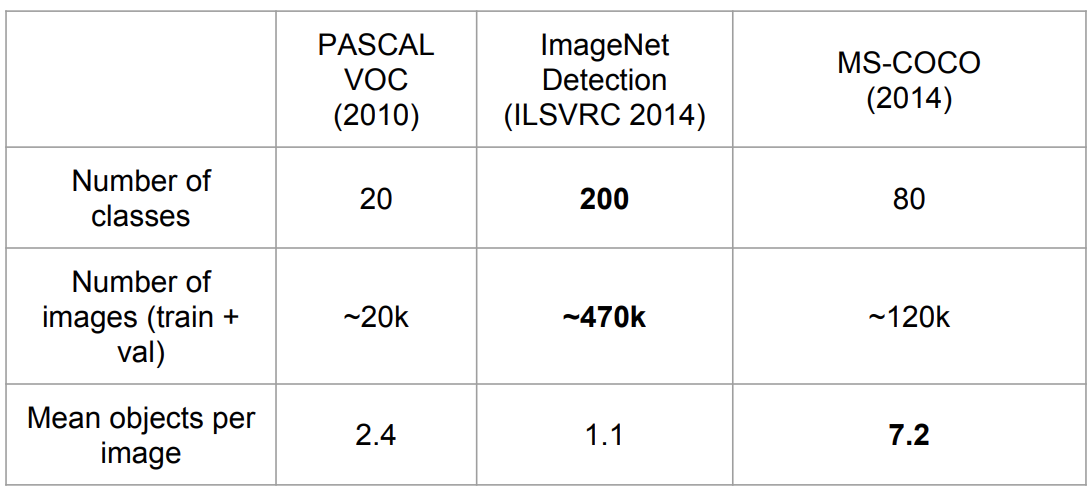
Datasets
Evaluation
- mAP (Mean Average Precision) :
- Detail : Blog
Segmentation
Semantic Segmentation
-
pixel 단위로 labeling을 해줌
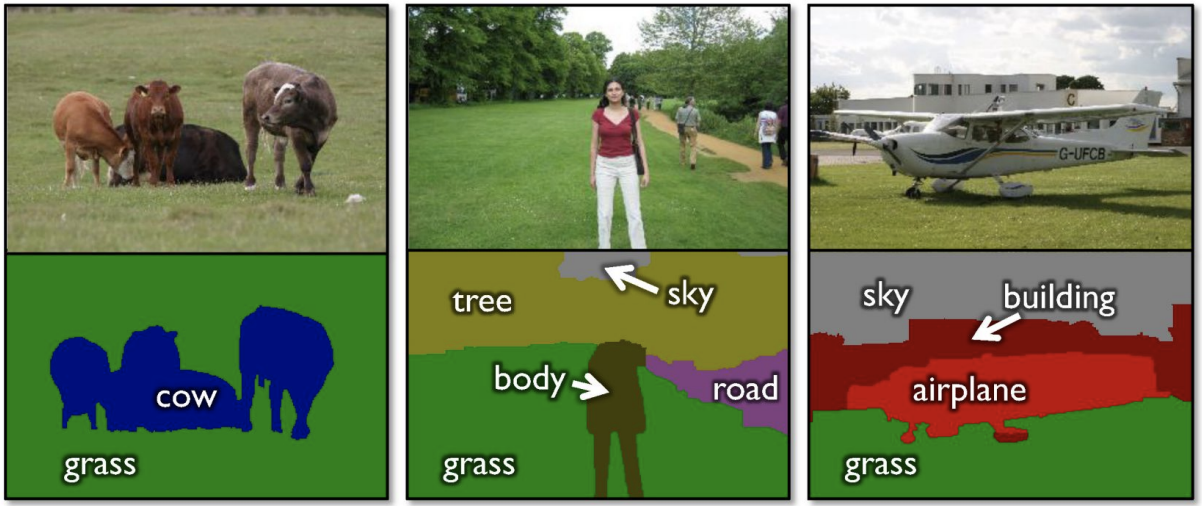
👆 소 4마리의 pixel들을 하나의 소로 인식함
-
과정 pipeline
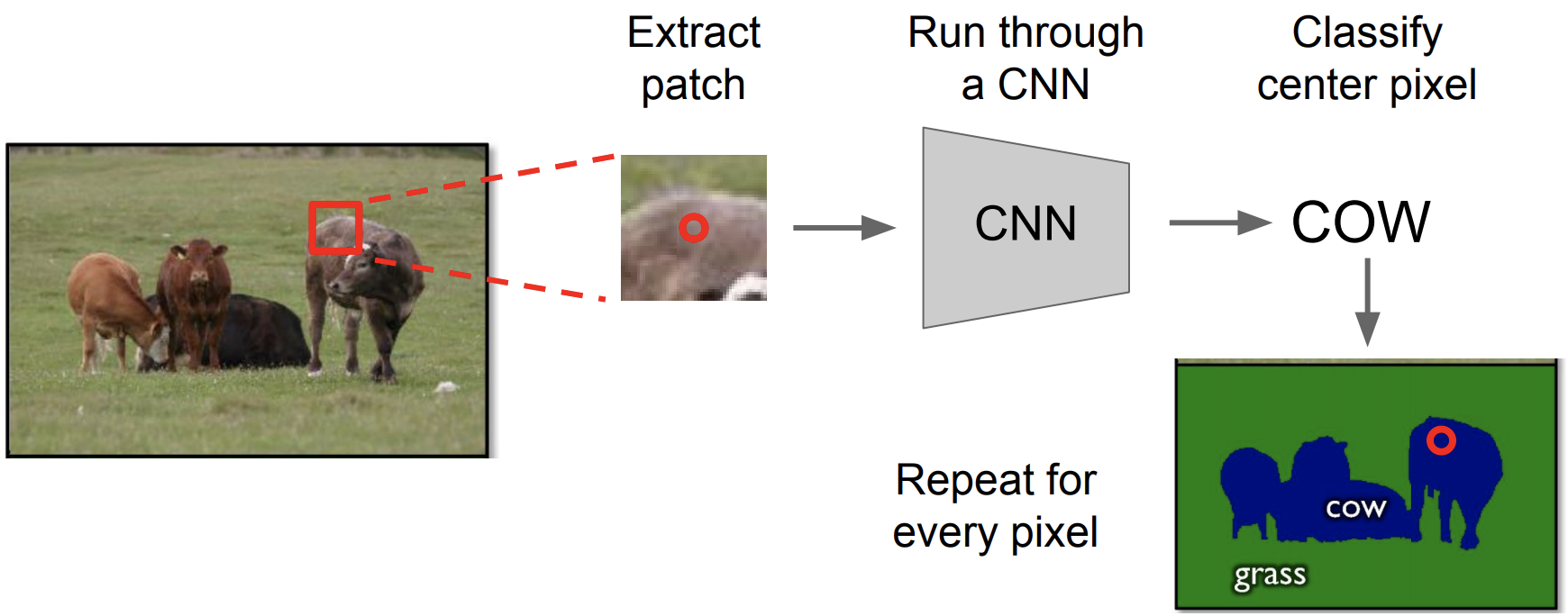
-
연산 비용이 많이 듬
-
그래서 fully connected 대신 fully convolutional network를 사용함
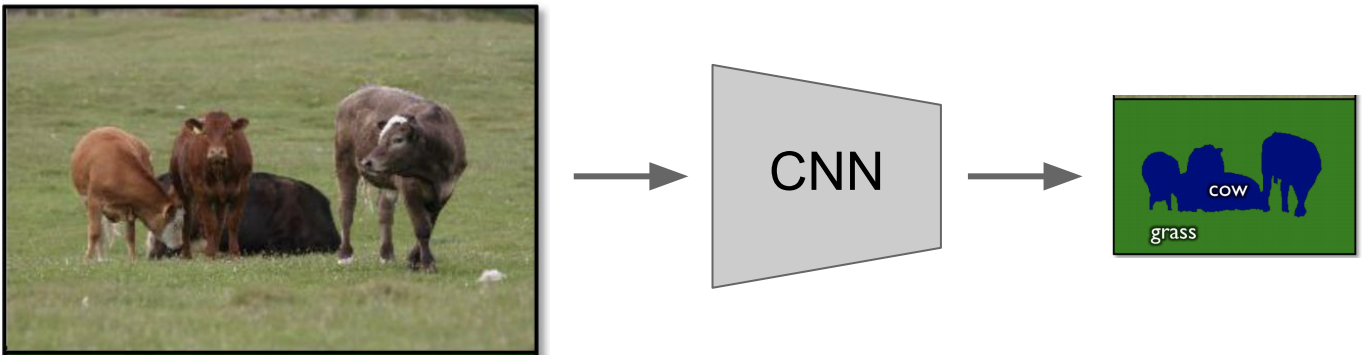
- 이 방식을 이용하면 이미지의 전체를 input으로 넣게 됨
