Convolutional Neural Network
CNN의 소개
- 간략한 역사 : Youtube
- Terminology
- Localization : 하나의 이미지 내에서 하나의 Object를 찾아내는 것
- Detection : 하나의 이미지 내에서 여러개의 Object를 찾아내는 것
- Segmentation : Object의 형태를 따내는 것
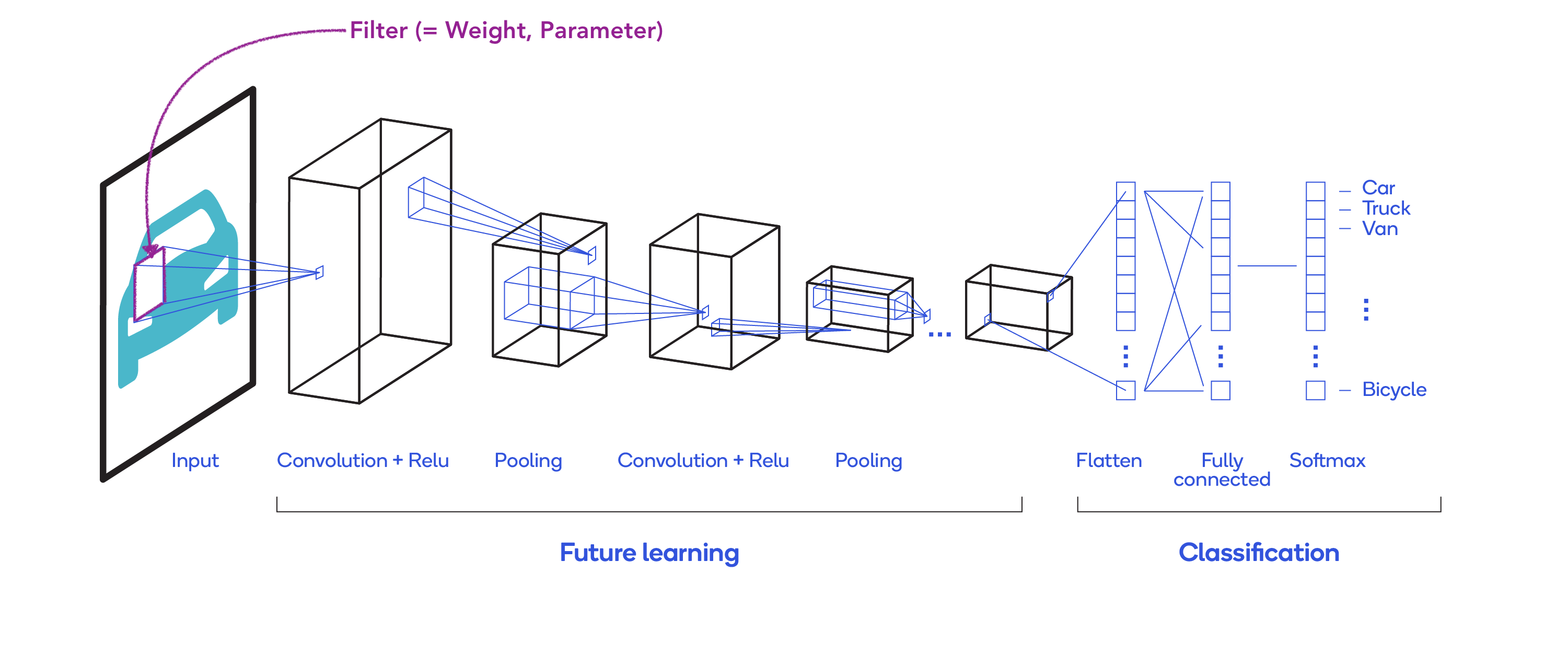
CNN architecture
Padding
- zero padding : 데이터의 주변에 0을 붙여주어 필터를 통과한 후에도 데이터의 형태가 유지되도록 하는 것입니다.
- zero padding을 하지 않는다면, 7x7 형태의 입력 데이터를 3x3 형태의 필터를 간격을 1씩 이동하며 통과하면 5x5 형태의 데이터가 출력되어야 하지만 zero padding을 해서 3x3 필터를 통과하면 7x7 형태가 유지된 채로 출력됩니다.
- padding을 하면 데이터의 손실을 줄여줄 수 있지만, 원래 데이터에 없던 데이터를 붙였기 때문에 noise가 발생하게 됩니다.
- noise의 영향을 최소화하기 위해 padding 값을 0으로 하는 것입니다.
- noise가 발생함에도 데이터의 손실을 줄여주는 게 더 낫기 때문에 padding을 합니다.
Convolution Layer
-
동작 과정 및 설명 (👇 Stride = 2, Padding = 1时)
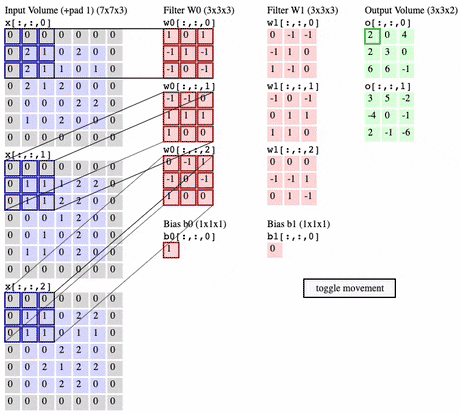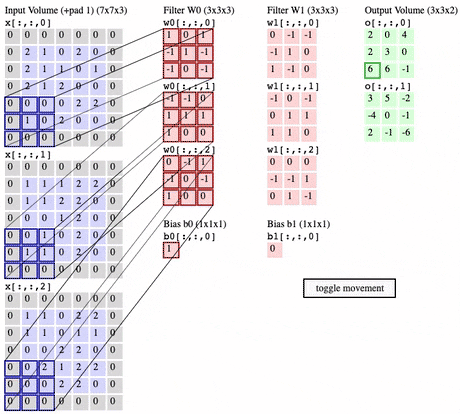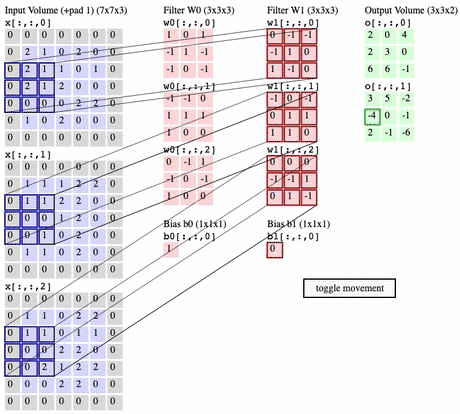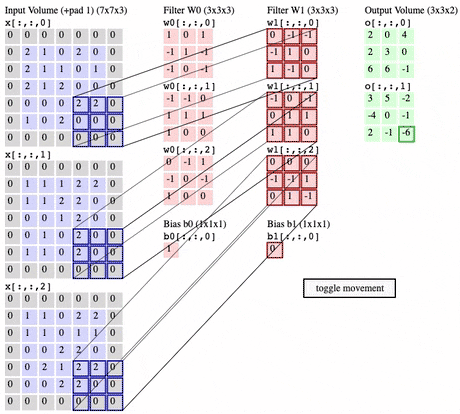
-
Filter
-
반드시 input과 같은 depth를 가져야됨
-
간단히 설명하자면 Filter의 역할은 feature 식별용임
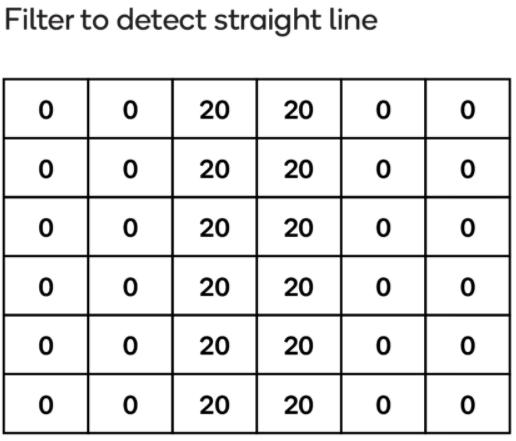
-
-
Convolution operation
- filter가 image(= Input volume) 위로 이동하면서, dot product 계산
-
Convolution Layer에서는 x개의 filter 가 Convolution Layer의 input위에서 Convolution operation를 진행하면 x개의 Activation map들을 생성함
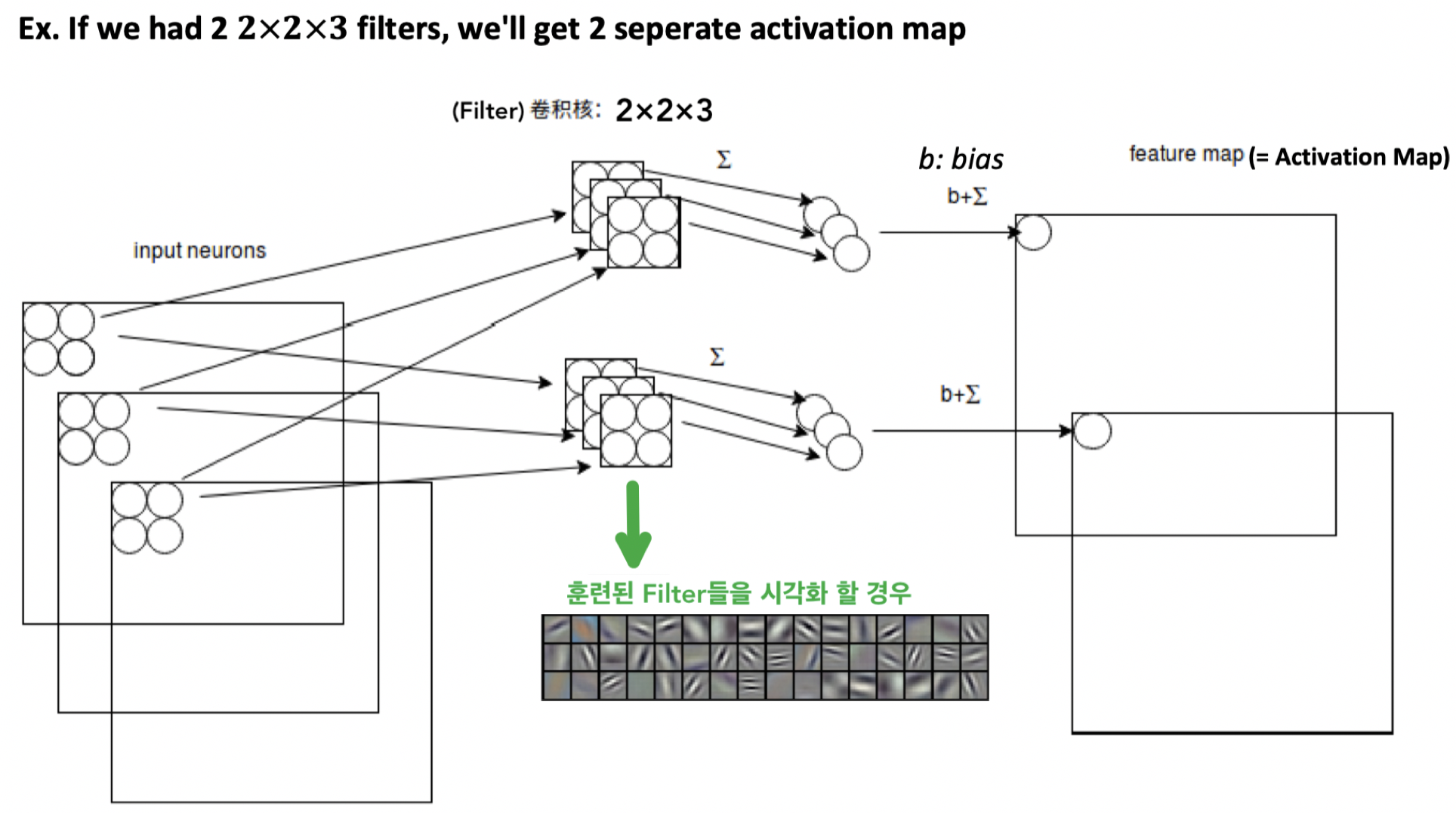
-
참고 : Filter가 1 × 1 × input depth 이라도 의미가 있음

-
But Input이 2차원 ( ex. 6×6×1 ) 일 경우 stride 1로 1×1×1 인 Filter 취하는건 아무런 의미 없음
-
-
Zero-Padding
- Zero-Padding를 사용하지 않으면 Activation map이 몇개의 layer 만 거치게 되면 size가 0으로 소멸됨
- Zero-Padding를 사용하여 Activation map 크기를 보존해주되 그래도 size를 점차 줄여주기 위해 pooling layer가 필요
- 计算公式1 : 적합한 Zero-Padding 수 구하기
-
생성된 Activation map들은 다음 Convolution Layer의 input으로 전달됨
-
计算公式2 :1개 Activation map의 Width or Height size 구하기
 total Activation map depth = filter 개수
total Activation map depth = filter 개수
-
-
Example :
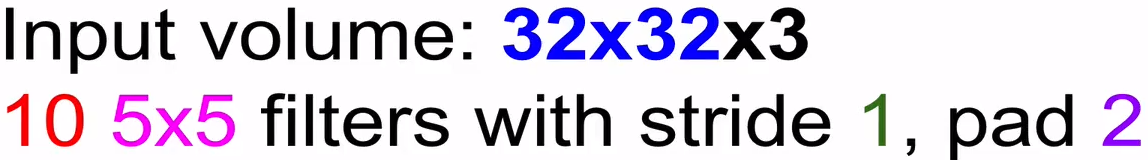
Q1 : 그럼 Activation map size는?
