File System
Files and Directories
- File : A named collection of byte stored on disk
- 사용자와 OS가 File을 보는 관점의 차이
- 사용자 입장에서는 Byte Sequence이지만
- OS 입장에서는 Block Sequnece이다 (Disk는 Block device이고 Block 단위로 I/O activity가 발생함)
- Naming : Disk 위에 만들어논 File을 Addressing 할 수 있게 만드는 것
- File Descriptor : File의 내용에 접근하기 위해 필요한 Meta data들을 저장하는 자료구조
- File system이 해야될 일은 text name을 File Descriptor id로 바꾸는 역할을 해야됨
- File이 살아있는 한 File Descriptor도 Storage에 저장됨, 물론 OS가 File Descriptor를 자주 access해야되서 copy본을 Main memory에다가 저장함
- 성능 향상을 위해 File Descriptor의 복사본을 Main memory에 유지할 때 발생하는 부작용 : Disk와 Main memory에 저장된 File Descriptor의 값이 달라질 수 있음
- Meta data들 : file의 크기, file 최근 access 시간, file 접근 기능 등…
- inode(Index node) :
- Unix의 File System에서 File Descriptor
- File System volume단위의 unique한 이름이다 (즉 Disk storage에서 inode를 0번부터 부여하고 Flash storage에서도 inode를 따로 0번부터 부여함)
- Volume(Logic Drive) : 단일 File system으로 관리되는 저장 장치 상의 영역
- File을 access할려면 먼저 File Descriptor를 access하고 File content를 access 해야 된다
- File Descriptor들을 Disk의 특정 영역에 모아두면 성능 저하가 발생하는 원인 : Disk 상에서 File Descriptor와 File content사이의 물리적인 거리가 멀기 때문에 Disk의 Seek Time이 증가함
- 요즘은 File Descriptor들을 가급적 File content 근처에 흩어놓는다. 그리고 깨질 경우 복구할 수 있게 copy를 여러개 유지함
- File Descriptor들을 Disk의 특정 영역에 모아두면 성능 저하가 발생하는 원인 : Disk 상에서 File Descriptor와 File content사이의 물리적인 거리가 멀기 때문에 Disk의 Seek Time이 증가함
-
