Process Concepts
- Decomposition : 복잡한 문제를 단순한 여러 개의 문제로 나누어 처리하는 방법론
Process
-
Process란? :
-
Program in execution, or An execution stream in the context of a particular process state
-
Process state or Context : process가 수행되는데 영향을 줄 수 있는 정보들
 Collection of three types of contexts
Collection of three types of contexts - Memory context
• Code segment, data segment, stack segment, heap
- Hardware context
• CPU registers, I/O registers
- System context
• Process table, open file table, page table
-
Execution stream or Thread of control : process가 지금까지 수행한 모든 명령어들 (또는 함수들) 의 순서
State중에서 유독 stack segment 만은 Thread of control를 구현하는 structure 어떤 Process의 execution 상황은 stack 을 통해서 monitoring 할 수 있다 stack 은 해당 Process의 Run-time Context라고 얘기함
-
-
-
Program == Process ?
- Program : 저장매체에 저장된 受动적인 (스스로 움직이지 않고 다른 것의 작용을 받아 움직이는 것 ) code sequence
- Process : Program in execution, 즉 能动적인 (다른것에 이끌리지 아니하고 스스로 일으키거나 움직이는 것) 존재
Multiprogramming & Multiprocessing
- Multiprogramming
- Memory의 관점
- Main memory에 여러 개의 Active한 Process가 load 되있다
- Multiprocessing
- CPU의 관점
- CPU가 여러 개의 프로세스에 의해서 multiplex 되는 것. 하나 수행하다가 다른 거 수행하다 다시 옛날 거 수행되는 이런 관점이 멀티 프로세싱
- Multiprocessing은 반드시 Multiprogramming 이여야되나?
- 현대 OS에서는 YES, 여러 개의 process가 active하게 도는데, 그 process가 main memory에 있어야 CPU를 빨리 빨리 할당받을 수 있음
- 과거 OS에서는 main memory가 작아서 불가능했음, Uni-programming 하면서 Multiprocessing을 했음
- Swapping : Memory 부족 문제를 해결하기 위해 CPU를 사용하지 않느 Process의 data를 memory에서 다른 저장 장치로 내보내고 CPU를 사용할 Process의 data를 memory로 load하는 것
-
Process가 왜 유용한지?
-
Process는 Design-time entity이며 Run-time entity이다.
-
Run-time entity : OS가 관리하는 단위이고 수행의 주체이고 CPU,Memory, I/O Device를 할당하는 주체이다
-
Design-time entity : 시스템의 Decomposition을 통해서 나오는 결과물들을 바로 구현할 수 있게, 수행할 수 있게 만드는 측면이 있음
 Task : Design-time process (복잡한 Software system을 Decomposition을 통해 설계하게되면 독립적으로 구현할 수 있는 entity가 나오는데 그걸 Task라고 부름)
Task : Design-time process (복잡한 Software system을 Decomposition을 통해 설계하게되면 독립적으로 구현할 수 있는 entity가 나오는데 그걸 Task라고 부름)
-
-
- Program = Data Structure + Algorithm
- Process를 Data Structure로 구조화 시키기
- OS는 각 Process의 정보들 (Process Control Block들) 은 Process Table을 통해 유지하고 관리해야됨
- Process Table 구현 : Process Control Block들의 Array