\[\text{ Input size (with pad)} = 36 \times 36 \times 3 \\ \text{ 1 Activation map size } = {36 - 5 \over 1} + 1 = 32 \\ \text{ Total Activation map size } = 32 \times 32 \times \color{red}{10}\]Q2 : 이 layer의 parameter수는 ?
\[\text{ Amount of 1 Filter's parameter (with bias)} = (5 \times 5 \times 3 ) + 1 = 76 \\ \text{ Total amount of 10 Filter's parameter (with bias)} = 76 \times 10 = 760\]
-
-
Pooling Layer
-
각 Activation map을 좀 더 작게, 좀 더 관리할 수 있게 만들어 주는 역할
-
Pooling 방법 :
方法1 :Max Pooling - 해당 구역에서 최대값을 찾는 방법
- Hyperparameters :
- Filter size (일반적으론 2 설정)
- Stride (일반적으론 2 설정)
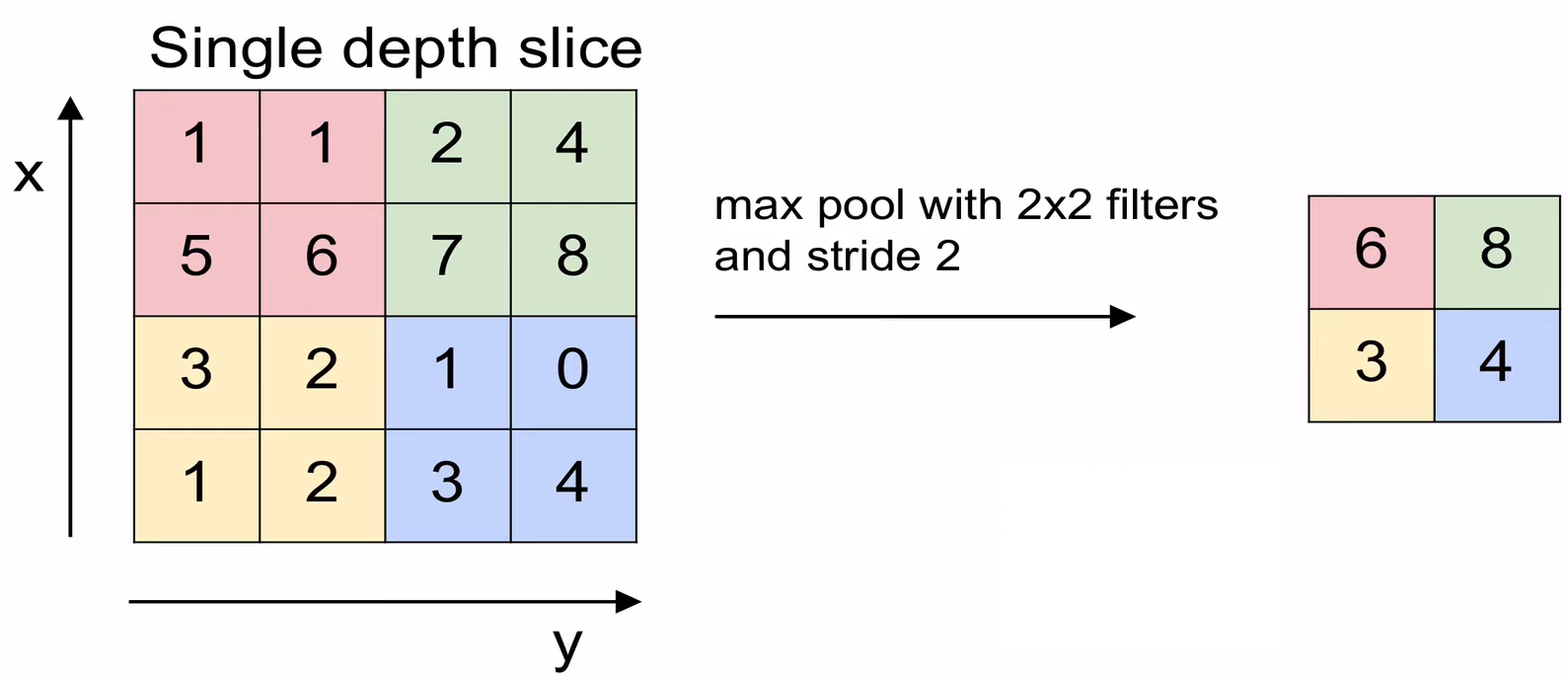
-
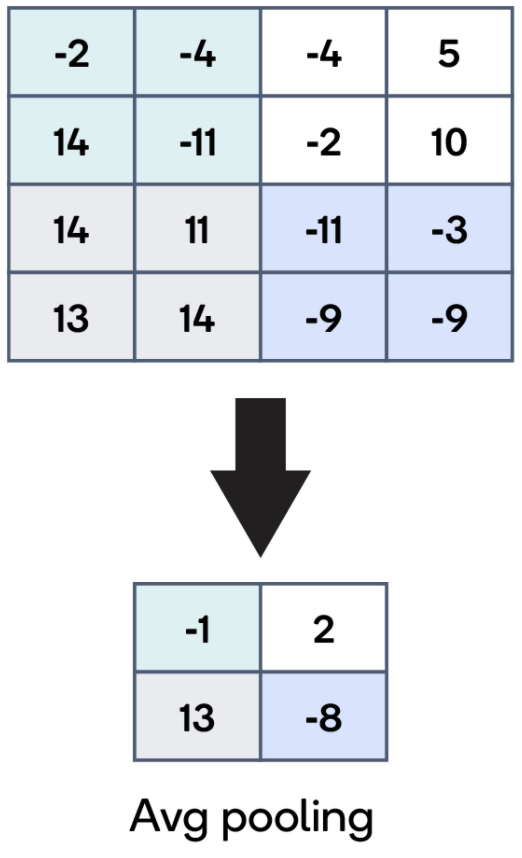
计算公式3 :Max Pooling통해 나온 Activation map의 Width or Height size 구하기
\[{\text{ Input Width or Height size } - \text{ Filter Width or Height size } \over \text{ Stride }} + 1\] total Activation map depth = Input depth
方法2 : Average Pooling - 해당 구역의 평균값을 계산하는 방식
- Hyperparameters :
-
Pooling을 하는 이유
-
overfitting을 방지하기 위해서
- 만약 우리에게 64x64인 이미지가 주어져 있다고 하고 이를 300개의 8x8 형태인 filter로 Convolution하 (stride가 1이고 padding이 0이라고 가정) , 한 개의 특성맵에 (64-8+1)x(64-8+1) = 3349개의 feature가 존재하고 이러한 특성맵이 합성곱 층에 300개 존재하므로 총 3349x300 = 974,700개의 특성이 존재하게 됩니다.
- 이렇게 feature가 많다면 overfitting이 생길 가능성이 높습니다. 그럼으로 이를 pooling을 통해 데이터의 크기를 줄여 조절하는 것입니다.
-
평행이동이나 변형에 대해서 일정 수준의 不变性을 갖기 위해
-
데이터가 오른쪽으로 1칸 이동하고 Max-pooling을 해도, 원래 데이터에서 Max-pooling을 한 결과와 동일한 것을 알 수 있습니다.

-
어떤 물체의 구체적인 위치가 아닌 존재 여부가 더 중요할 땐 이런 일정 수준의 이동에 대한 不变性이 유용하게 작용합니다.
-
-
-
Pooling의 단점 :
- 원본 데이터의 크기를 줄이기 때문에 파괴적 입니다.
- 입력 이미지가 오른쪽으로 한 픽셀 이동했을 때 출력도 오른쪽으로 한 픽셀 이동해야 하는 Segmentation 같은 작업에는 이런 不变性이 필요하지 않습니다.
Classification Layer
- Flattened Layer
- used to convert the n-dimensional vector into a mono-dimensional vector
- Fully Connected Layer
- compute the class scores
- resulting a vector, where each of the numbers correspond to a class score
CNN Case Study
LeNet-5 (LeCun at al. 1998)
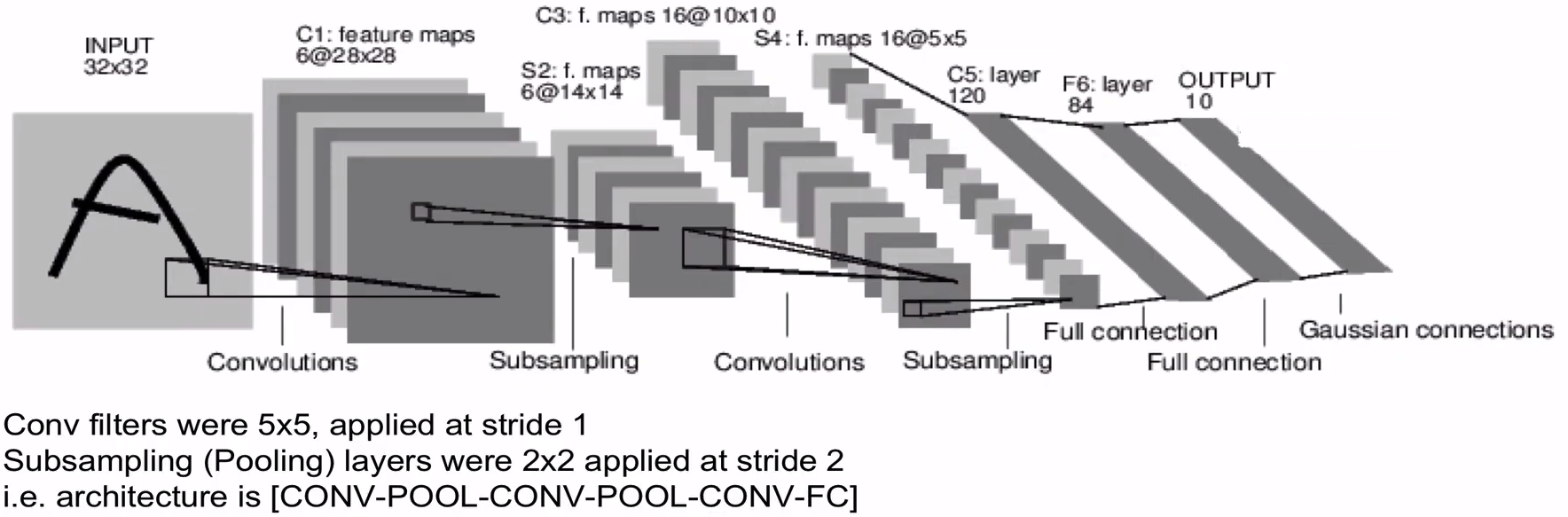
- Detail : Blog
AlexNet (Krizhevsky et al. 2012)
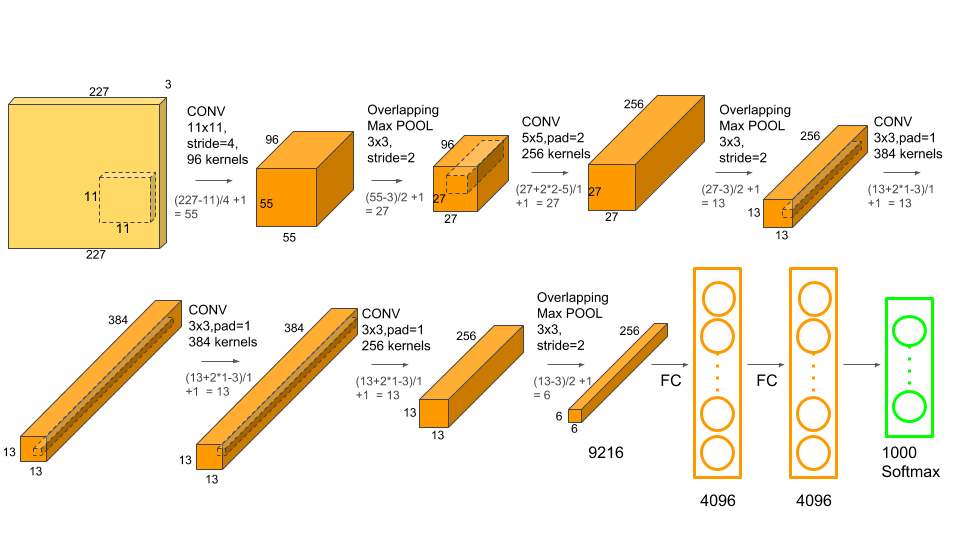
-
input size : 227×227×3
-
2개의 GPU로 병렬연산을 수행하기 위해서 병렬적인 구조로 설계됨
-
첫번째 Layer : Convolution Layer
- 96개의 11x11x3 사이즈 Filter로 input을 Convolution operation 해줌, Stride=4
- 즉, parameter 개수 = (11x11x3) x 96 = 34,848
- 병렬연산을 수행하기 위해 Filter를 48개 48개로 나눔
-
두번째 Layer : Pooling Layer
- 3x3 사이즈 Filter, Stride=2 적용
- parameter 개수 = 0, (parameter는 Convolution Layer때만 있는 것!)