Directory (Folder) : File들 또는 Subdirectory를 가지고 있는 entity. 내부적으로 file과 똑같이 처리함
-
Directory file의 content : (text file name, file id) pair data를 받음

-
-
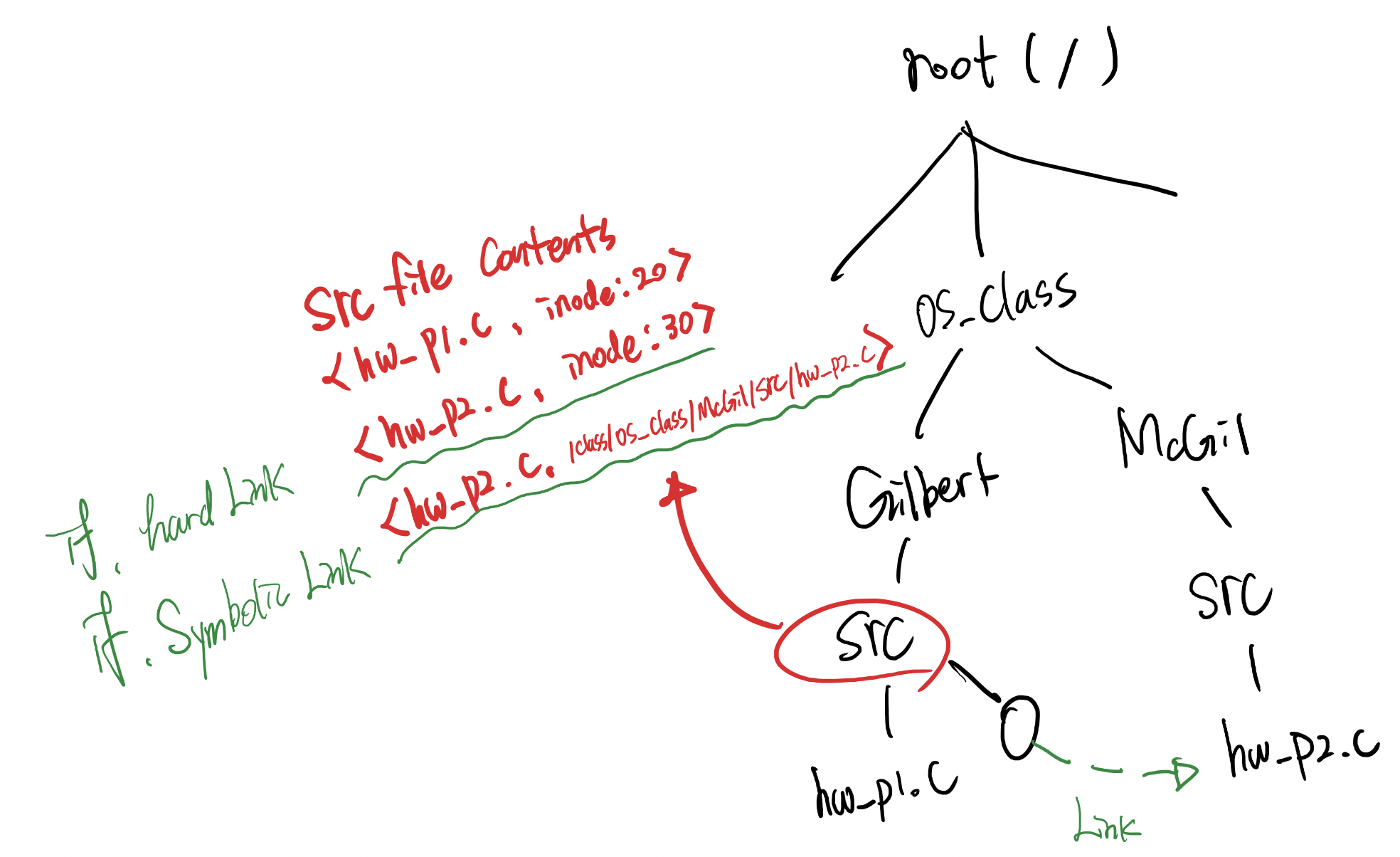
Link : Unix나 Linux File System에서 실제 File이나 Directory 혹은 또 다른 Link를 가리키도록 연결해 준다는 의미
-
Windows의 ‘바로 가기’나 단축 아이콘을 연상할 수도 있지만, 바로 가기나 단축 아이콘이 단순히 File 관리자가 담당하는 기능인 반면, Linux의 Link는 File System 차원에서 제공된다는 근본적인 차이가 있다
-
link를 사용하는 이유 : disk공간의 효율적인 사용에 있다
-
예를 들어 copy를 하게 되면 똑 같은 data block이 하나 더 생기는 반면에 link는 link된 두 파일이 하나의 data block을 포인트 하고 있기때문에 disk 공간을 절약할 수 있다
-
Soft Links (symbolic links) :
- 원본 파일의 이름을 가리키는 링크로 원본 파일이 삭제되면 사용 불가능하다
- symbolic link는 서로 다른 file system으로 link를 할 경우에 사용 (같은 file system내에도 가능)
-
Hard Link :
-
원본 파일과 동일한 inode 를 가지며 원본 파일이 삭제되더라도 링크 파일을 여전히 사용 가능하다
-
hard link는 같은 file system내에서만 file link가능 (inode가 File System volume단위의 unique한 이름이기 때문에)
-
-
Big Picture on File System

-
File System은 Kernel의 하나의 Subsystem이고 다음과 같은 주요 기능을 가지고 있다
- Logical file name을 Physical address로 변환시키는 역활
- 사용자의 데이터를 저장 장치로 부터 읽어오거나 저장장치에 기록하는 역할
-
Views on File
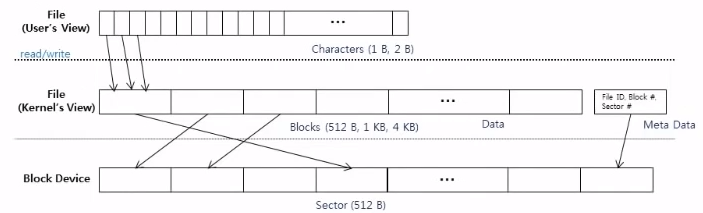
- User level에서 file content라 하는 것은 file 단위의 sequence of byte이다
- Kernel level에서는 file content라 하는 것은 file안에 존재하는 sequence of block이다. 그리고 meta data를 가지고 있고 이거를 File Descriptor(inode)라 한다
- Block device로 가면 sector들의 번호로 변화하게 된다
-
File System in the Kernel (UNIX OS)