- 한계 : OS가 제공할 수 있는 Process 개수가 제한됨
 Array 대신 Linked list 형태로 구성하면됨
Array 대신 Linked list 형태로 구성하면됨
- 한계 : OS가 제공할 수 있는 Process 개수가 제한됨
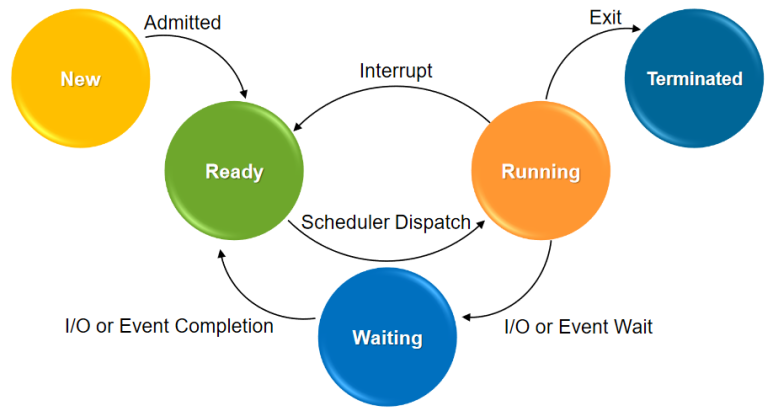
State Transition
-
여기서 State는 어떤 process가 지금 어떤 상황에 있는가를 말함
-
Process Life Cycle : Process가 생성되었을 때 부터 종료될 때 까지 발생하는 일련의 상태 변화
-
Ready State : Active한 Process인데 아직 CPU를 받지 못해서 수행을 못하고 있는 상태 (Process n개)
- Ready Queue :
- Ready 상태의 Process들을 관리하기 위한 Queue형태의 자료구조
- 일반적으로 PCB들을 Linked List로 연결하여 구현
- Ready Queue :
- Running State : OS의 간택을 받아서 CPU를 할당 받은 상태 (Process 최대 1개)
-
Waiting State : 예를들어 Running Process가 동기화 I/O request를 하여서 입력데이터가 들어올 때 가지 기다려야되는 경우임. 이후 원하는 입력데이터가 왔으면 Ready State로 간다 (Process n개)
- 이 n개의 Process를 관리하기 위해 Waiting 이유(I/O Device)에 따라 별도의 Queue를 구현함
- UNIX에는 Zombie state라는게 있음
-
Ready State : Active한 Process인데 아직 CPU를 받지 못해서 수행을 못하고 있는 상태 (Process n개)
-
OS가 Algorithmic하게 해야되는 일 :
- Process가 생성되면 PCB를 하나 할당하고 그 Process를 일련의 조건에 따라서 다른 State로 전이시키는 것
Process Scheduling
-
Process Scheduling을 하는 목적 : 각 Process들이 공평하게 CPU를 공유할 수 있도록 다음에 수행시켜야할 Process를 선택하는 작업
-
OS Scheduler의 제약조건 : Fair scheduling , protection(내 Process가 CPU를 사용하다가 다른 Process한테 양보했을 때 내 프로그램에 문제가 생기면 안됨)
-
OS Scheduler가 해야되는 일 : 어떤 상황이 발생해서 CPU를 다른 Process에게 넘겨줘야될 때, 어느 Process를 골라야 되는가
-
OS Scheduler를 구성하는 Policy와 Mechanism :

-
Policy : 다음에 수행될 Process를 선택하는 기준 (Scheduling Policy) – Fairness와 성능에 많은 영향을 줌
-
Mechanism : CPU를 한 Process에서 다른 Process로 넘겨주는 방법 (Dispatcher)
-
Mechanism은 Scheduling Policy와는 무관하게 기계적으로 돌아가는 것
-
OS의 가장 깊숙한 곳에서 다음과 같은 무한 loop를 돈다 :
while(true){ // 주어진 Process를 어느 정도 돌림 // ("그 Process를 그만 돌려라"라는 명령이 내려오면) // 그 Process를 중단을 시키고 중단시킨 Process state들을 안전한 곳으로 저장 // Policy에 의해 선택된 다음 Process의 state들을 먼저 load한 다음 수행 } -
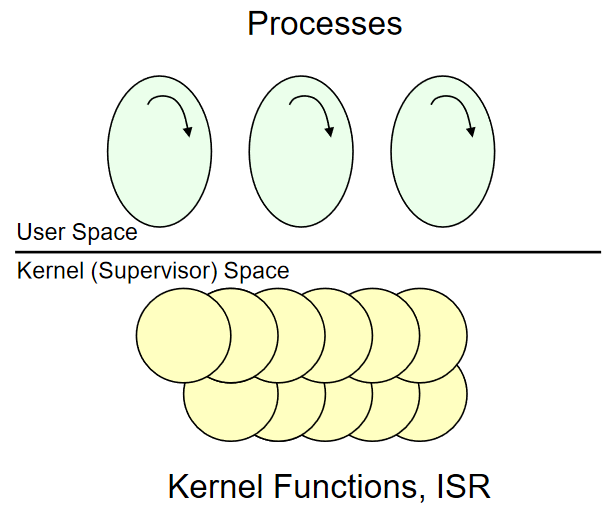
OS은 능동적인 존재처럼 보이지만 사실 수동적인 존재
OS가 능동적이라면, Dispatcher만 도는 CPU와 User processor를 도는 CPU, CPU가 총 2개가 있어야 된다. 근데 OS는 Single processor에서도 잘 돈다 OS는 Kernel Mode에서 수행되는 Library(함수들의 Collection) 이다
 각 함수들을 “System call 함수“라고 함
각 함수들을 “System call 함수“라고 함
Kernel Function : System call를 구현한 함수들 + Interrupt Service Routine(ISR)
Dispatcher 도 Kernel Function중 하나임
-
어떻게 하면 Single processor로 Dispatcher와 User processor를 모두 돌릴 수 있을 까?