- 하지만 down sampling 으로 인해 output 이미지가 작아지는 문제점이 있음
-
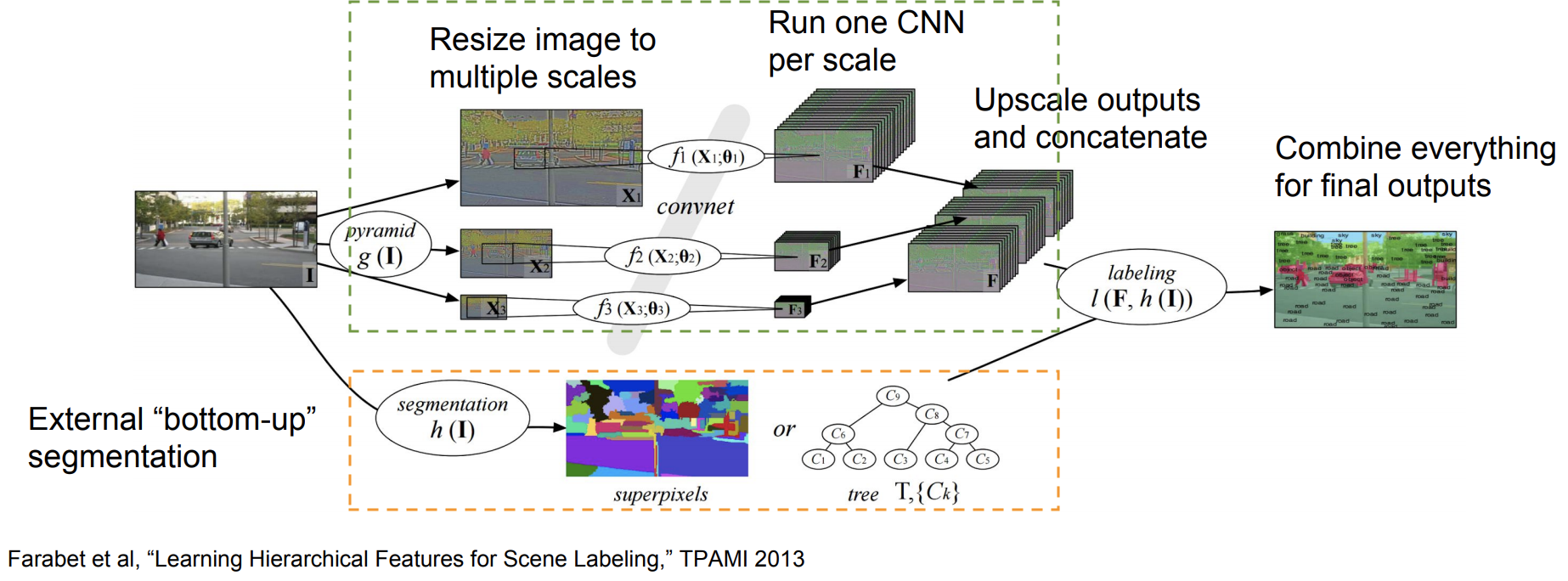
확장된 버전1 : Multi-Scale
-
이미지의 여러 가지 Scale 를 이용하였음
-
Image Pyramid
- 이미지를 다양한 Scale 스케일링함
- 스케일링된 각각의 이미지들을 별도의 CNN으로 돌림
- 각 CNN을 통해 나온 feature map을 원본과 같은 크기로 up sampling해주게 됨
- 그리고 모두 concate 해줌
-
“Bottom-up” Segmentation
-
위에 Image Pyramid 과정에서 줄 수 없는 큰 맥락에서의 추가적인 정보를 제공하는 역할
-
Superpixel : 근접하는 위치에 pixel들을 보고 큰 변화가 없으면 연관된 지역으로 묶어주면서 영역을 구분해 나감