-
전체 Layer 구조 :

- 통용적으로 Classifier 직전에 있는 Fully Connected Layer를 “FC7” 라고도 한다
-
Normalization Layer : 지금은 효용이 별로 없어서 더이상 사용되지 않는다고 함
-
특징 :
- 최초로 ReLU를 사용한 모델
- Data augmentation을 많이 사용함
- Fully Connected Layer에서 Dropout = 0.5
- Batch size = 128
- 7가지 CNN 모델을 앙상블해서 error rate를 2.8%정도 줄였음
- Learning rate = 0.01 (1e-2)
ZFNet (Zeiler and Fergus, 2013)
-
AlexNet과 유사
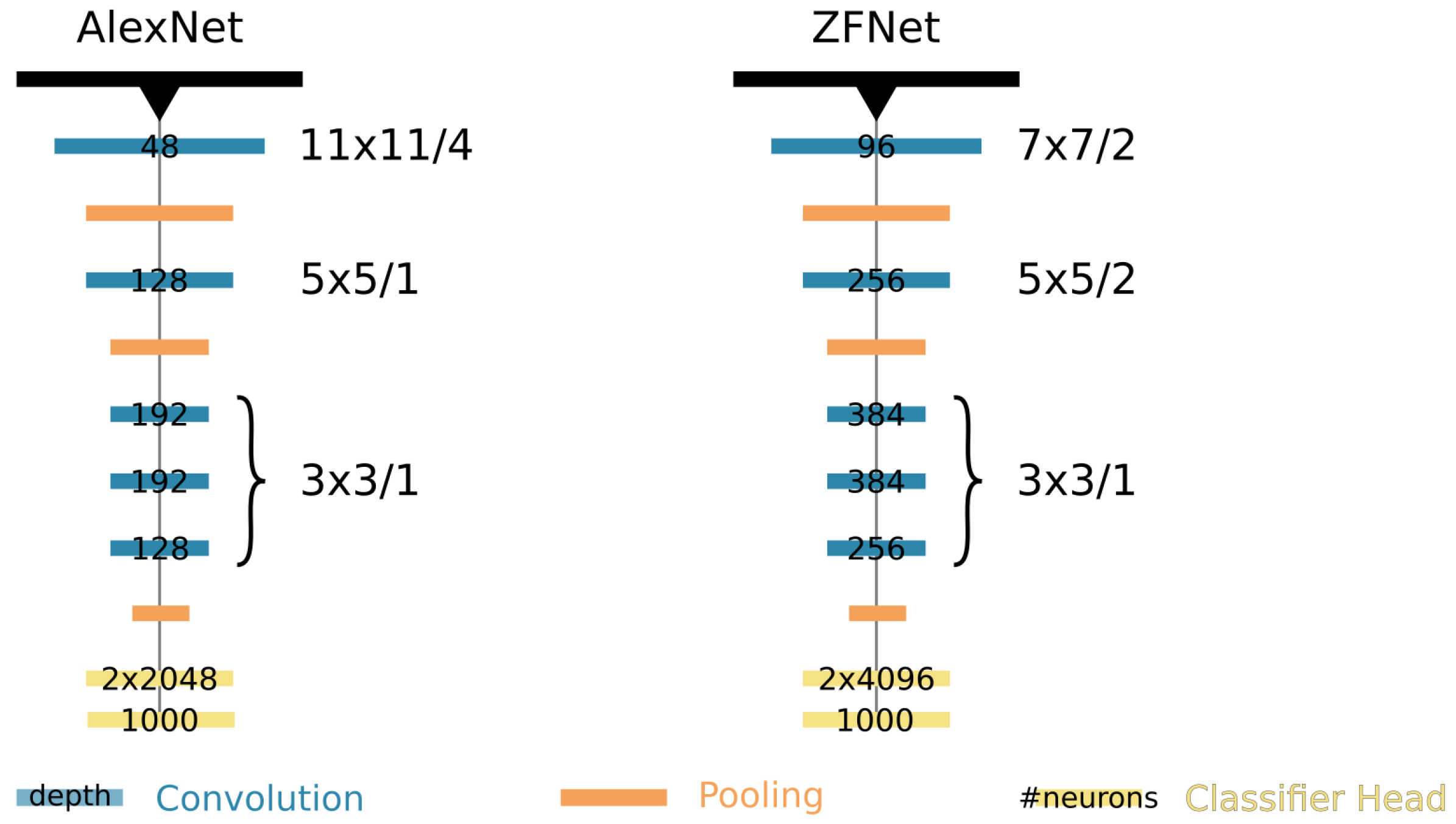
- 대신 첫번째 Layer의 11x11 Filter, Stride=4 를 7x7 Filter, Stride=2로 줄임
- 3,4,5번재 Layer의 Filter 개수를 늘림
-
Detail : Blog
VGGNet (Simonyan and Zisserman, 2014)
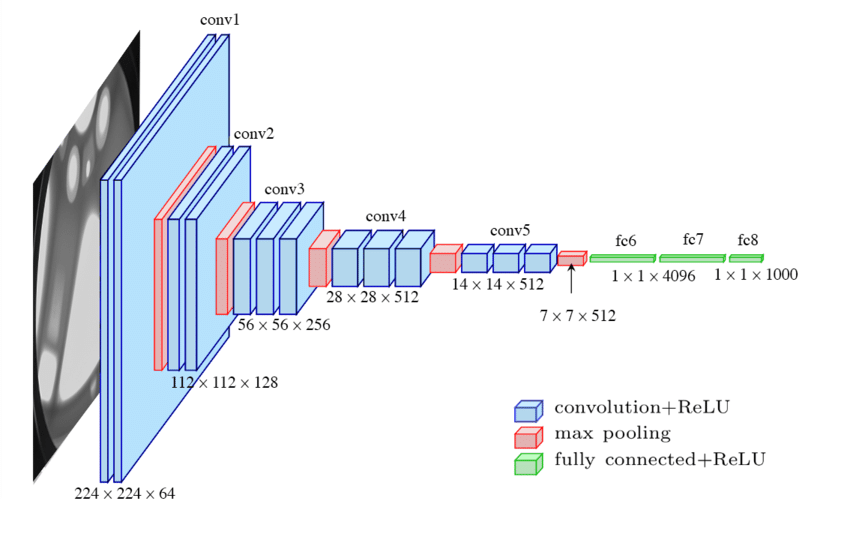
- 모든 Convolution Layer에는 오직 3x3 Filter , Stride=1, Padding=1를 사용
-
모든 Max Pooling Layer에는 오직 2x2 Filter , Stride=2 를 사용
-
전체 Layer

-
위에서 보이듯이 Fully Connected를 사용하는 건 효율적이지 못해 average pooling를 사용할 수 있음
-
GoogLeNet (Szegedy et al. 2014)
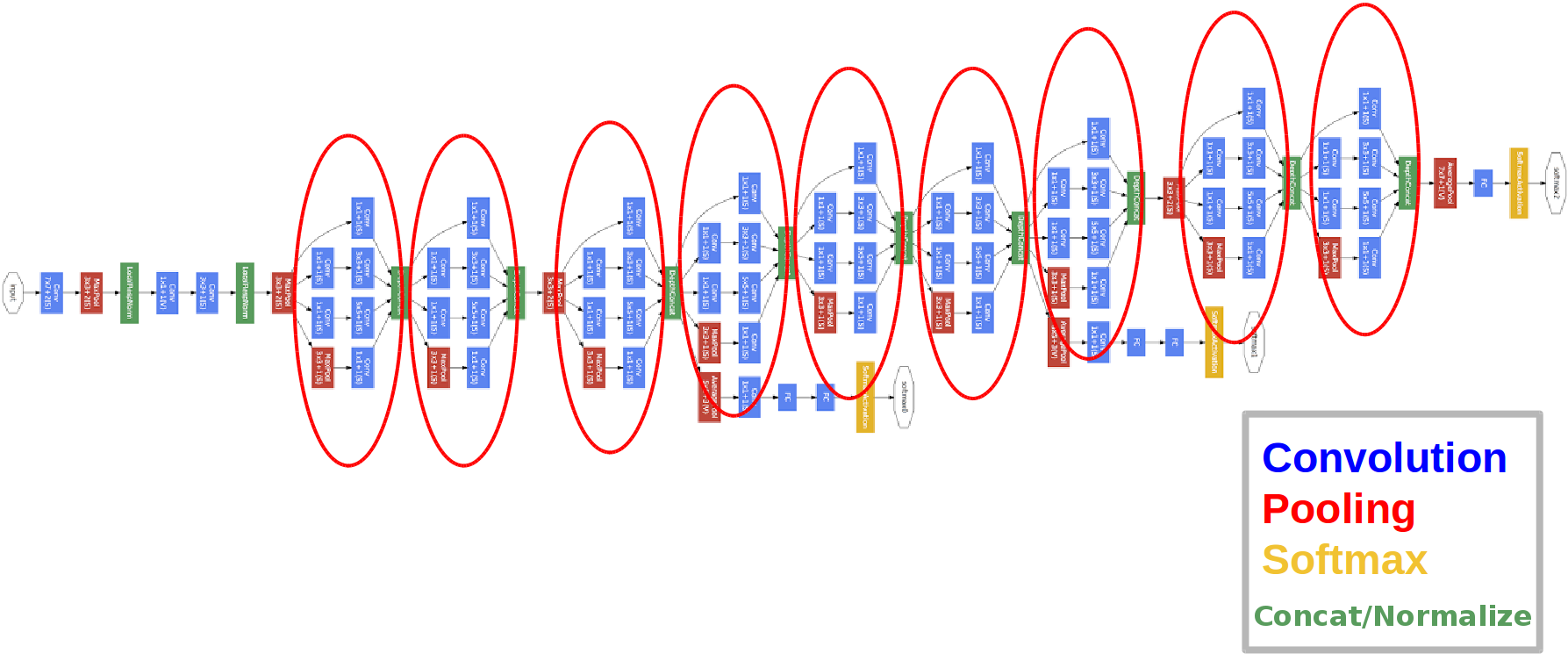
-
Inception 모듈이 연속적으로 연결된 형태
-
Inception module
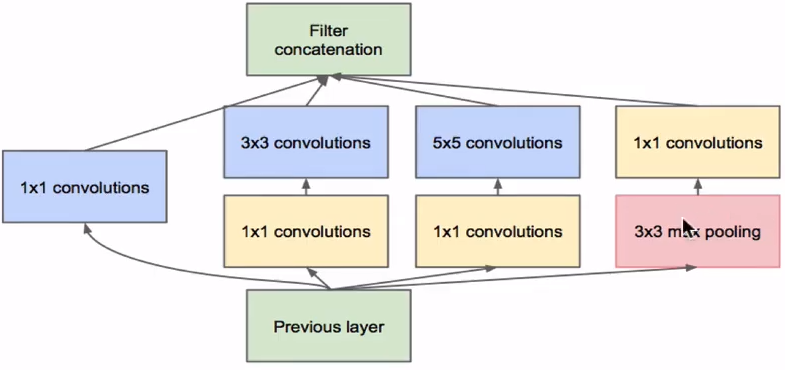
-
-
Fully Connected Layer를 아예 제거하고 average pooling을 사용함
- 모델의 Parameter 수를 다 합치면 약 500만개 밖에 안됨!