 User processor가 운해되다 중단 (User Mode) Dispatcher code 운행 (Kernel Mode) 다른 User processor가 운행 (User Mode) … 즉, User Mode에서 Kernel Mode로 전환하기 위한 하드웨어적인 Interrupt가 필요하다 Dispatcher는 User program과 User program가 수행되는 중간에 개입해서 CPU를 process A에서 process B로 넘겨주는 역할을 한다
User processor가 운해되다 중단 (User Mode) Dispatcher code 운행 (Kernel Mode) 다른 User processor가 운행 (User Mode) … 즉, User Mode에서 Kernel Mode로 전환하기 위한 하드웨어적인 Interrupt가 필요하다 Dispatcher는 User program과 User program가 수행되는 중간에 개입해서 CPU를 process A에서 process B로 넘겨주는 역할을 한다 -
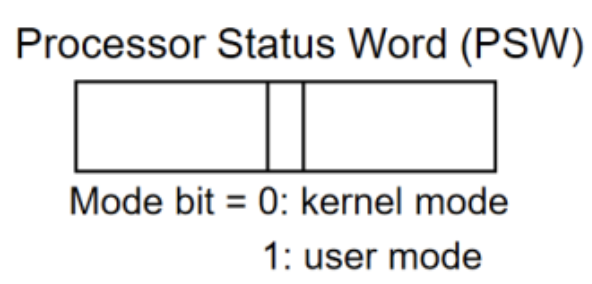
Processor가 Kernel mode와 User mode를 구분하는 방식 :
PSW(Process Status Word) Register안의 특정 bit를 Mode bit로 사용
-
Dispatcher를 호출하는 방법
-
Non-preemptive Scheduling
- Process가 자발적으로 CPU를 양보하여 다른 Process를 수행하는 Scheduling
(Ex. 지금 CPU에서 돌고 있는 Process가 I/O 요청을 했는데 아직 I/O가 준비되지 않을 경우)
- 구현 방법 : Software Interrupt (Trap)을 사용하면 이 Scheduling 을 호출 할 수 있음
-
- OS가 강제로 Process로 부터 CPU를 빼앗아 다른 Process를 수행하는 Scheduling
(Ex. CPU가 Time sharing을 할 경우)
- 구현 방법 : Timer Hardware의 interrupt에 의해서 이 Scheduling 이 촉발이 됨
-
-
Mode change of process
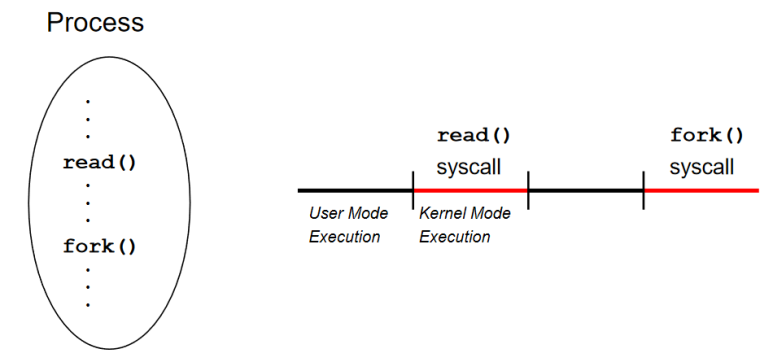 Kernel Mode Execution이 일어날 때 수행의 주체가 되는 Process는? :
Kernel Mode Execution이 일어날 때 수행의 주체가 되는 Process는? :System Call을 호출한 사용자 process (즉, 현재 수행중인 Process ID는 똑같은 놈이다)
Process가 User Mode에서 수행 될 때는 User mode stack을 사용하고, Kernel mode에서 수행될 때는 Kernel mode stack을 사용한다. System call과 일반 function call의 차이 :한 루틴에서 다른 루틴으로 넘어간다는 점은 같지만 function call은 Mode change가 발생하지
 , System call은 User mode에서 Kernel mode로 Mode change가 발생한다
, System call은 User mode에서 Kernel mode로 Mode change가 발생한다
-
-
Context Switching
-
Context Switching : Dispatcher가 해야되는 역할. 즉, 현재 수행중인 Process의 state를 저장하고 다음 수행될 process의 state를 불러오는 작업
-
Context saving : 지금 중단된 process의 state들을 안전한 곳으로 대피시키는 동작
-
Memory, Hardware, System context이 3가지 state중에 어떤 걸 선택해서 대피시켜야지?