(슈퍼픽셀 분할 결과 : 슈퍼픽셀을 각각 200, 400, 800, 1600, 3200, 6400개씩 갖도록 설정)
-
Segmentation Tree : 어떤 pixel들이 같이 match 되는지 결정해줌
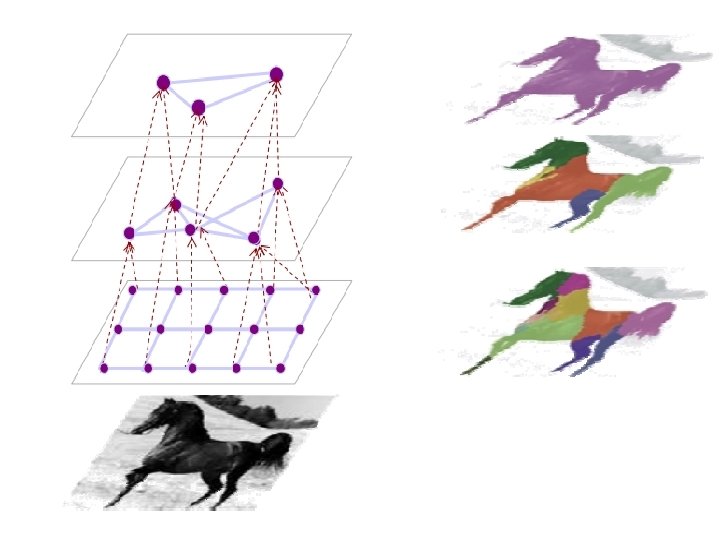
(The colors of segments match the color of node)
-
-
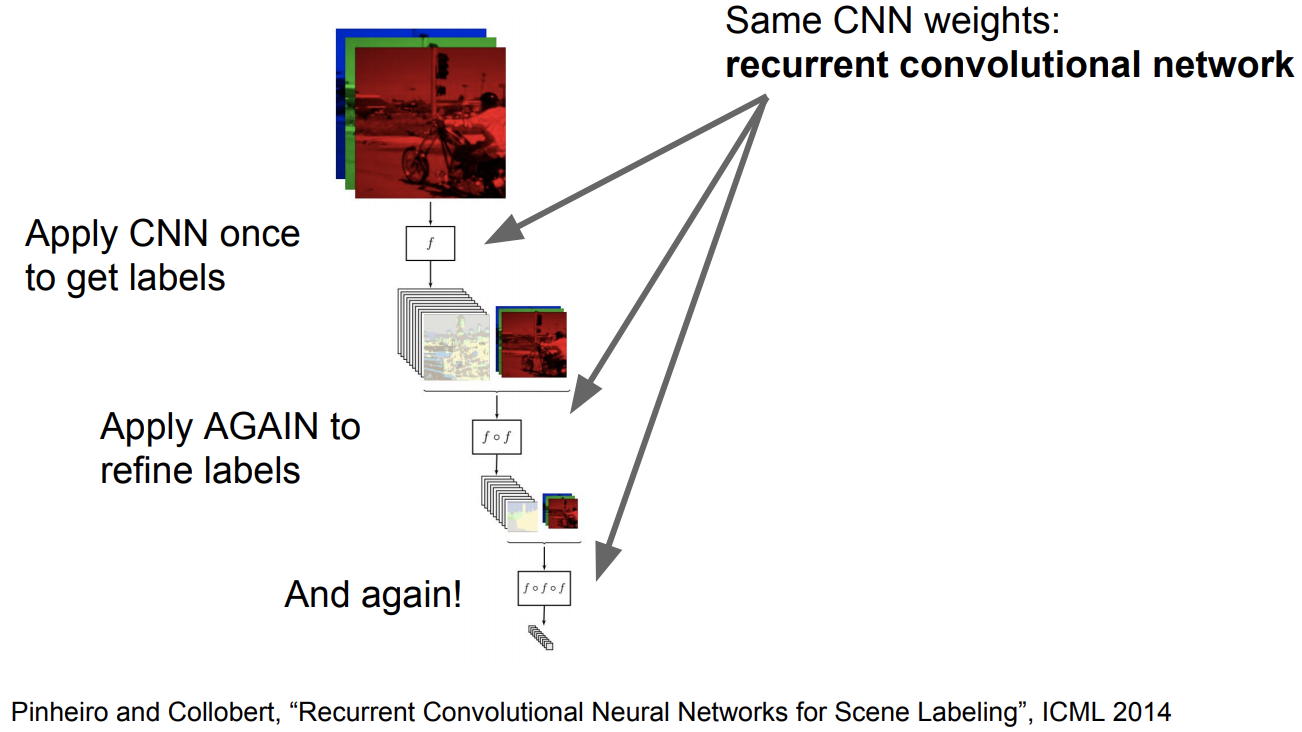
확장된 버전2 : Refinement
-
반복적인 Refinement 작업을 수행
-
iteration이 많아질수록 결과가 더 훌륭해짐
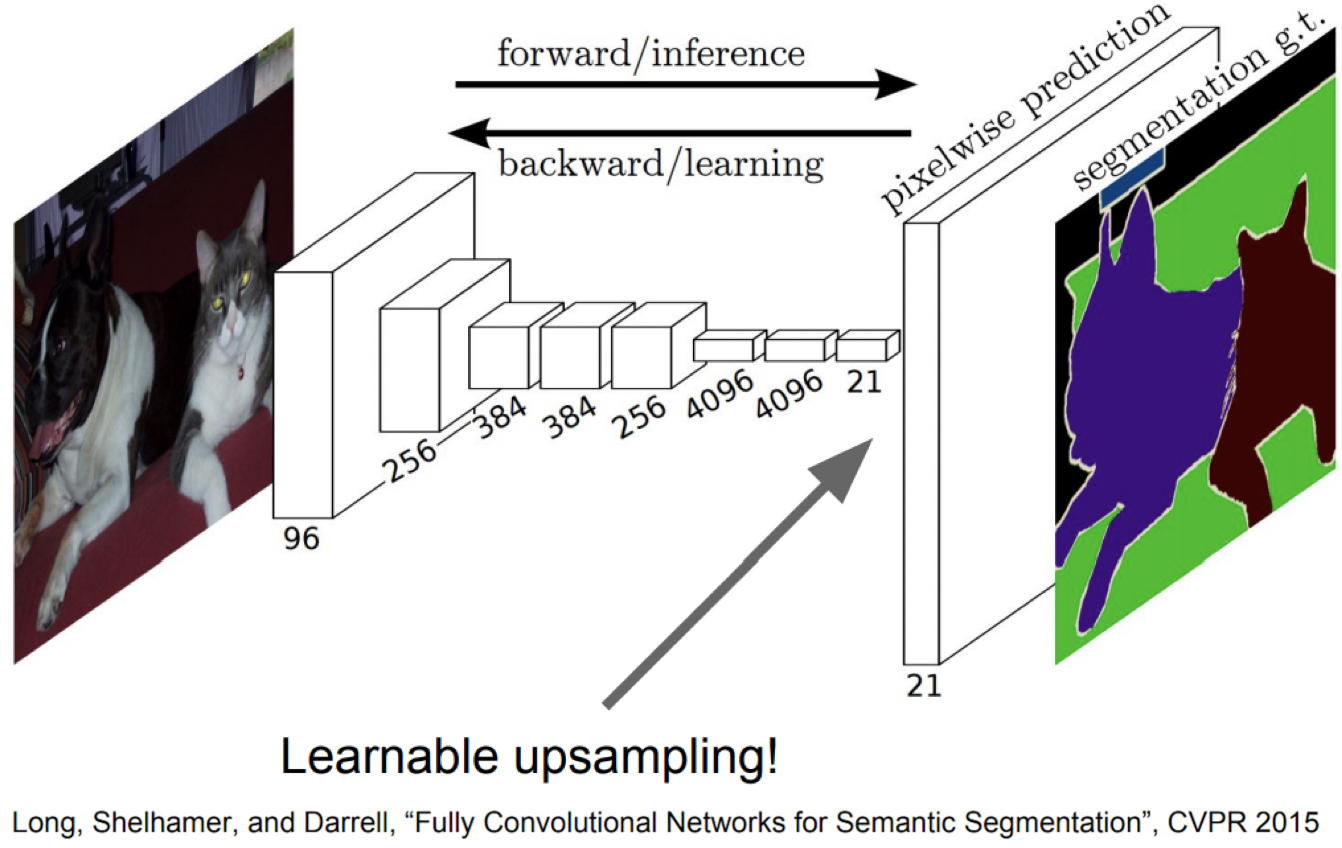
확장된 버전3 : Upsampling
-
작아지는 feature map을 다시 크게 복원을 해줘야되는 upsampling 방법에 있어서도 Network의 일부분으로 편입시킴