-
AlexNet과 비교했을 때,
- GoogLeNet 은 AlexNet의 1/12 수준의 parameter를 가짐
- 연산은 2배이상 빠름
- Top-5 Error는 약 10% 감소됨
ResNet (He et al. 2015)
-
모델들의 발전
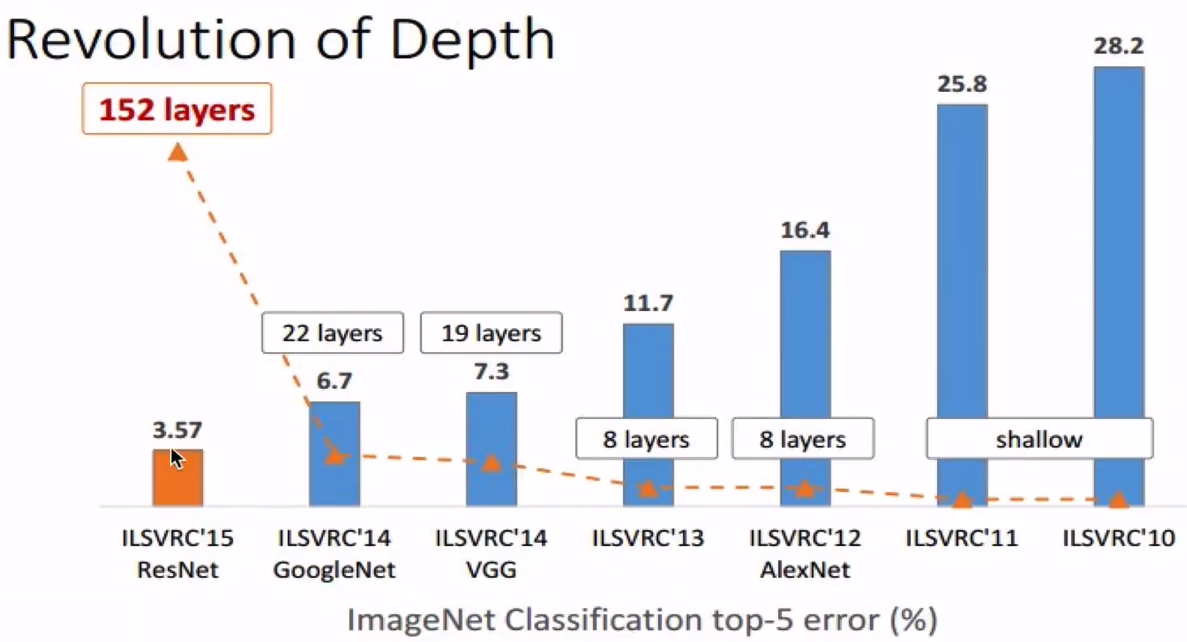
- Error rate는 점점
 , Layer의 크기는
, Layer의 크기는 
- Error rate는 점점
-
ResNet의 주장
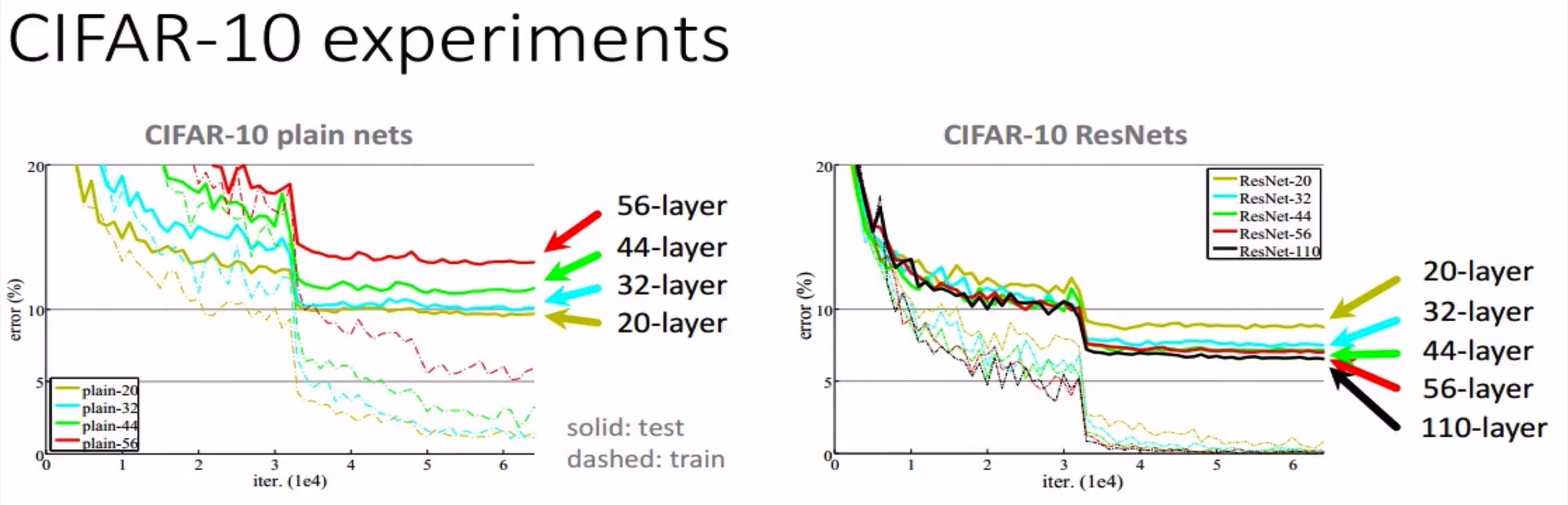
- 기존의 Net들은 Layer가 많아짐에 따라 Error rate가 커지는 현상이 나옴으로써 최적화에 실패해 있다고 함
- ResNet의 경우 Layer가 많아짐에 따라 Error rate는 줄어듬
-
특징
-
8개의 GPU machine에서 2-3주 동안 train을 시킴
-
test (runtime) 할 때는 비록 VGGNet 보다 8배 더 많은 Layer를 가지고 있지만 성능은 더 빠름. How?
-
첫번째 Convolution Layer다음 바로 Pooling을 통해 size를 56x56으로 줄여 이후 150개 Layer들은 이 size 기반으로 진행됨
-
Skip Connection
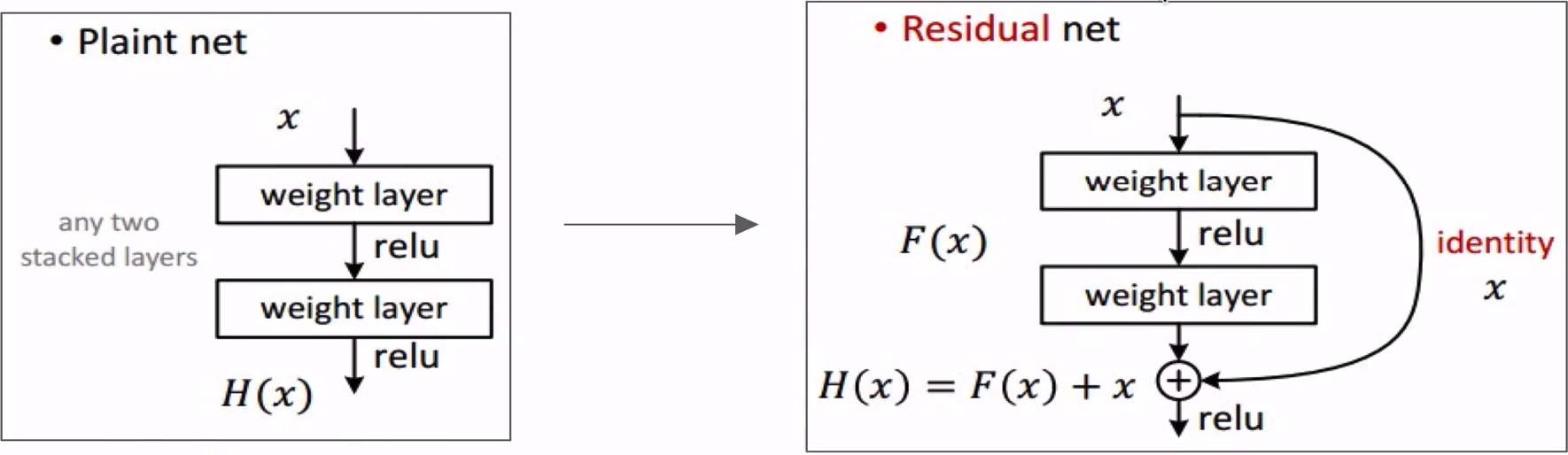
-
Plue 연산을 추가해서 Backpropagation이 진행될 때, 과정을 건너뛰고 앞쪽 Convolution Layer로 넘어갈 수 있음
参考 : 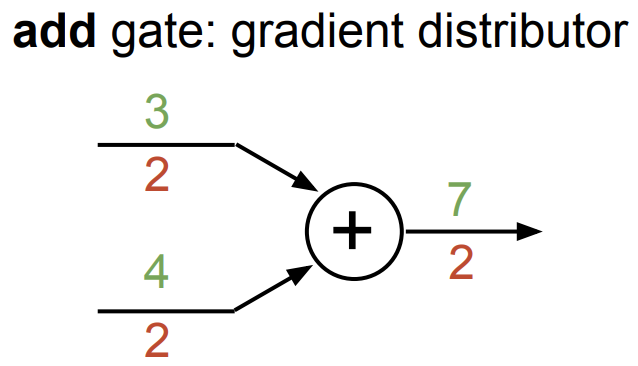
-
-
-
모든 Convolution Layer 다음 Batch Normalization을 사용함
-
Xavier/2 Weight Initialization을 사용함 (He et al. 이 만든거임)
-
Learning rate = 0.1, validation set error가 정체 되면 10으로 나눴음
-
dropout을 아예 사용하지 않음
-
DeepMind’s AlphaGo
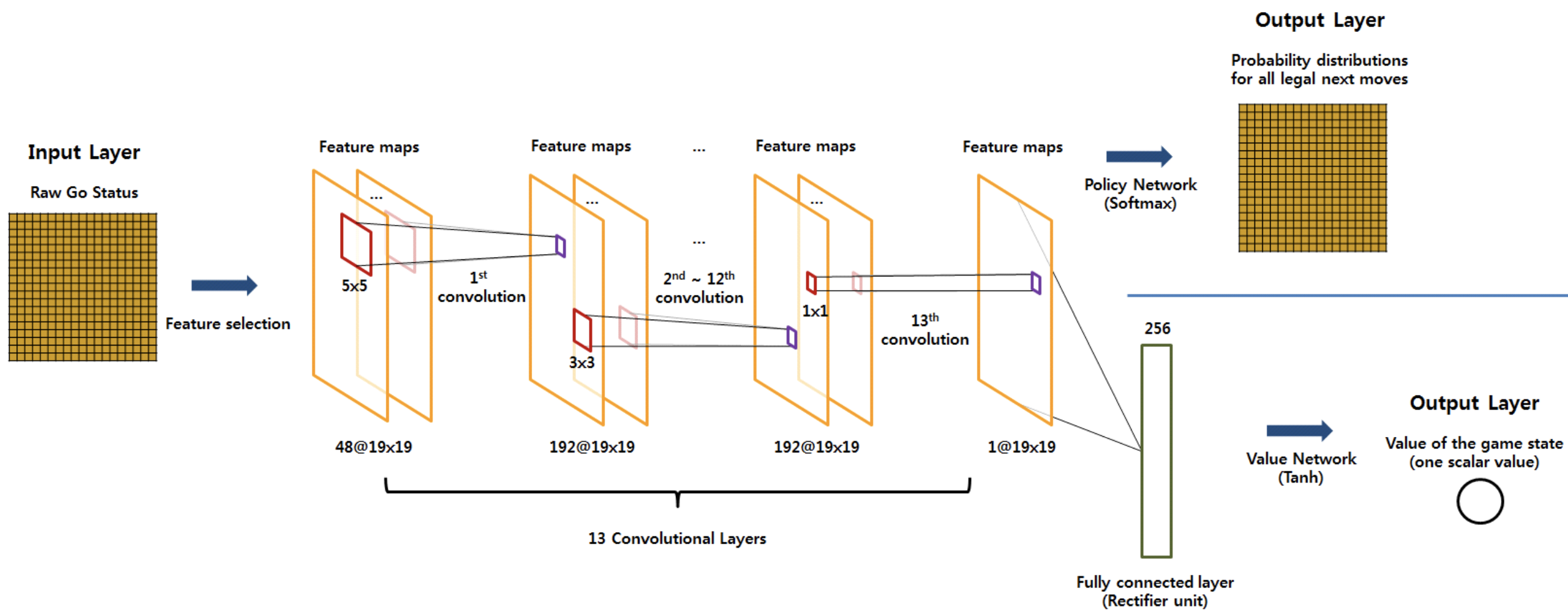
- Input size : 19x19x48
- Output size : 19x19 (19x19 인 바둑판의 어디에 두어야하는지에 대한 확률)
최근 Trend
- 더 작은 Filter 사용
- 더 깊은 Layer의 architecure 사용
- Pooling Layer, Fully Connected Layer를 점차 사용하지 않음
- 그냥 Convolution Layer만 사용 : Stride를 활용하여 spacial reduction하는 방식으로
- Fully Connected Layer의 문제점 :
- 연산량 매우 많음
- classification에 영향을 끼친 feature가 어느 부분에서 추출되었는지 (위치 정보) 도 알 수 없음
- input 의 크기 또한 제한된다
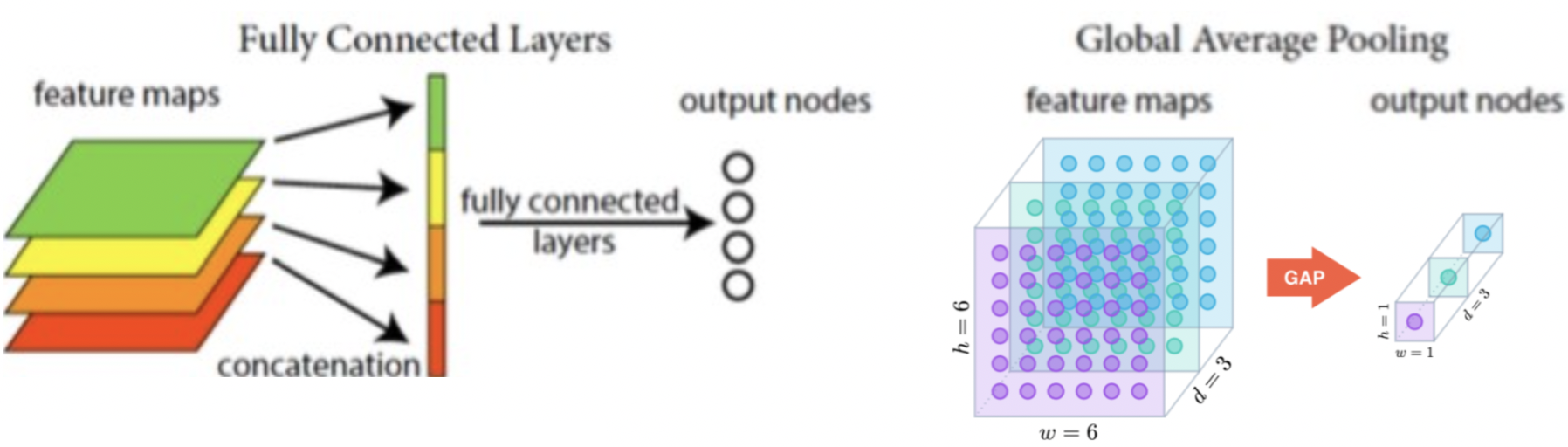
Global Average Pooling (GAP)
-
Fully Connected Layer의 대안으로 제시된 것
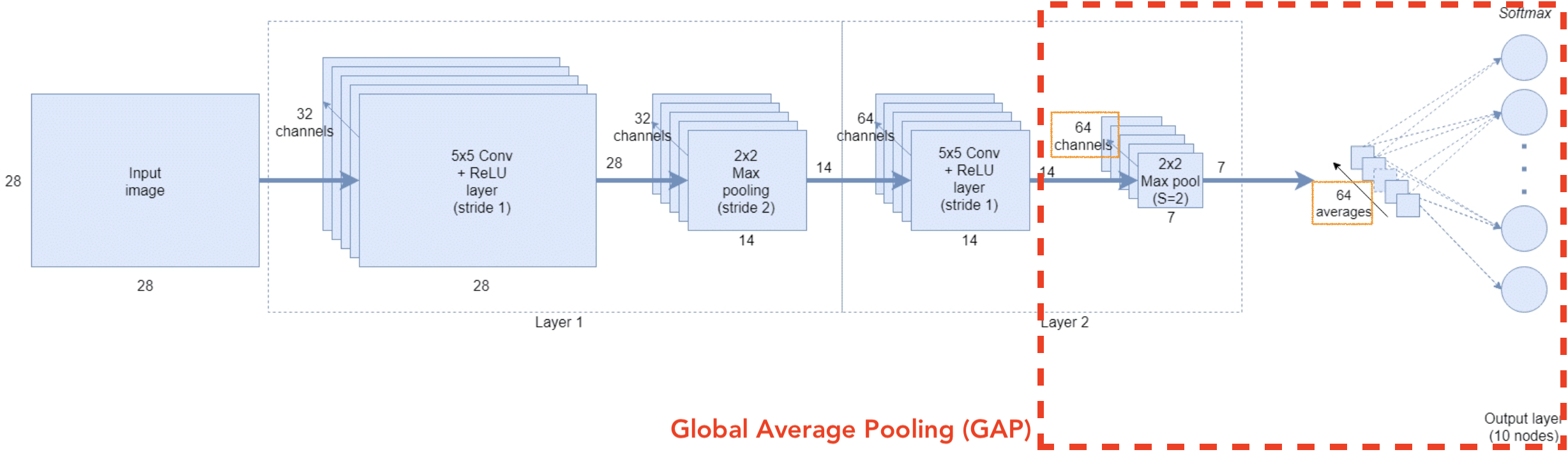
-
GAP는 각각의 feature map(= Activation map)에서 대표값(average)을 추출해 바로 각 class에 대한 score로 구성된 vector로 나타남
-
-
GAP의 특징 :
- 이전 feature map들이 가지고 있는 위치 정보를 유지하면서 class category로 직접 연관시키는 역할
- 별도의 parameter optimization 을 필요로 하지 않기 때문에 연산량이 적음