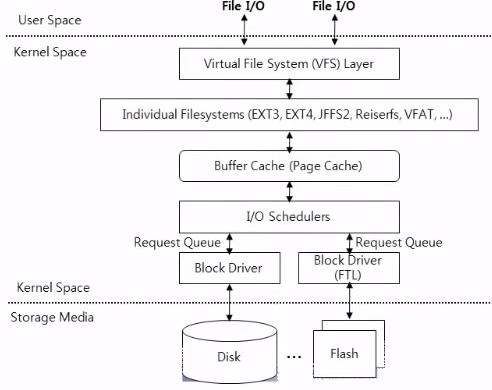
- VFS : 특성이 다른 여러 File System이 UNIX OS에 공존하는데 이것들을 uniform하게 사용자한테 나타내기 위해서 필요함
- Buffer Cache : 최근 접근한 File의 Data Block내용을 Main memory에 저장해 두는 공간. Disk로 부터 한번 읽어온 File의 내용에 다시 접근할 때, 빠르게 읽어올 수 있게 한다
- I/O Schedulers 부터 Disk의 device driver가 된다
File Structure
-
Data 접근 패턴
- Sequential Access
- Random Access : 저장된 file을 찾을려고 할 떄
- Keyed Access : 특정을 값을 통해 block을 검색 할 때 (OS에서는 처리
 )
)
-
File Structure 구조를 결정하는 요소는
- Sequential Access와 Random Access를 효율적으로 지원해야된다
- 작은 File과 큰 File을 모두 효율적으로 지원해야된다
-
과거 Fil system 구조
-
Linked files (70년대)
-
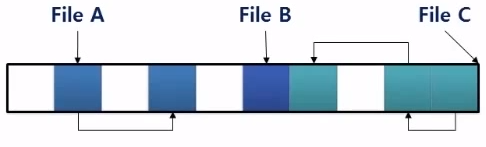
File이 하나 생기게되면 Disk storage에 그 file을 저장하기 위해 Block들을 할당해야됨. 가장 원시적인 방법은 필요한 Block을 연속적으로 Disk storage에 할당함
-
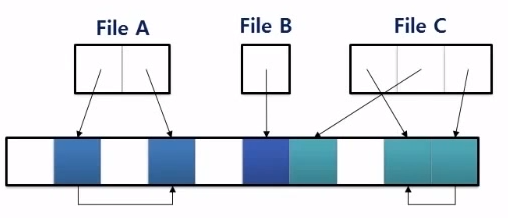
File에 Access하기 위한 방법 : 해당 File Descriptor에 기록된 File의 첫 번째 Block의 주소를 통해 File에 접근
-
Example. File C의 3번째 Block을 읽는데 필요한 Disk Access 횟수
- File C의 Discriptor를 읽어옴 (File C의 첫 번째 Block의 주소를 알아냄)
- File C의 첫 번째 Block를 읽어옴 (File C의 두 번째 Block의 주소를 알아냄)
- File C의 두 번째 Block를 읽어옴 (File C의 세 번째 Block의 주소를 알아냄)
- File C의 세 번째 Block를 읽어옴
-
Sequential Access는 문제가 없지만 Random Access에는 많은 seek가 필요함
-
Fragmentation 문제가 있음
-
-
Indexed files
-
File Descriptor 안에 Index array가 있어서 그 file이 가지고 있는 block에 대한 pointer들을 가지고 있음
-
Linked files에 비해 Sequential Access와 Random Access 모두가 편하다
-
한 File의 크기가 Index의 개수 만큼 제한이 된다는 문제가 있음
