C언어 : Array
-
C언어에서 Array는 기본 상수 시간 내에 Read, Write를 다 수행할 수 있다
- Array 선언
int A[4] = {2,4,0,5};-
Array A : (2) (4) (0) (5)
- 배열의 각 원소는 4개의 byte로 구성됨
-
변수 A : 배열 A가 시작하는 첫 번째 원소 A[0]의 주소가 저장되어있음
-
Data Read/Write :
A[2] = A[2] + 1;-
A[2]의 값 읽기-
A[2]의 주소 =A[0]의 주소 + (2 * 4 byte)
-
- 읽어드린
A[2]값에다 + 1 산술하기 - 산술한 값을
A[2]에 쓰기
-
-
int A[4] = {2,4,0,5}; A[4] = 10; // Error // 정수 6개를 담을 수 있는 용량의 메모리를 연속적으로 할당해서 그 시작주소를 B에게 줌 B = (int*)malloc(6*4); // A에 있는 데이터를 B에다 copy for(int i=0; i<(int) sizeof(A); i++){ B[i] = A[i]; } // A는 원래 4개만 받아드릴 수 있는 배열에서 6개를 받아드릴 수 있는 더 큰 배열이 됨 A = B-
malloc(): Memory allocation function -
C에서는 배열을 선언할 때 크기를 정해야되고, 더 크거나 작은 배열이 필요할 경우 메모리 할당함수를 써서 프로그래머가 직접 코드상에서 조정을 해줘야 된다
-
Python : List
-
C언어에서 Array 보다 여러 가지 연산제공해서 편의성의 높음
-
List 선언
A = [2,4,0,5] -
List A : (객체1 주소) (객체2 주소) (객체3 주소) (객체4 주소)
- 실제 data 값들이 객체로 따로 메모리에 저장됨 (ex.
2= 객체1,4= 객체2 … )
- 실제 data 값들이 객체로 따로 메모리에 저장됨 (ex.
-
Data Read/Write :
A[2] = A[2] + 1;-
1이라는 데이터가 객체로 새로 생성됨- 원래
0이라는 객체는 사라지지 않음
- 원래
-
A[2]가1이라는 객체를 가르키게 됨
-
-
기타 연산들 :
-
A.pop(1): A[1] 를 제거하고 returnList A : (객체1 주소) (객체2 주소) (객체3 주소) (객체4 주소)
 (객체1 주소) (객체3 주소) (객체4 주소)
(객체1 주소) (객체3 주소) (객체4 주소)
-
-
-
배열 용량 자동조절 (Dynamic array)
-
List class의 내부구조 :
class List{ capacity // 총 array slot의 개수 n // 현재 저장된 값의 개수 array[] // 실제값 저장 } -
A.append(x)의 간단한 동작과정 :
if A.n < A.capacity: A[n] = x A.n = n+1 else : // A.n == A.capacity 일 경우 B = allocate new list with size of (A.capacity * 2) for i in range(n): // A에 있는 값들을 B로 옮기기 B[i] = A[i] delete old list A A = B A[n] = x A.n = n+1 -
Array  List
List
-
Array는 고정된 크기를 갖는 같은 자료형의 원소들이 논리적 저장 순서와 물리적 저장 순서가 일치한 형태로 구성된 자료구조
-
Index가 유일무이한 식별자가 된다 (즉 검색 성능 👍)
-
Index에 따라 값을 유지하므로 원소가 삭제되어도 빈자리가 남게되어 메모리가 낭비된다
(처음 크기를 10으로 지정한다면 5개의 데이터만 저장하더라도 실제 배열의 크기는 10이다)
-
데이터 추가 삭제 발생시, 놀고 있는 저장공간이 생길수도 있고 중간 값의 데이터를 삭제 했을 경우 앞으로 당겨와야 한다든지의 문제점이 있어 불편
-
-
List 는 순서가 있는 데이터의 모임으로써 빈틈없이 데이터가 적재되는 자료구조
- Index가 몇 번째 데이터인지 정도의 의미를 가진다. (즉 검색 성능 👎)
- 포인터를 통하여 다음 데이터의 위치를 가르키고 있어서 데이터 추가 삭제가 쉽다.