Option 1 : 전혀 대피 시키않는다
과거에 Multiprogrammed batch monitor 시절Option 2 : Roll-in/Roll-out swapping (몽땅 다 Disk에 대피시킨다)
Uni-programming을 할 때 필요 : Main memory에 하나의 process만 올려놓고 수행시키다가 게가 CPU를 빼앗기게되면 이 processs는 Disk로 나가고 Disk에 있던 새로운 process가 Main memory로 들어옴 (이때는 메모리값이 비싸서 여러 프로그램을 올릴 수 가 없었음)
단점 : 굉장히 느림Option 3 : Swapping (현재 사용되는 일부만 Disk로 대피시킨다)
메모리 안에 너무 많은 active한 프로세스가 들어 있어 있을 때 어쩔 수 없이 메모리 공간을 비우기 위해 선택된 일부만 Disk로 보냄. (Swap out)
대부분 모든 OS에서는 Swap out 기법을 사용하고 있음 결국 : Hardware context는 반드시 대피, Memory context는 필요한 경우 부분적으로 대피, System context는 그냥 내비두면 된다
결국 : Hardware context는 반드시 대피, Memory context는 필요한 경우 부분적으로 대피, System context는 그냥 내비두면 된다 (Hardware context 중 하나인) CPU Register는 Disk로 대피 시키는 것인가?
(Hardware context 중 하나인) CPU Register는 Disk로 대피 시키는 것인가?
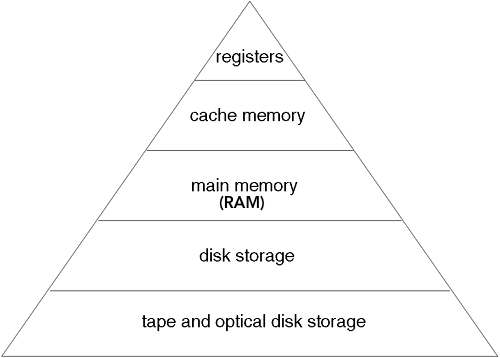
💁🏻 일반적으로 memory hierarchy의 한 단계 아래의 저장 장치로 데이터를 대피시키기 때문에 CPU Register는 Main memory로 대피시킨다 (Cache는 속성이 다른 메모리니깐 거기다 대피시키면 안됨). 이 부분은 다음 Context Switching의 Mechanism을 통해 확인 할 수 있다