-
Skip Connection
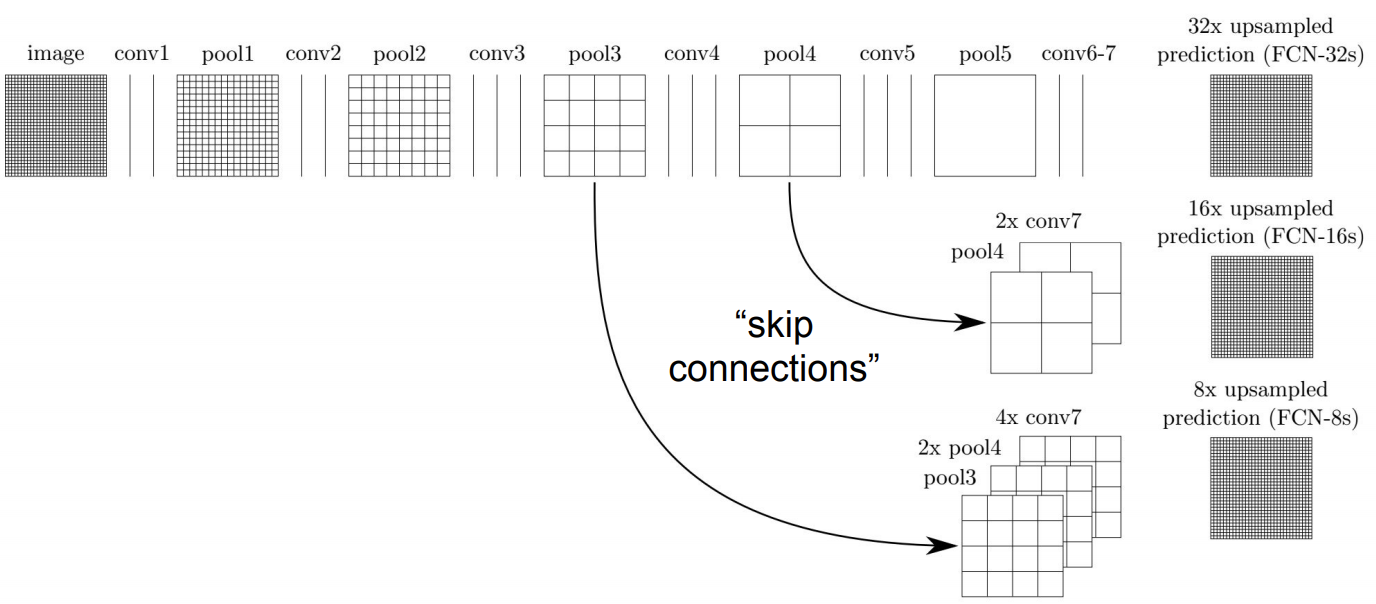
-
끝까지 down sampling 된 것 (conv. 6-7까지 통과한 feature map)을 up sampling 하는거 뿐만 아니라 초기의 pooling 단계에서 또 다른 convolutional feature map을 추출해 이것들도 up sampling 함
-
초기의 pooling 단계에서 Skip Connection를 하는 이유 :
초기 conv. layer일수록 Receptive field는 더 작음
 In a deep learning context, the Receptive Field (RF) is defined as the size of the region in the input that produces the feature