-
Indexed file이 UNIX OS에서 사용됨
-
4.3 BSD OS의 File Structure :
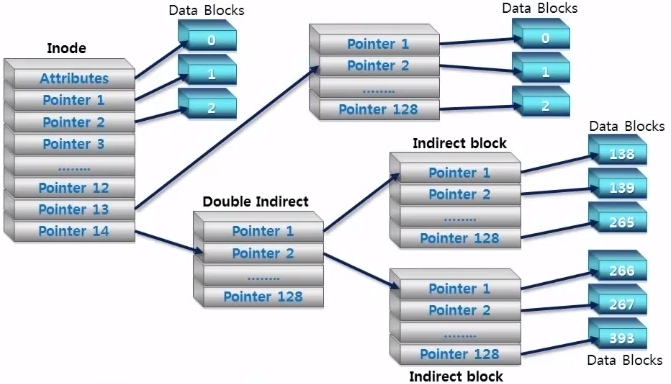
Double, Triple indirected Index block을 만들어서 File size가 큰 것도 수용할 수 있음
대신 File size가 커지면 Data를 access하기 위해서 더 많은 seek가 필요함
-
-
-
관련된 Mechanism
- Buffer cache : read/write system call한 횟수만큼 device driver가 동작하는 것이 아니라 많은 경우 device driver에 가지 않고 Buffer cache에서 hit가 나서 file operation이 처리가 됨
- Bit map : Disk의 Block들에게 전부 1 bit를 map시켜놓는다. 그 Block이 free하면 1이 할당되고 그 Block이 이미 사용되고 있으면 0이 할당됨. (ex. file하나가 6개의 block이 필요하다면 Bit map에 “111111” string을 search해서 거기다 할당하면 된다)
Disk Space Management
-
Disk Space Management : File이 생성되거나 확장될 때, 어떻게 Disk Sector들을 File에 할당해 줄 것 인가를 결정
- Disk Space를 효율적으로 사용, 가급적이면 overhead가 적게, Disk access의 속도가 빠르게 allocation 하는 것, 필요하면 여러 user들이 space를 공유할 수 있게
-
File System이 가져야될 기능들 :
[1] Disk Space Management
[2] Naming
[3] Protection
[4] Reliability
-
Disk Space allocation policies
- Contiguous allocation :
- Fragmentation 문제가 있으며 현재는 잘 활용하지 않음
- Block-based allocation
- Extent-based allocation :
- Block들을 group으로 묶고 각 group에 semantics를 부여함으로써 최적화를 달성하는 정책
- Contiguous allocation :
Evolution of UNIX File System
-
UNIX File System의 진화
[1] System V file system (s5fs)
-
하나의 Disk driver위에다가 volume을 하나 또는 여러개를 만들 수 있다. 그리고 File system은 Volume당 하나가 존재한다.
-
block size는 그 당시 Disk drive의 sector size를 기준으로 512 또는 (512)^2, (512)^3 Byte 등등.