- overfitting 문제도 차단할 수 있음
Adversarial examples
-
Input 이미지에 대한 최적화를 함으로써 우리는 어떤 Class에 Score라도 maximize할 수 있음
-
이런 방법을 사용해서 CNN를 속일 수 도 있음

-
-
EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES [Goodfellow, Shlens & Szegedy, 2014]
-
“Neural Network이 Adversarial attack에 취약한 것은 Linear 한 성질 때문이다”
Example. Binary linear classifier를 속여보기
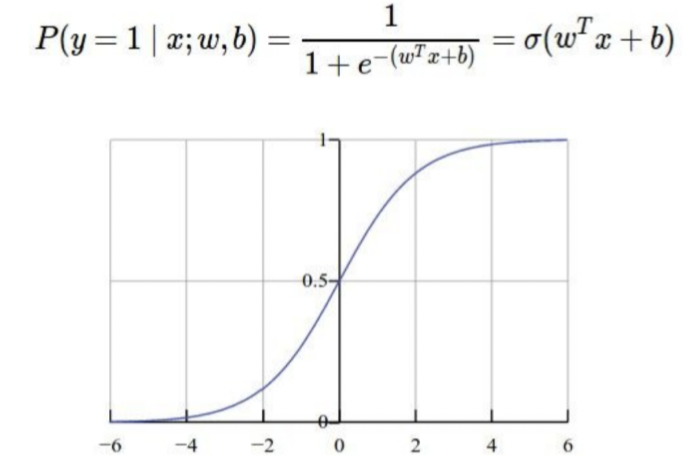
👉 class 1과 class 0의 확률을 합하면 1.0 이 나옴, 그래서 class 1 확률 = 1.0 - class 0의 확률

💁🏻 이제 Adversarial한 x를 만들어보자 (즉 결과가 classifier가 class 1이 나오도록 x를 조정해보자)
-
대응하는 w가 양수 일 경우 x를 크게 만들고, w가 음수 일 경우 x를 작게 만들자
- 대신 Adversarial한 x를 원래 x와 유사하게 보여야되기 때문에 약간의 변형만 준다 (한 0.5정도)

-
-
-
image x 같은 경우 큰 차원(ex. 224x224)을 가지고 있기 때문에 더 약간의 변화만 주더라도 매우 쉽게 Adversarial한 x를 만들 수 있음
- 그래서 Linear regression은 어떤 변화를 줘야하는지 정확히 파악하고 있는 경우라면 아주 작은 변화라도 크게 변경을 시킬 수 있음
-
사실 이런 문제들은 image에서만 국한되는 것이 아니라, speak recognition 등 여러 방면들에서 발생할 수 있음
Data Augmentation
-
데이터의 label은 변함없이 Pixel을 고침 그리고 이 변경된 데이터를 학습함
-
방법들 :
-
반대로 filp하는 방법
-
랜덤하게 자르고 스케일도 다양하게 하는 방법
-
색을 jittering 하기
-
복잡한 방법 :
[1] 이미지의 R,G,B에 대해 PCA를 적용함
[2] 그럼 각 R,G,B에 대해서 Principal componet direction (color가 변화해 나가는 방향성)을 따라서 color의 offset을 sampling 해줌
[3] 이 offset을 모든 pixel에 더해줌
-
and more …
- 작은 데이터셋의 경우 매우 유용
All About Convolutions
Small Filter
다음 방식들을 활용하면 CNN의 parameter 수가 줄어들어 연산량이 줄고 CNN가 더 non-linearity하게 됨
-
큰 filter 사용을 피하고 작은 filter를 사용하는 방식으로 대체하자
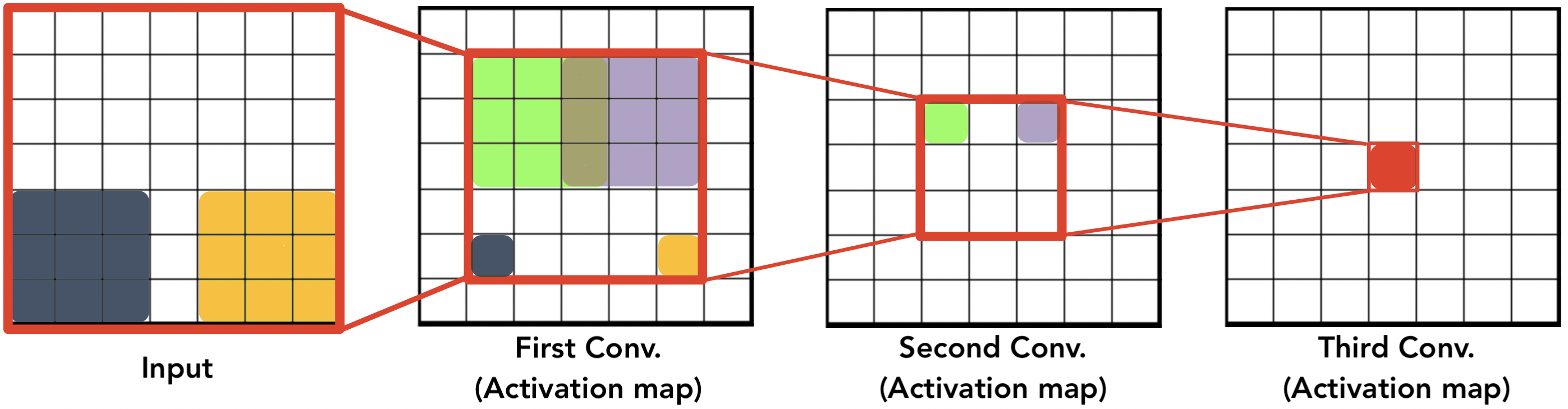
-
3개의 conv. layer가 있고 각 layer에는 3x3 filter (stride=1)를 사용한다하자
-
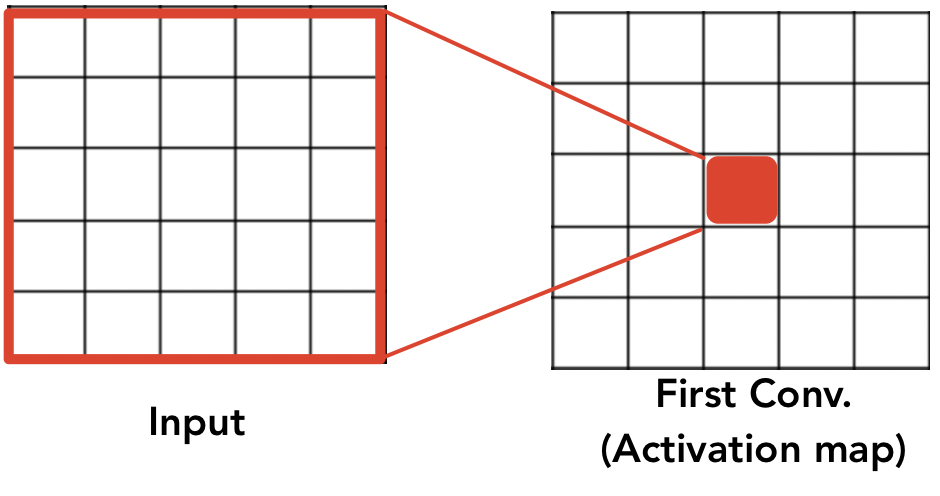
직관적으로 봤을 때, 3번째 conv. layer을 통과한 Activation map의 한 뉴런은 input layer의 7x7 영역 (Receptive field) 을 보게되는 셈임
-
즉, 7x7 filter (stride=1)를 지닌 conv. layer 1개를 통과 시킨 것과 같은 영향을 보이는 셈이다
-
-
그럼 위에 두 상황에서 parameter 수량과 연산횟수를 계산해보면 작은 filter를 사용하는 방식이 두 방면 모두 더 적다는 걸 알 수 있다.