In a deep learning context, the Receptive Field (RF) is defined as the size of the region in the input that produces the feature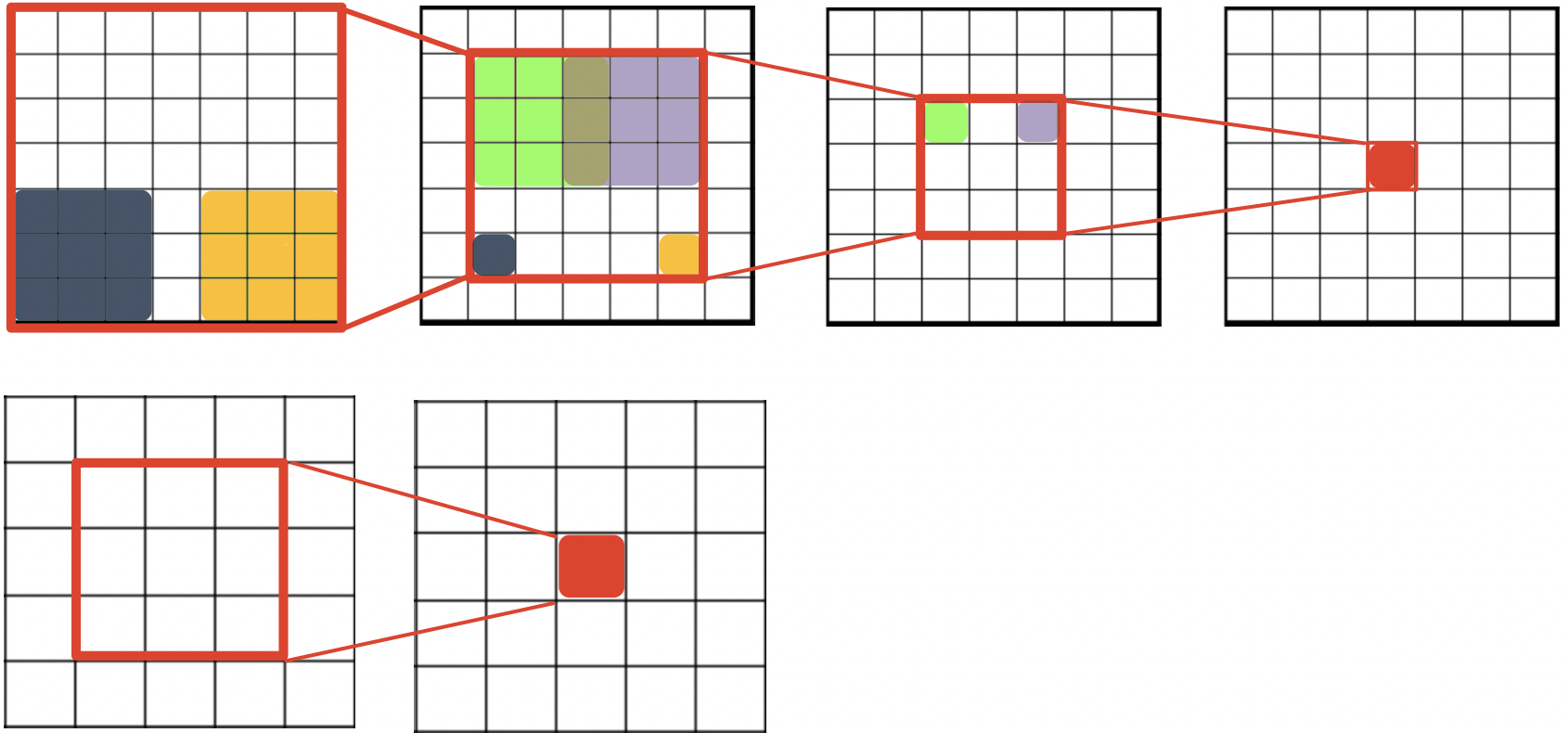
그래서 원본 이미지의 세밀한 구조를 파악하는데 있어서 더 도움을 주는 건 초기의 conv. layer임
-
-
결국 upsampling한 것 들을 모두 합쳐서 더 좋은 결과를 얻음

-
-
Convolution transpose
-
Learnable Upsampling
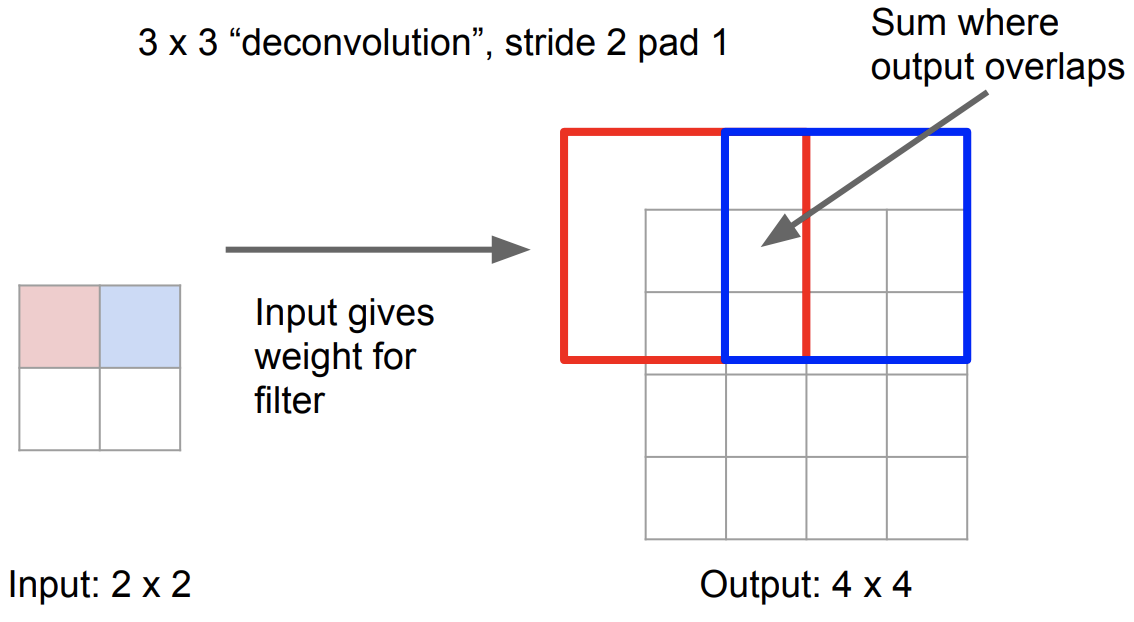
- Input Weight을 제공하여 filter과 함께 operation을 통해 output map이 생성
- 겹치는 부분은 합침
-