-
sector들의 Linear array = block array 이며, File System이 allocation을 할 때 관점을 두는 storage는 block array이다
-
block array 실제적인 모습

- Boot Area (0번 Block) : Computer Booting 시 실행되는 Program인 Boot Loader가 저장되어 있는 공간
- SuperBlock : 이 Volume에 들어있는 File System에 대한 모든 Meta data가 들어가있음 (ex. inode의 개수, 전체 block의 개수, free한 inode의 개수 등등 )
- inodeList : 어떤 File이 Create되면 여기 inodeList에서 하나 inode를 가져다가 거기 meta data를 기억함
- Data blocks : 나머지 Data들이 모두 저장됨
-
문제점 :
- 성능상의 문제 :
- File의 inode와 Data Block간의 물리적인 거리가 멀기 때문에 File 접근시 과도한 Seek Operation이 발생
- Data Block의 할당/해제를 반복할수록 Free Block이 산재하게 되어 Sequential Block을 읽을 때 과도한 Seek Operation이 발생
- 안전성의 문제
- SuperBlock이 한 곳에만 저장되어 있기 때문에 손상될 경우 File System을 사용할 수 없음
- 성능상의 문제 :
[2] Berkeley fast file system (FFS) – often called Unix File System(UFS)
-
s5fs의 성능저하의 문제를 개선함
-
Cylinder :
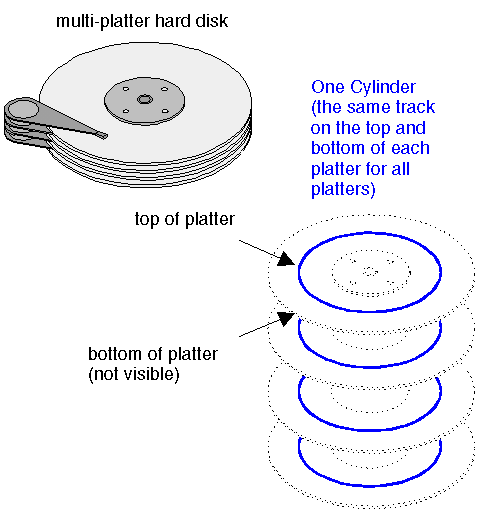
-
Cylinder group : 인접한 Cylinder 몇개를 묶어서 group화 시킴
-
가급적이면 logical related information들은 다 Cylinder group에 몰아 넣는다 (즉, 같은 directory에 있는 모든 file들의 inode와 content들을 동일한 Cylinder group에 넣는다)
 성능상의 문제 해결
성능상의 문제 해결 -
Cylinder group마다 SuperBlock을 다 둔다 (한 track 또는 한 Plate가 날라가도 정보를 회복할 수 있게 잘 배치함)
안전성의 문제 해결 -
Block외에 Fragment라는 더 작은 개념을 도입 (Fragment = sector), allocation는 Fragment단위로 일어남
- 여러 개를 할당해야되는 경우, Fragment를 여러개 묶어서 Block의 크기를 더 크게 잡기도 함