-
그리고 더 층을 쌓을 수로 그만큼 activation function도 쌓아지기 때문에 non-linearity가 더 강화된다
-
-
1x1 “bottleneck” convolution도 매우 효과적임
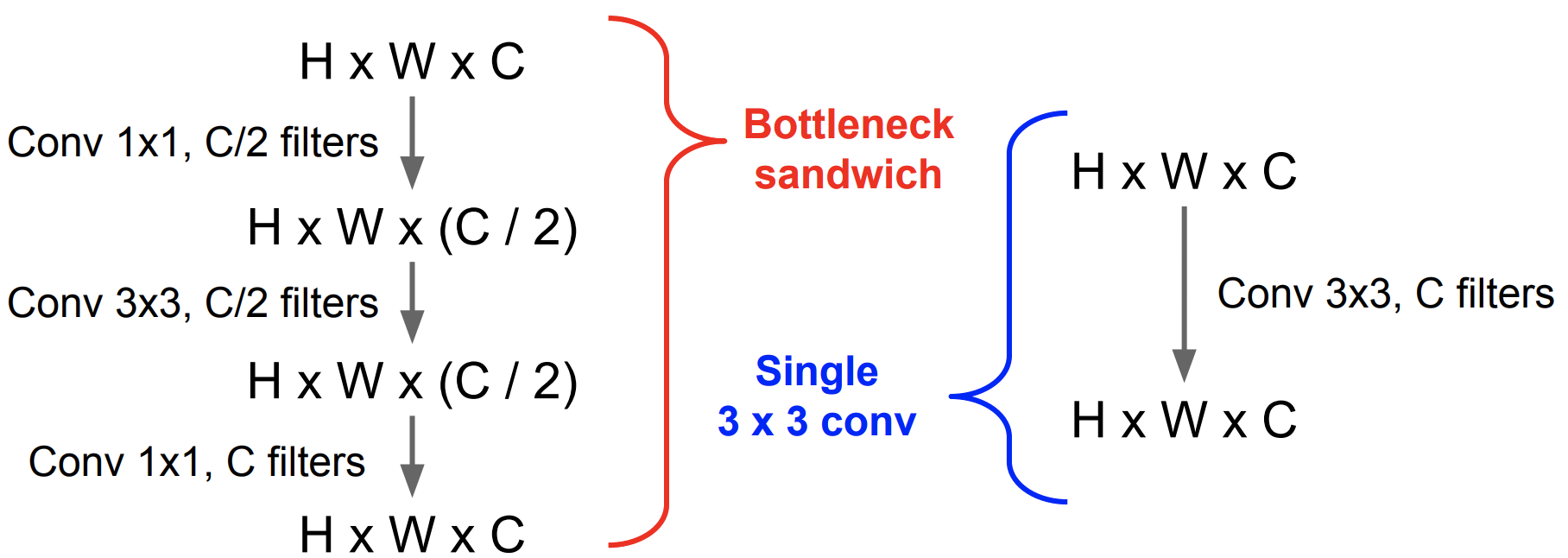
-
Parameter 수량 계산 (bias 제외)
Bottleneck Single **C/2개 1x1xC filter ** 1xCx(C/2) 개 C개 3x3xC filter 9xCxC 개 C/2개 3x3x(C/2) filter 9x(C/2)x(C/2) 개 **C개 1x1x(C/2) filter ** 1x(C/2)x(C) 개 Total (Sum) 3.25 x (C^2) Total (Sum) 9 x (C^2) 💁🏻 즉 Bottleneck 모델의 Parameter 수량이 더 적고 이로 인해 연산량도 더 적을 것임! (+ 더 깊은 층으로 인한 non-linearity 강화)
-
-
NxN convolution의 경우 1xN 그리고 Nx1의 두 개의 layer로 나누자
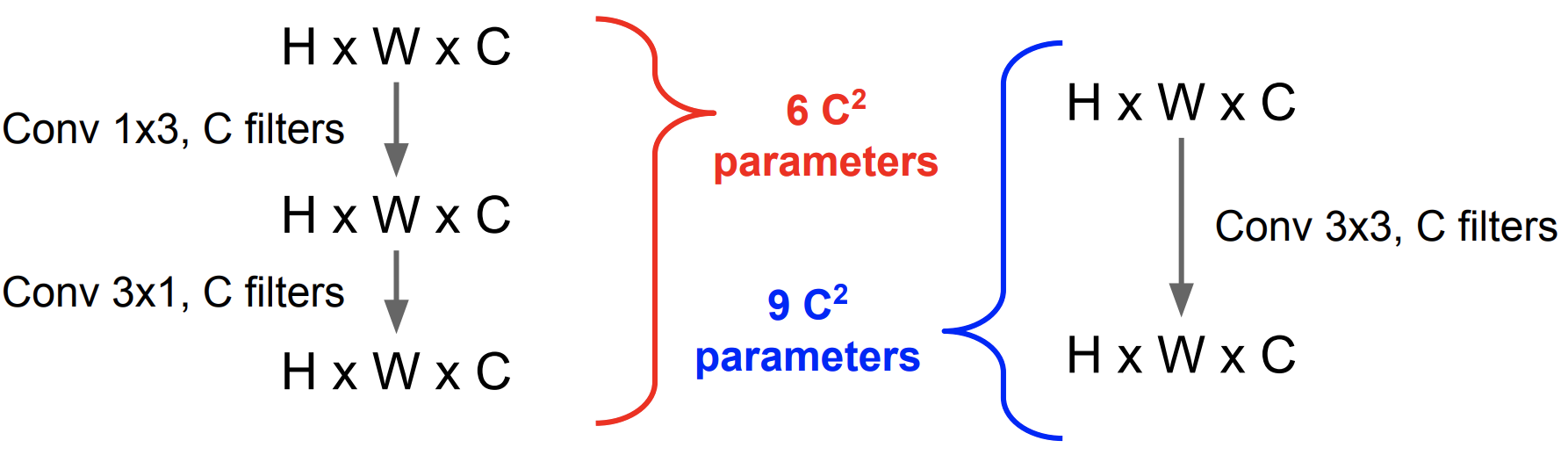
💁🏻 위에서 보이다 싶이 Parameter 수량이 더 적어져 연산이 가벼워짐 (+ 더 깊은 층으로 인한 non-linearity 강화)
-
사용된 사례 : GoogLeNet
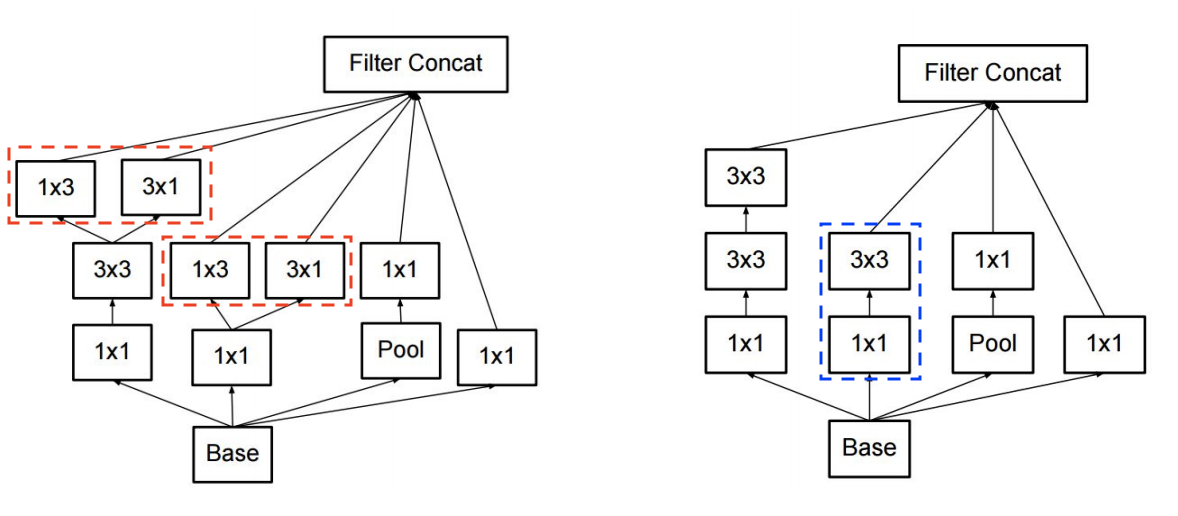
Computing Convolutions
im2col
-
다차원의 데이터를 행렬로 변환하여 행렬 연산을 하도록 해주는 함수
-