Java : Vector, ArrayList, LinkedList
-
Java의 자료구조는 크게 Collection과 Map으로 나눌 수 있음
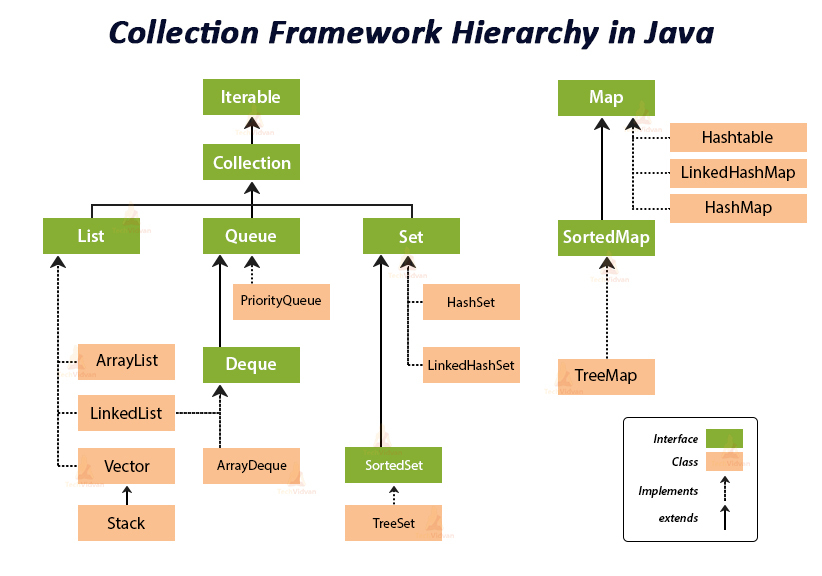
- Collection interface는 “내부에 포함되는 element는 순서를 가지면서 저장된다”
- Map interface는 “내부에 포함되는 element는 순서관계 없이 저장된다”
-
Collection.List의 도입된 순서
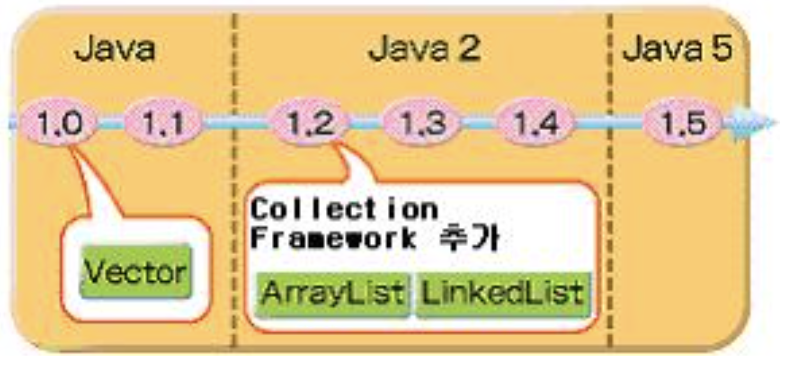
-
Vector
-
배열에 더 이상 저장할 공간이 없으면 보다 큰 새로운 배열을 생성해서 기존의 배열에 저장된 내용을 새로운 배열로 복사한 다음에 저장
-
각 데이터에 대한 Index를 가지고 있음
-
동기화를 보장해주어 공유 자원이나 복수의 사용자가 존재할 때 좀 더 안전하게 프로그램을 작성할 수 있다.
(하지만 하나의 Thread가 하나의 자원을 이용하는 경우에는 오히려 성능의 저하가 발생)
-
-
ArrayList
-
기존의 Vector를 개선한 것으로 Vector와 구현원리와 기능적인 측면에서 동일하다고 볼 수 있다.