-
File size가 커서 한 Cylinder group에 다 몰아넣을 수 없는 경우, 인접 Cylinder group에 넘기게 된다
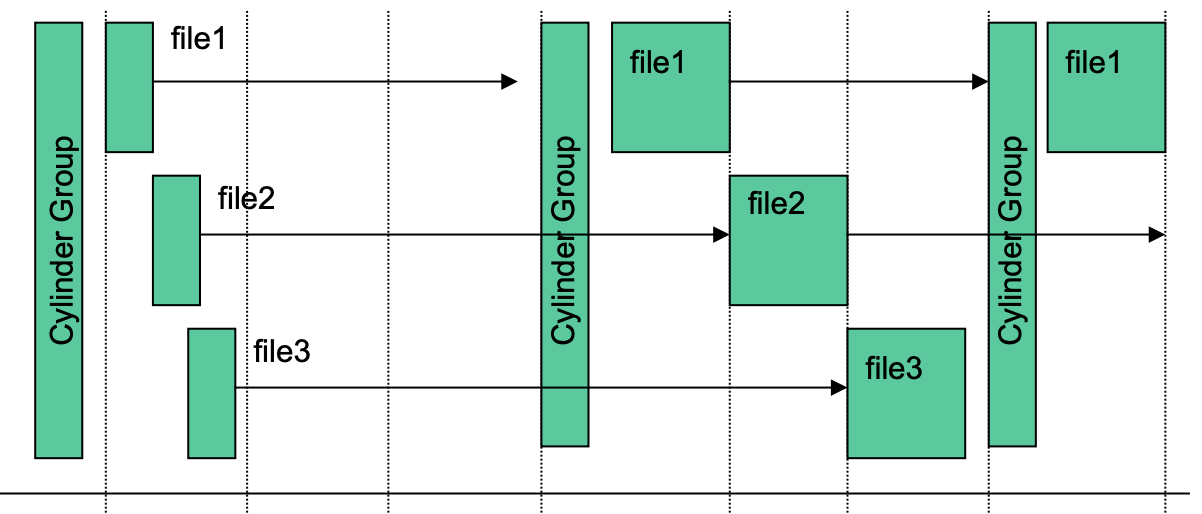
- 하나의 Cylinder group에는 작은 size의 초기 block들을 담게 되고 그게 커지면 인접 Cylinder group에 넘기게 된다
- 옆에 Cylinder group로 넘기는 기준은 48KB (왜냐하면 48KB까지는 Direct index로 fast access가 가능해서)
-
Rotational delay도 최적화 시켰다
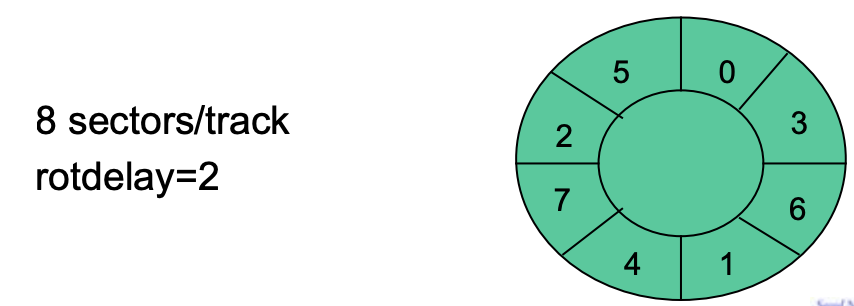
- rotdelay = 2로 설정했으면, 2 sector를 보낸 만큼의 시간이 보장되야됨. 그래서 Disk에 data를 저장할 때 2개 sector를 뛰어서 배치한다
-
물리적 제약들을 해소함
- s5fs에는 file 이름으로 14 character 밖에 사용할 수 없었음, 한 File system이 64K개 만큼의 file만 contain할 수 있었음
- 그래서 file 이름을 256 character 로 지원함
- Symbolic link를 지원함
- Disk Quota개념도 추가
-
Read/Write 성능이 뛰어나게 되면서 Disk space의 효율성은 떨어지지 안았음
-
문제점 :
- Data Block이 흩어져있어 있는 문제가 존재
- Crash recovery 시간이 너무 오래걸림
[3] Sun’s network file system (NFS)
- 분산 프로그래밍, 소켓 프로그래밍, RPC 개념이 생기면서 network file system이 개발되는데 가장 대표적인 file system
[4] Sun’s virtual file system (VFS)
- Virtual file system : File System이 너무 많아져서 user interface를 단일화하기 위해 만든 Software Layer
[5] Log-structured file system (LFS)
- Disk의 Volume size가 커지고 Recovery의 overhead가 심각한 문제가 되서 나온 새로운 file system
- FFS에서의 Crash recovery를 쉽게 만듬
- 기존의 File System은 Rewrite operation이 일어나면 그 content를 invalidate시킨 다음에 새로운 Block을 받아서 그 Block을 올바른 index 구조안에 넣는다. Log-structured file system은 새로 생성된 정보만 file 뒤에다가append한다.