다차원 데이터의 합성곱(convolution) 결과 == im2col을 통해 행렬로 변환된 데이터의 내적 결과
- 입력 데이터(4x4x3)를 행렬로 변환
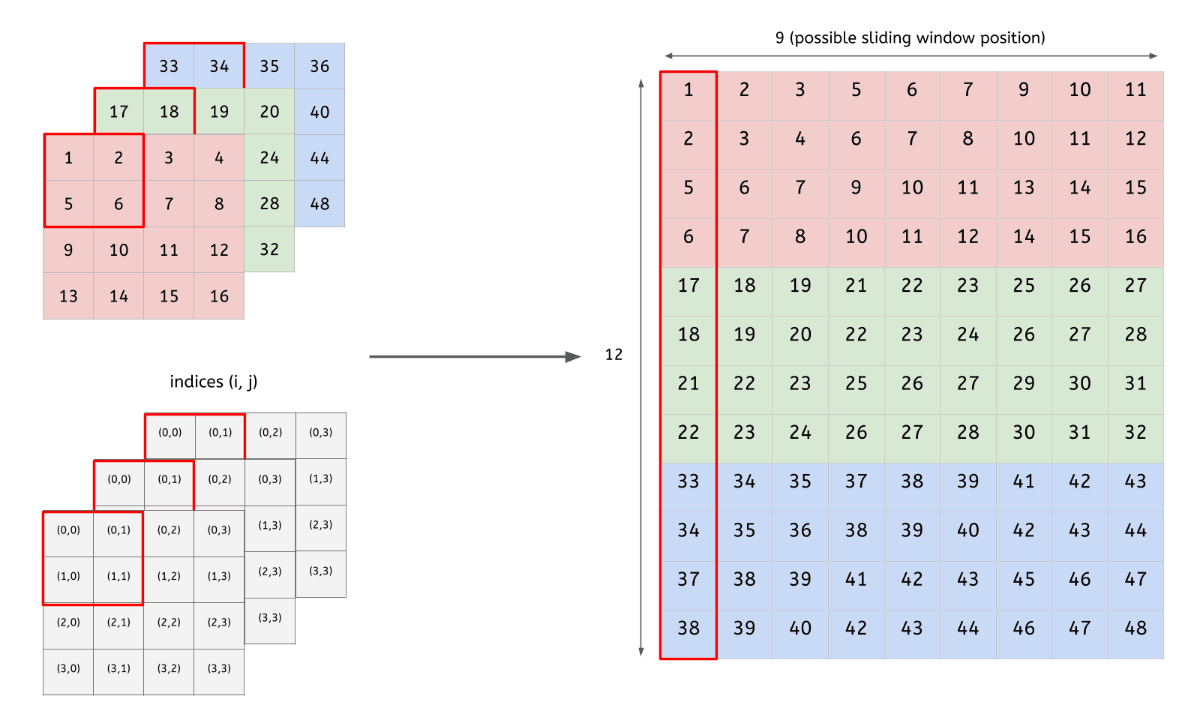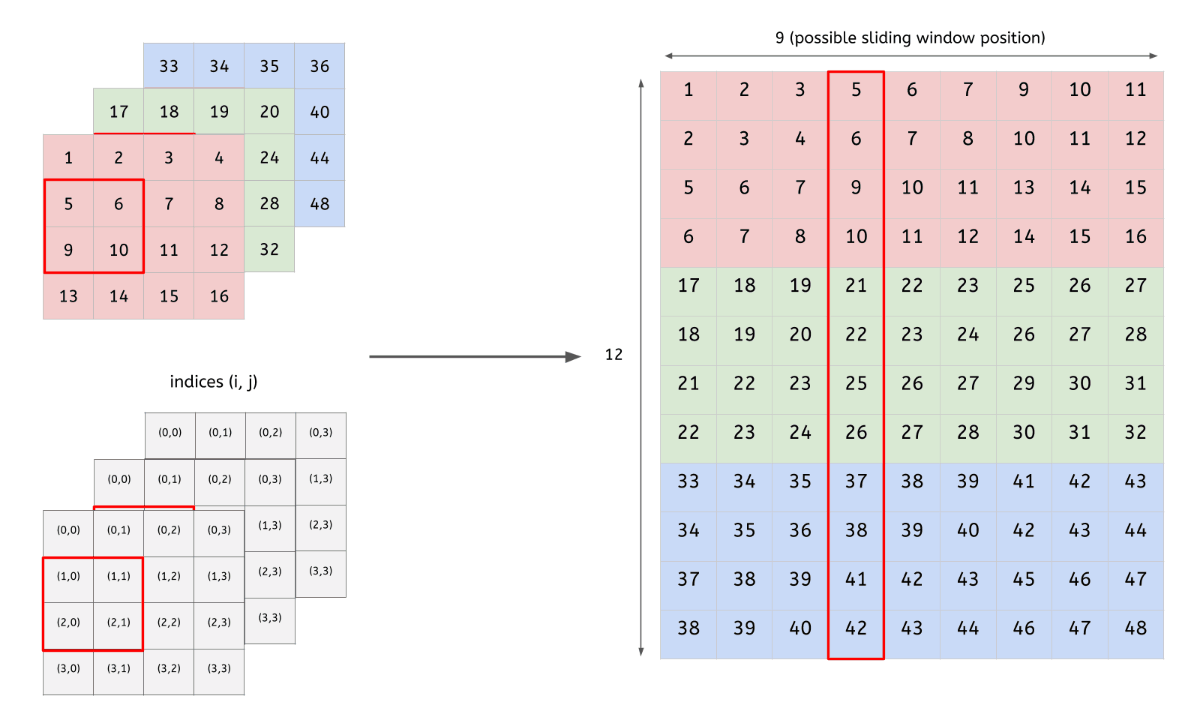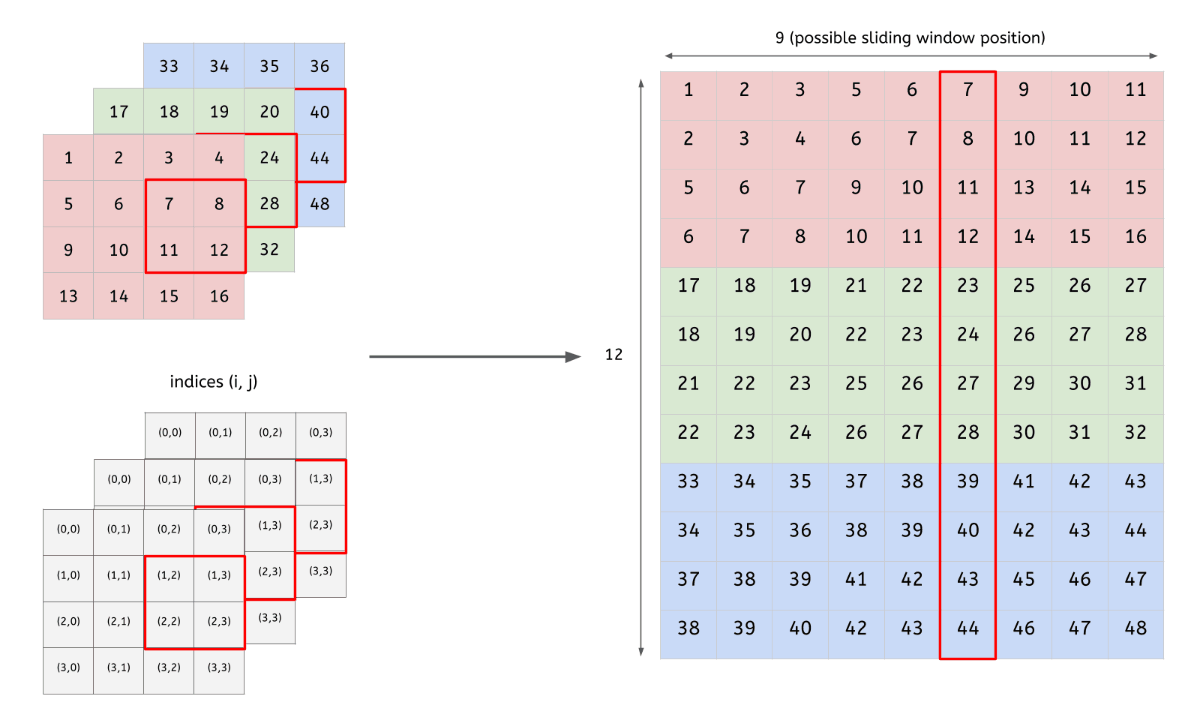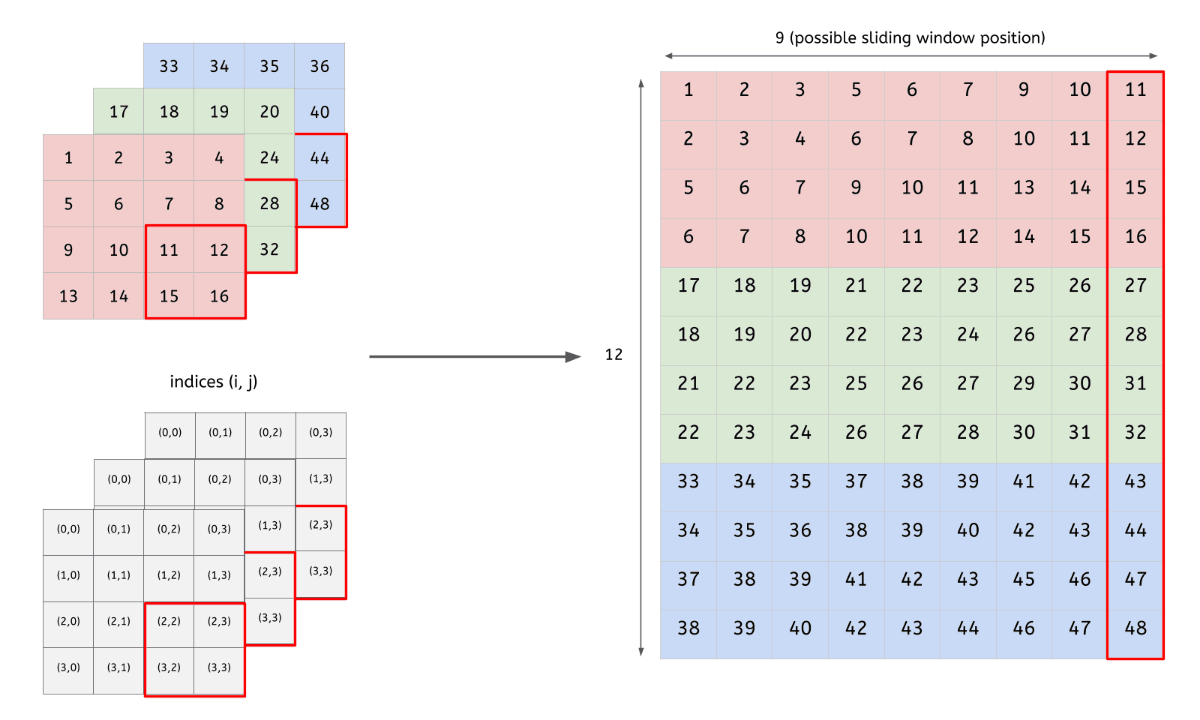
- 2개 filter(2x2x3)도 행렬로 변환
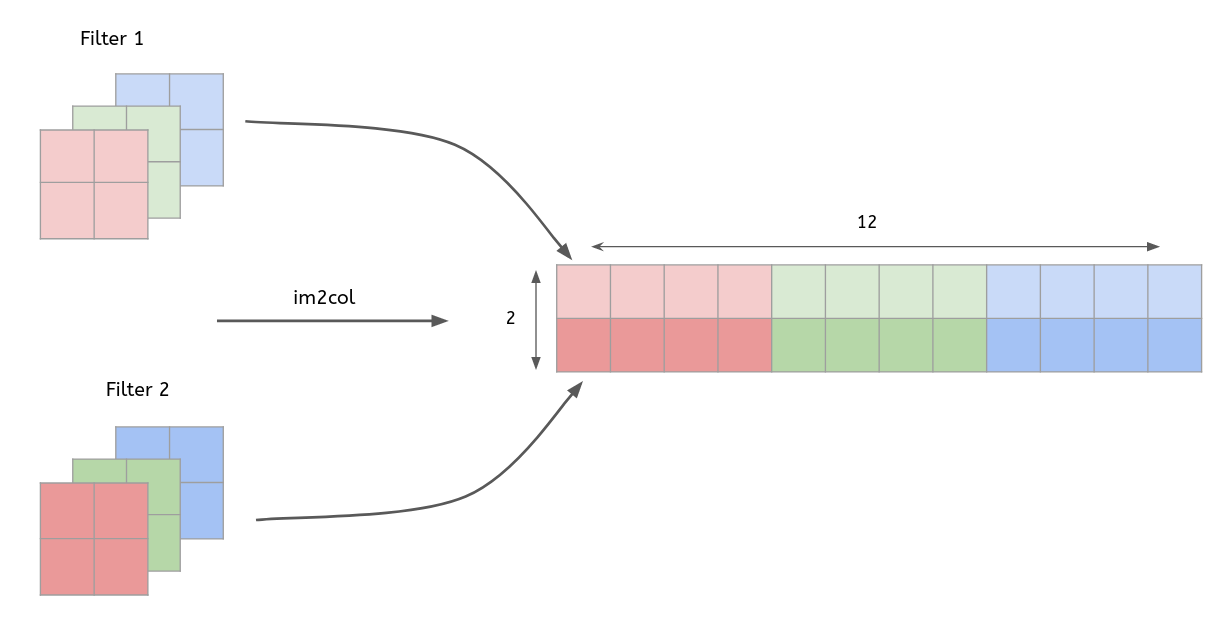
- 변환한 두 행렬의 곱
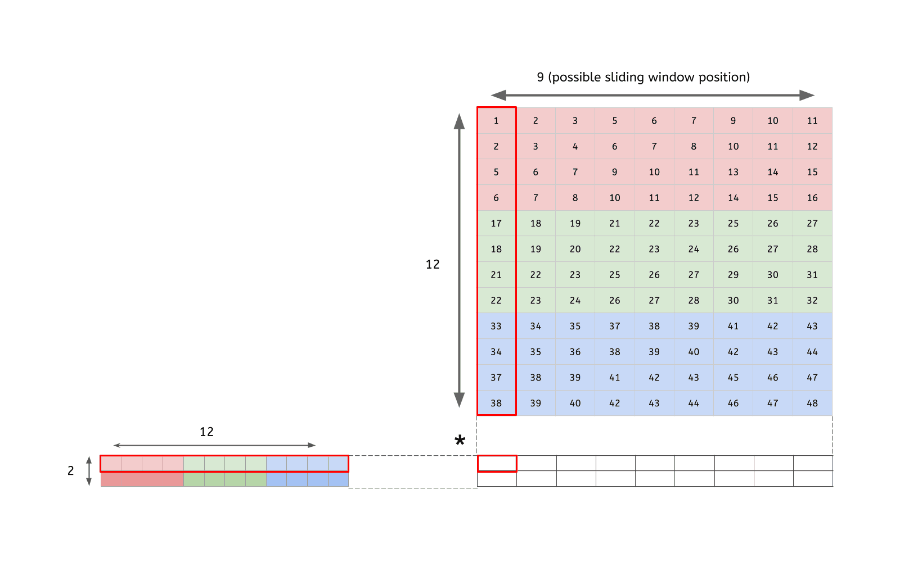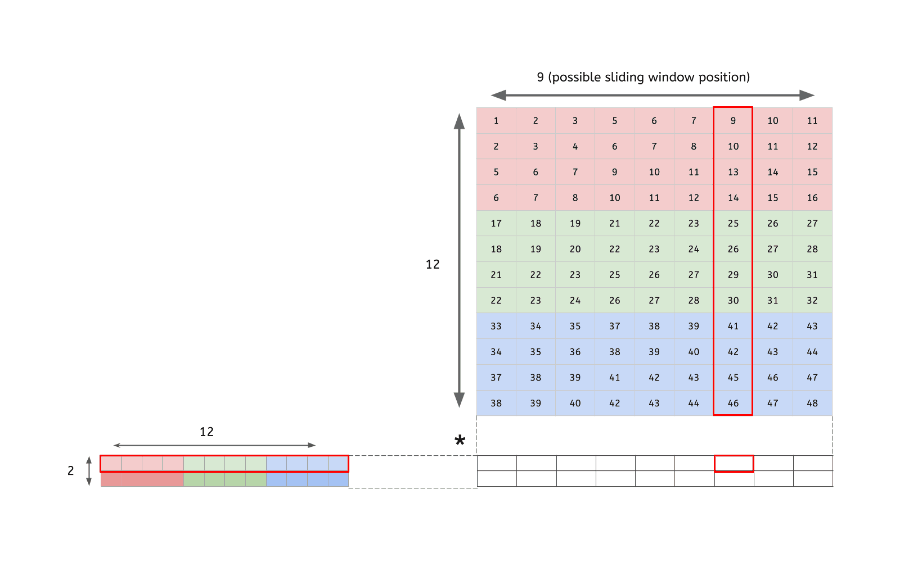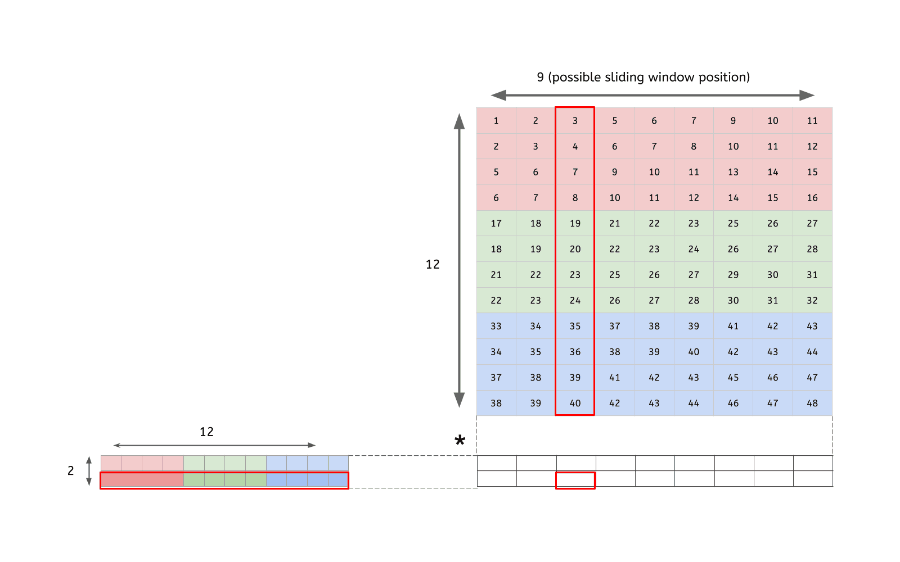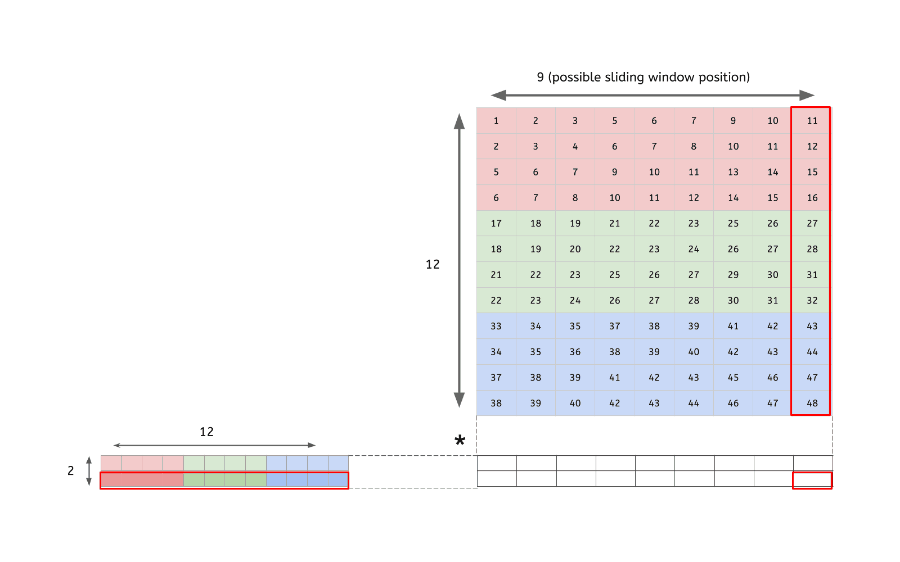
- 행렬로 변환한 입력 데이터와 필터의 행렬 연산 이후, 우리는 출력된 데이터(행렬)를 다시 원래의 데이터(3차원)로 변환해주는 작업을 해야됨
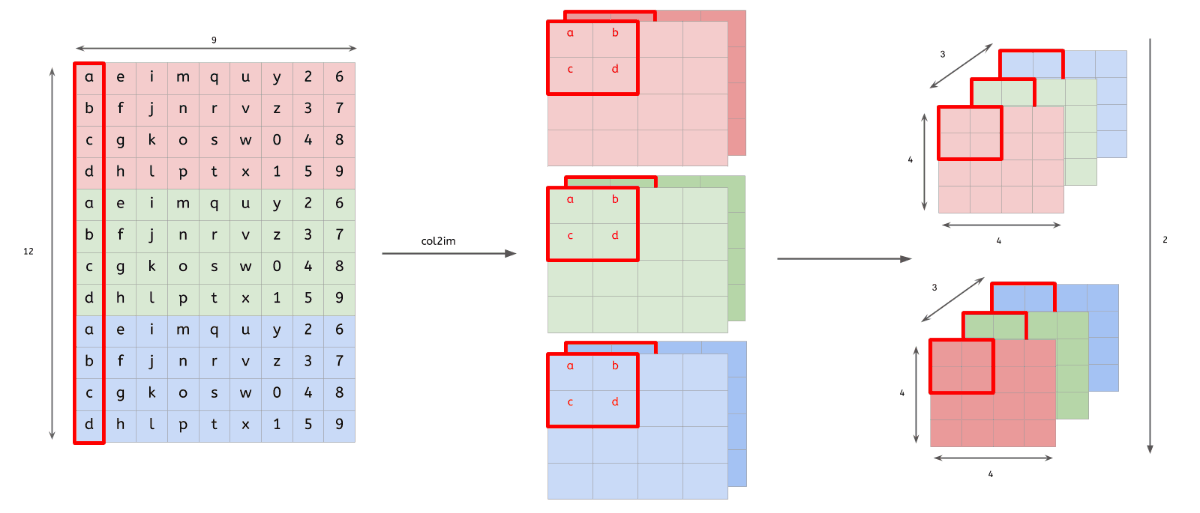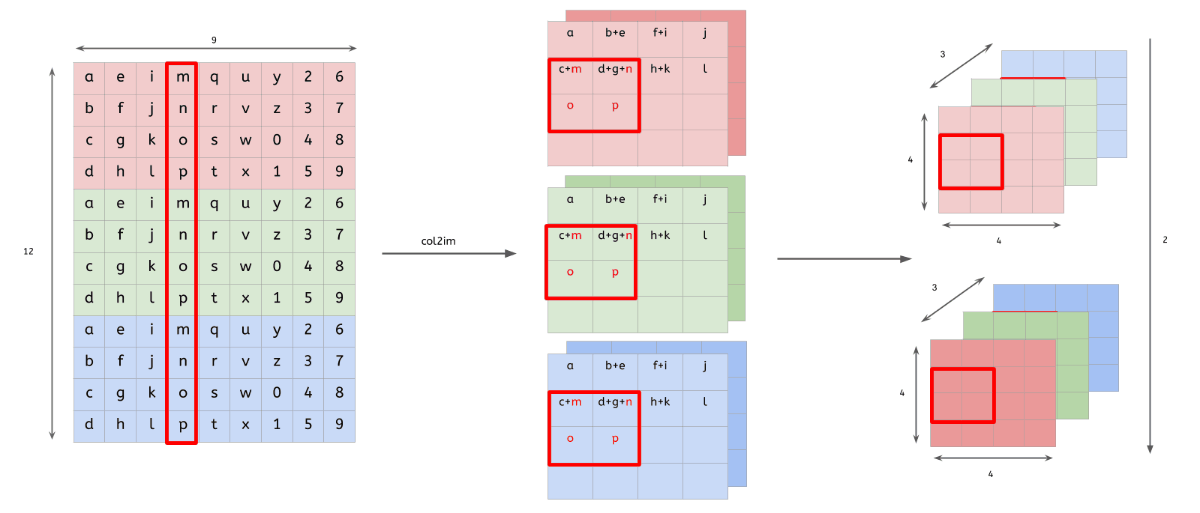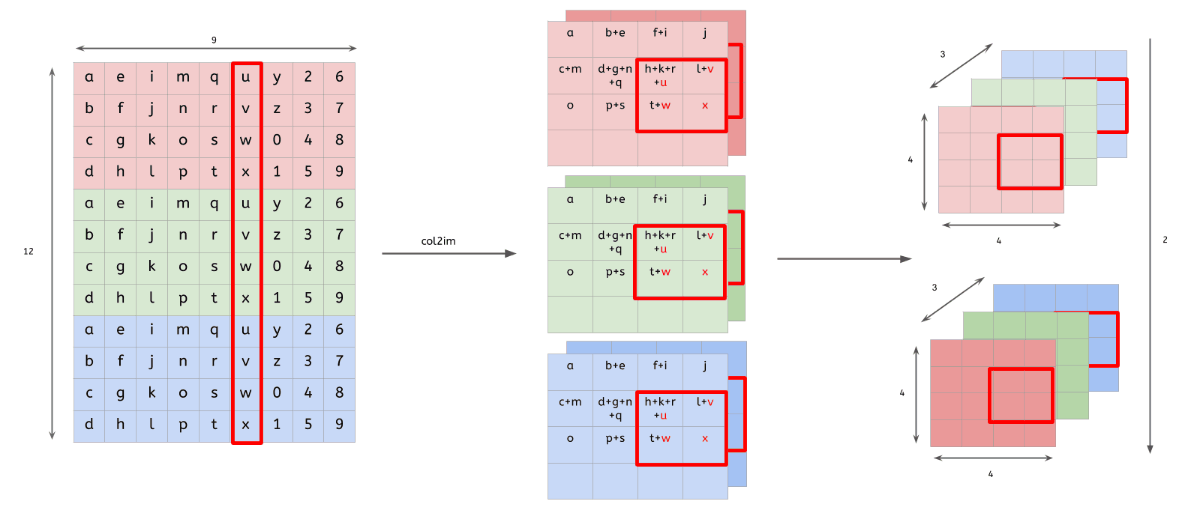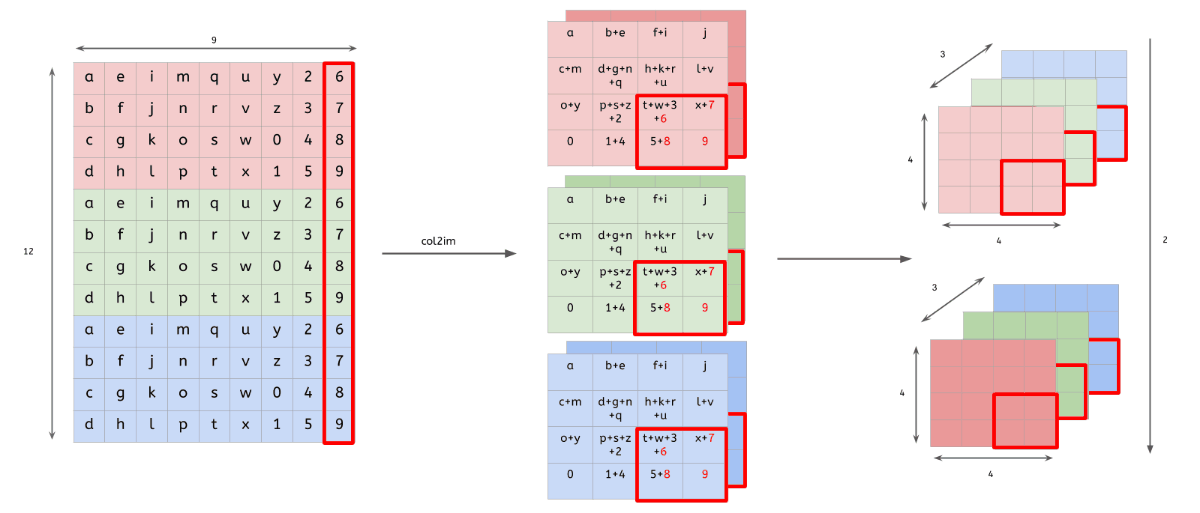
-
im2col를 사용하면 연산 속도는 빠르다.
- 하지만 연산해야하는 데이터 수가 늘어났기 때문에 연산 메모리가 증가한다는 단점도 존재한다.
Fast Fourier Transform (FFT)