Deconvolution의 Forward Pass / Backward Pass = Convolution의 Backward Pass / Forward Pass
-
Instance Segmentation
-
우선 Instance를 하나하나 detect를 함 , 각각의 Instance내의 pixel들을 labeling한 것
-
Semantic Segmentation과 차이 : Instance를 구분을 할 줄 아느냐 못하느냐
-
R-CNN 와 매우 비슷함
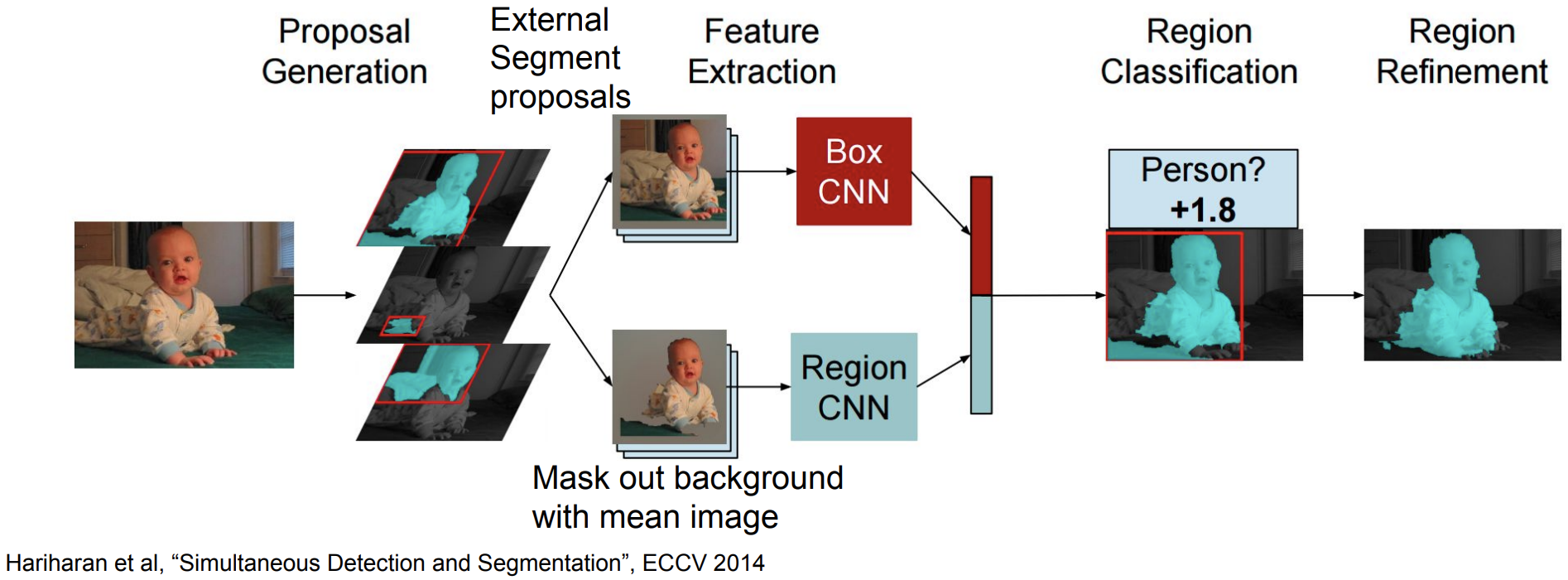
-
input 이미지를 받아서 별도로 Segment proposal을 진행
-
각각의 Segment proposal된 부분에 대해서 feature를 뽑은 다음 이를 CNN에 돌림
-
Box CNN : cropping 한 이미지를 그래도 받아 Bounding box를 결과물로 얻게됨