- modification이 일어나면 뒤에다 껴넣기 때문에 앞에 Invalidate된 Data Block들이 많이 생겨서 이것들을 collect해야되는 Garbage collection이 필요하다
- Log-structured file system을 사용하게 되면 갑자기 System이 확 꺼졌다고 해도 Log들이 뒷부분에 남아있기 때문에 System이 Reboot하게 될 때 그 Log들만 다시 수행을 시켜서 File System을 reconstruct하면 됨
- Smartphone의 flash storage가 있는데 flash drive의 file system은 예외없이 Log-structured file system로 구현이 되어있음 (Flash는 Erase-before-write라는 제약 때문에 LFS를 쓸 수 밖에 없음)
-
Disk Scheduling
-
I/O Request : 몇 번째 Plate에 몇 번째 Track에 몇 번째 Sector를 읽어라 같은 명령
-
Request Queue : Disk에 대한 I/O Request를 저장하는 Queue
- Request Queue는 Device Driver와 Device사이에 존재하면 된다
-
I/O Scheduler : Request Queue의 순서를 reordering하는 것
- I/O Scheduler는 Device Driver의 한 부분으로 들어있게 됨
-
Scheduling Policies
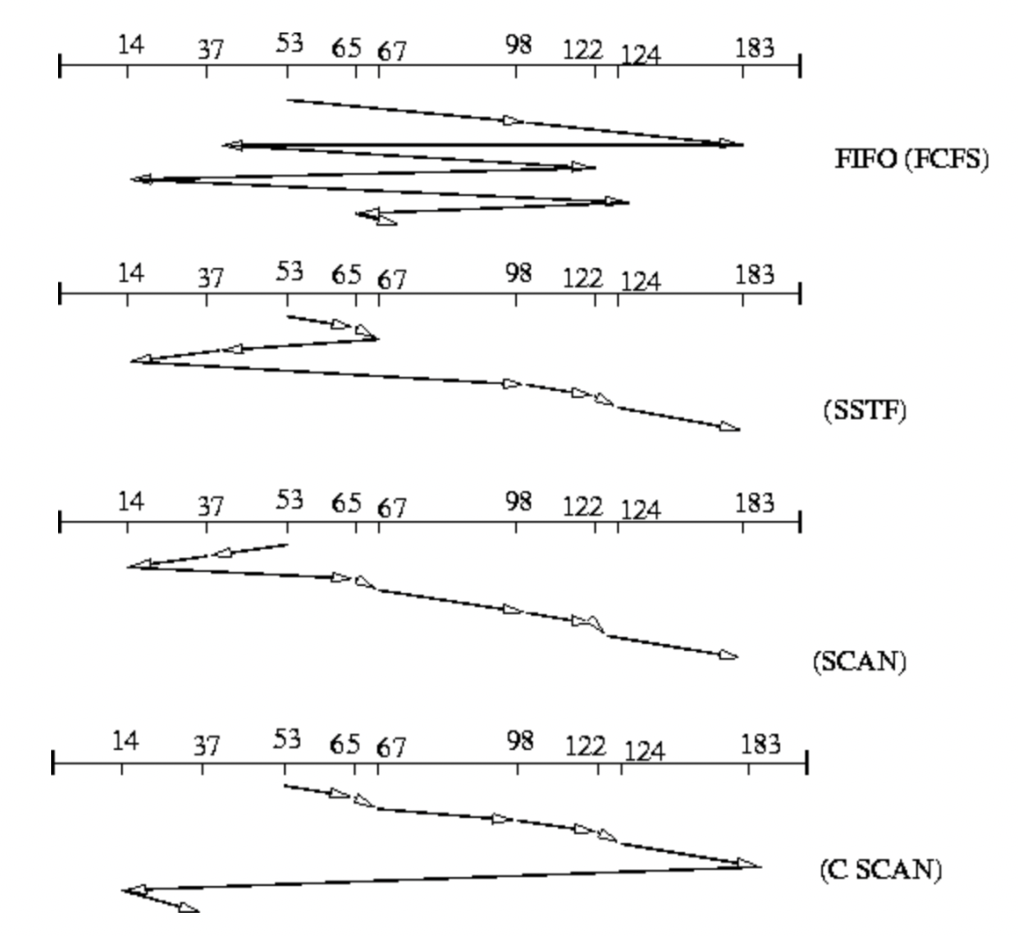
[1] First Come First Served (FIFO)
- 성능이 별루
[2] Shortest Seek Time First (SSTF)
- Handle nearest request first
[3] Scan (Elevator)
- Disk Arm을 한 방향으로 쭉 움직이고 거기에 중간에 걸리는 Disk operation을 처리하고 다시 돌아오면서도 Disk operation을 처리
- 문제점 : 한 Circular scan에 중간 track들은 2번씩 기회가 주어지지만 양쪽 끝 Track은 1번씩 기회가 주어짐
[4] Circular scan
- Scan (Elevator)의 문제점을 개선한 policy
-
Disk Arm을 한 방향으로 쭉 움직이고 거기에 중간에 걸리는 Disk operation을 처리하고 바로 다시 처음으로 돌아옴
-
Example. Request queue : 98, 183, 37,122,14,124,65,67 (Head starts at 53)
- Flash Drive같은 경우 Disk보다 복잡한 Scheduling이 필요함
《Reference》