-
Vector는 동기화가 이미 되어 있는 클래스고 ArrayList는 동기화처리가 안된 클래스
(Vector는 한 번에 하나의 Thread만 접근 가능, ArrayList는 동시에 여러 Thread가 접근 가능)
- ArrayList에서 여러 Thread가 동시에 엑세스 해야하는 경우 개발자가 명시적으로 동기화 코드를 추가하면 된다
-
검색 성능 👍
-
많은 데이터 추가 및 삭제 👎
-
-
LinkedList
- 다음 자료의 위치 정보를 가지며 내부적인 index를 가지고 있지 않음
- 많은 데이터 추가 및 삭제 👍
- 데이터가 많은 경우 검색 성능 👎
Python : Dictionary
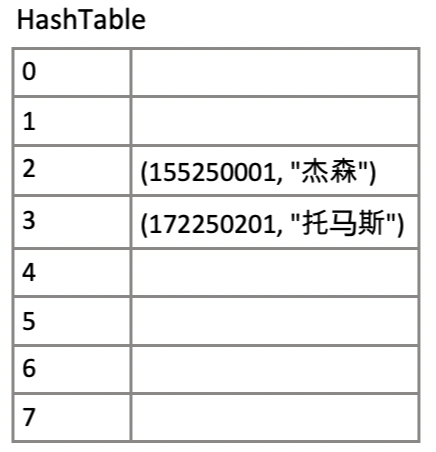
d = {}
d[155250001] = "杰森"
d[172250201] = "托马斯"
-
실제 Dictionary라는 자료구조가 파이썬 내부에서는 “Hash Table” 로 저장되어있음
-
Hash function :
hash("155250001"): 어떤 난수 (ex.1478382034)table_index = hash("155250001") % table_size -
Collision Resolution Method : Open addressing
perturb = hash("155250001") table_index = hash("155250001") % table_size while HashTable[table_index] is not empty : if HashTable[table_index].key == "155250001": # found it! else: table_index = (5*table_index + 1 + perturb) % table_size perturb = perturb >> 5 # 오른쪽으로 5 bit shift-
table_size = 2^k인 형태일 경우,
5*table_index+1방식으로 계속 Open addressing하면 모든 slot을 빠짐없이 한번씩 방문할 수 있음 -
Cluster : Hash Table에 연속적으로 몰려셔 저장되있는 상황
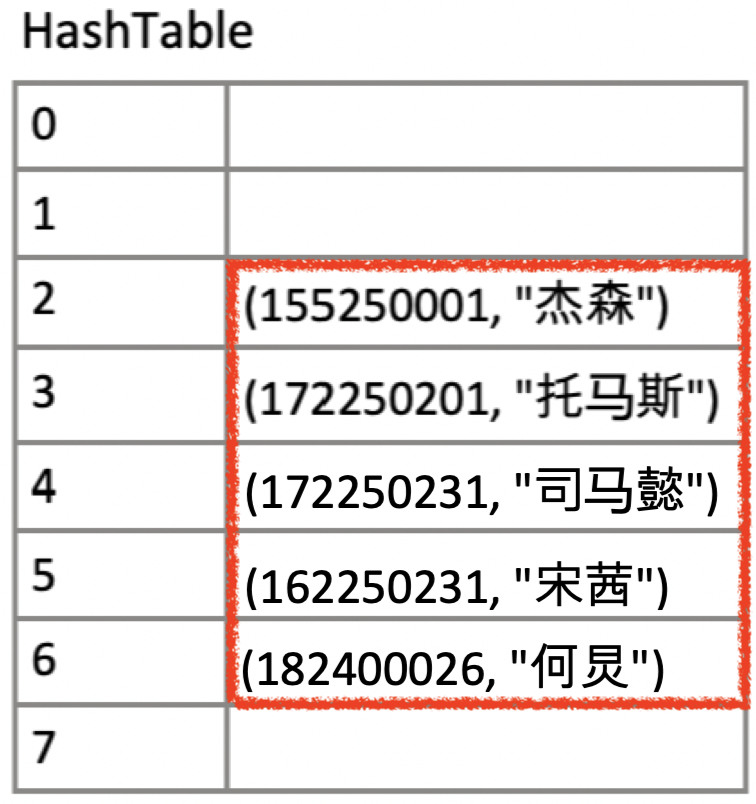
-
perturb: Cluster를 랜덤하게 점프할 수 있게 해주는 효과를 줌Ex.
perturb가 64bit일 경우, While loop를 12번은5*table_index+1+perturb으로 진행하지만 (만약 빈 slot을 못찾았다면) 13번째 부터는5*table_index+1+0으로 진행
-
-
Resize :
- Hash Table이 어떤 기준 이상 채워졌을 경우, 더 큰 Hash Table를 만들어서 값을 이동시키기
- Dictionary의 경우 초기 table_size 설정으로는 8개 slot, 그리고 전체 2/3이 채워졌으면 Resize 하게됨
-
《Reference》