-
Region CNN : cropping 한 이미지에서 mean color를 이용해서 背景을 제거하고 前景만 입력으로 넣음
-
-
Box CNN와 Region CNN 결과를 concat한 다음 그 region에 대해서 classification 수행
-
Region을 다듬어줌
-
확장된 버전1 : Hypercolumns
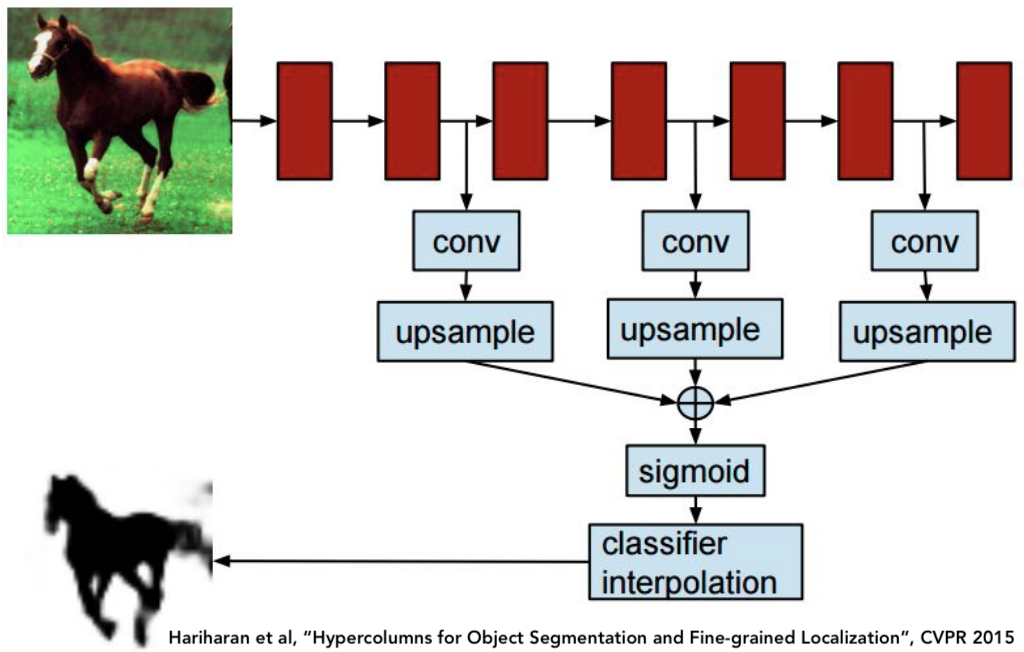
- 먼저 원본 이미지를 cropping 함
- crop한 이미지를 AlexNet에 돌려줌
- convolution을 진행하는 과정에서 그때 그때 Up sampling을 해서 모두 합침
- 각 독립된 Pixel 내에서 logistic classifer를 수행을 하고 그 결과물에서 각각의 pixel이 얼마나 前景인지 背景인지를 판단함
확장된 버전2 : Cascades
-