- Filter가 클 경우(7x7) 효과가 상당히 있지만 Filter가 작을 경우(3x3) 효과가 그다지 크지 않음
Fast Algorithms
- Strassen’s Algoritm을 사용하여 matrix multiplication 복잡도를 줄임
- Details : Paper
Floating point precision
-
일반적으로 프로그래밍에서는 64bit (double precision)가 default
-
성능 향상을 위해 32bit (single precision)를 사용할 수 있음
-
요즘 16bit (half precision)도 지원하는 library 도 있음
- 하지만 Floating point precision 문제가 발생할 수 있음
- 16bit (half precision)로 Training과 Testing를 할 경우 error률이 발산함
- Stochastic rounding 방법 : parameter 와 activation을 모두 16bit로 일단 생성한 다음 곱셉연산이 일어나는 경우에 더 높은 bit로 잠시 올려 줬다가 곱셉연산이 끝나면 다시 낮추는 방식
- Stochastic rounding 를 적용했을 때 error률이 수렴하는데 성공을 함
-
2016년에는 parameter 와 activation을 모두 1bit로 학습을 시키는 모델을 제안함 (BinaryNet)
-
모든 parameter 와 activation는 +1 또는 -1 로 설정
- 단, gradient는 좀 더 높은 precision을 사용함
-
Bitwise XNOR 연산을 활용해서 빠른 곱셉을 수행함
-
《Reference》