Faster R-CNN과 유사함
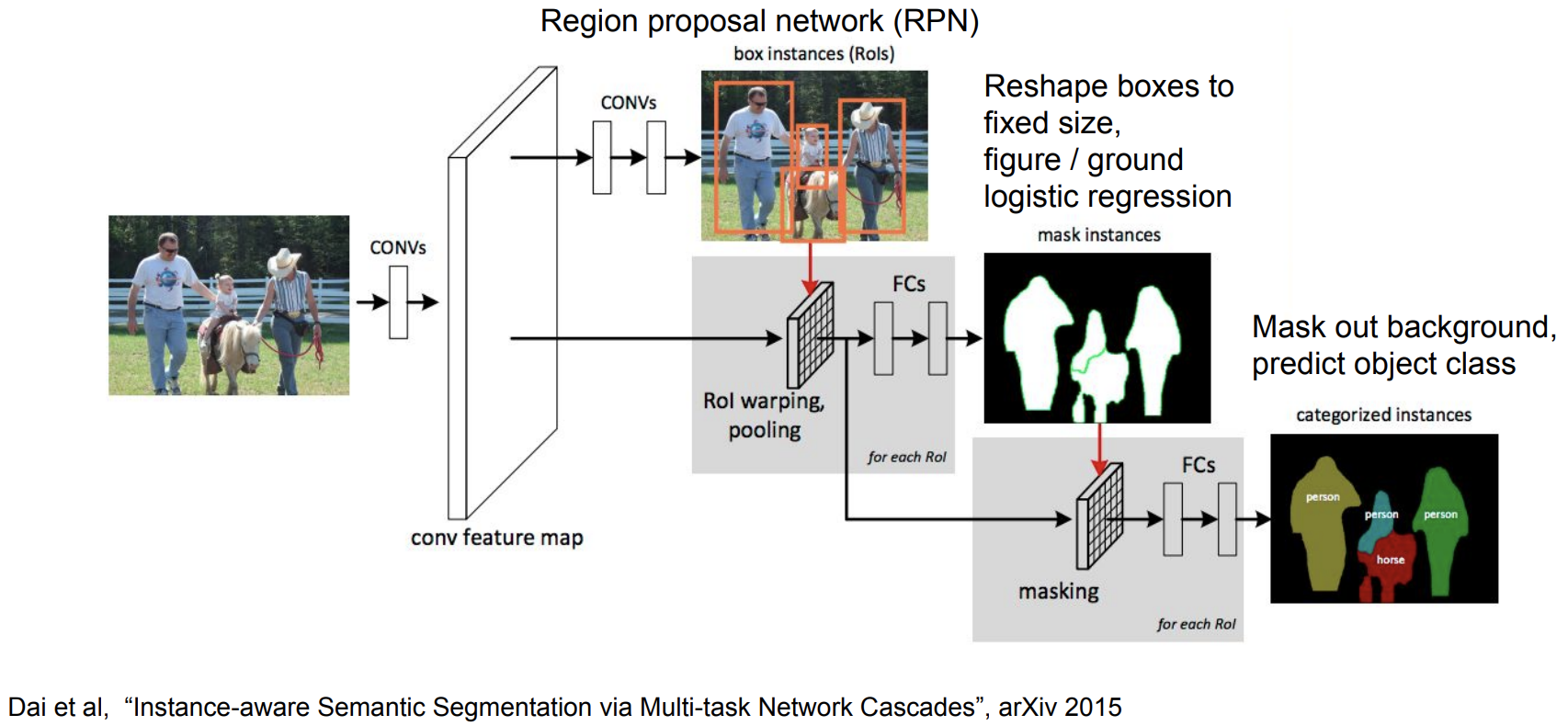
- 이미지 자체를 convolutional 시켜서 feature map을 생성
- Faster R-CNN의 Region Proposal Network을 그대로 활용해서 box instance를 뽑아냄
- 생성된 box들을 RoI Pooling을 통해 동일한 size의 vector로 맞춰준 다음 fully connected layer로 넣어줌
- Figure/ground logistic regression을 이용해서 mask instance를 생성
- masking 과정을 통해 背景를 날려버리고 前景만 유지를 하고 이를 다시 fully connected layer로 넣어서 object classification 해내는 과정을 거치게됨
-
End-to-End 학습가능
《Reference》