-
-
Context Switching의 배경
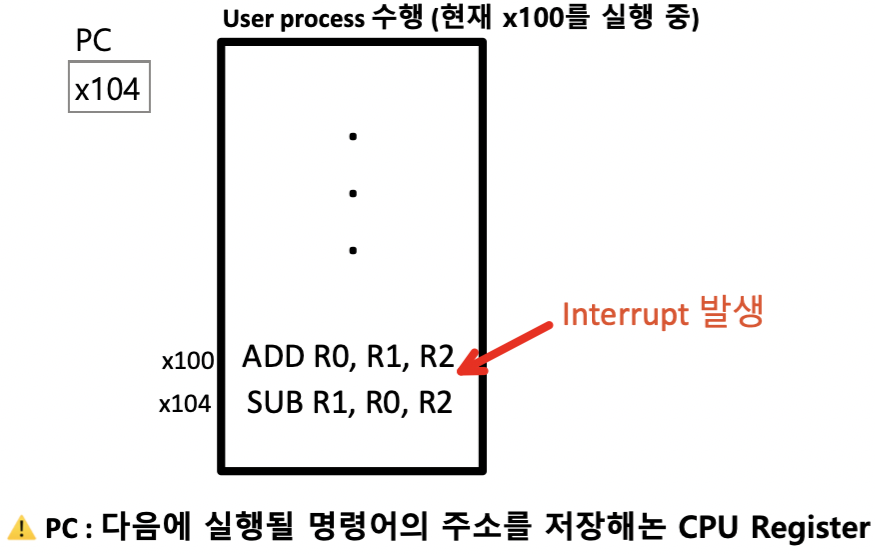
[1] User process 명령을 실행하는 중에 Interrupt 발생
- Microprocessor는 지금 수행중인 명령을 우선 끝을 낸다
- Interrupt Checking을 한다
[2] Interrupt 수행
- Microprocessor는 Interrupt의 IRQ Number를 확인
- IRQ Number에 따라 Interrupt Vector table을 뒤져서 해당 Interrupt service routine의 시작 주소 확인
- Interrupt service routine의 시작 주소로 Jump
- Interrupt service routine 수행
[3] 다시 User process로 복귀
-
Context Switching의 Mechanism
- Terms :
- OSPCBCur : 현재 수행되고 있는 Process의 PCB를 가르키는 Global variable
- PCB에 있는 내용들 : Process ID, Stack pointer field (StkPtr), 등등 …
- CPU Stack pointer register : 현재 stack의 최상단 주소를 저장하고 있음
-
Mechanism :
-
Interrupt가 걸리면 Hardware적으로 stack에 PSW값과 PC값이 저장됨
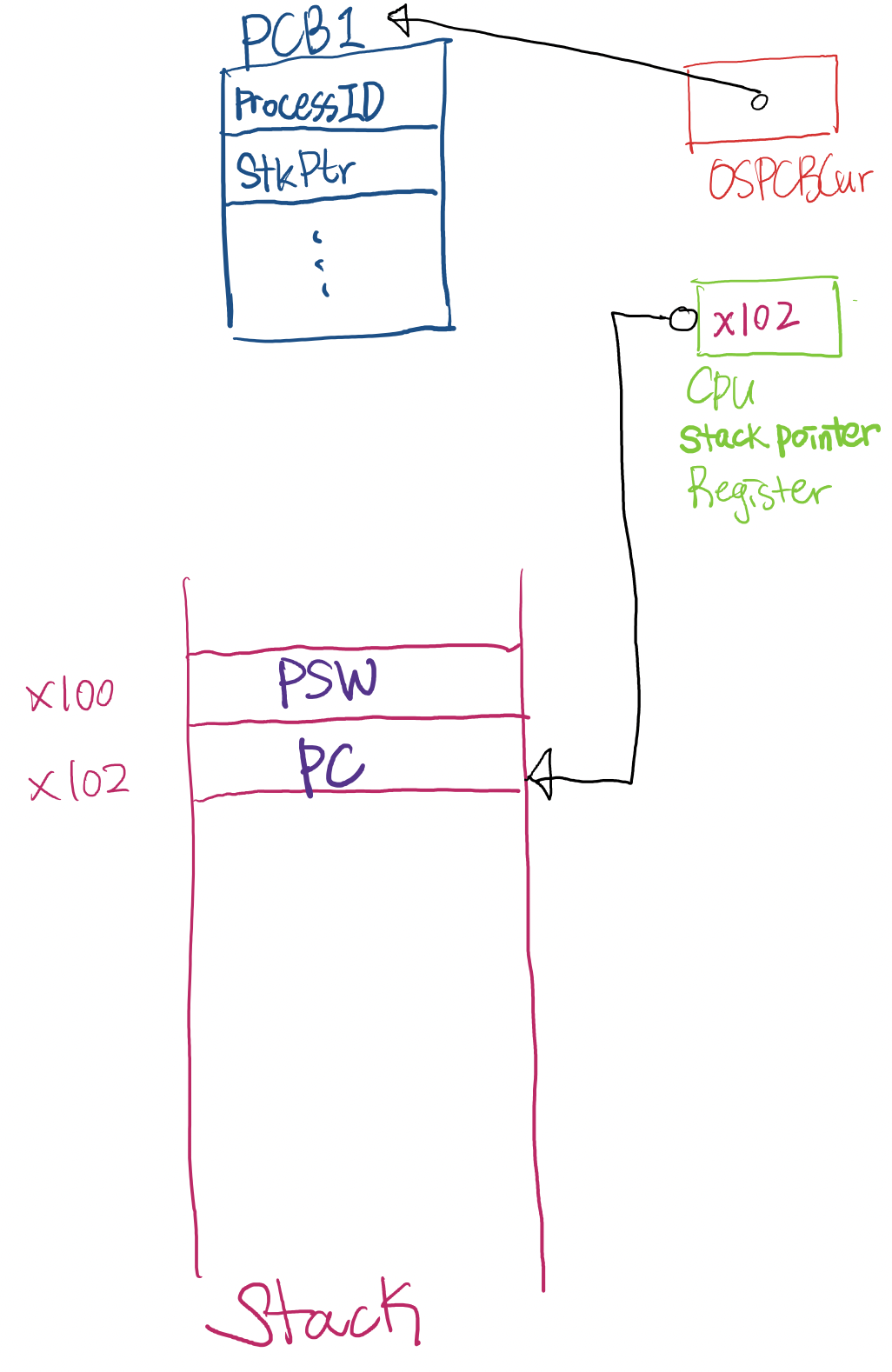
-
Interrupt service routine으로 Jump
-
PUSHALL 명령실행 : CPU Register 값들을 전부 stack에 대피
( [2].4 Interrupt service routine 수행될 때 가장 먼저 해야되는 것 )
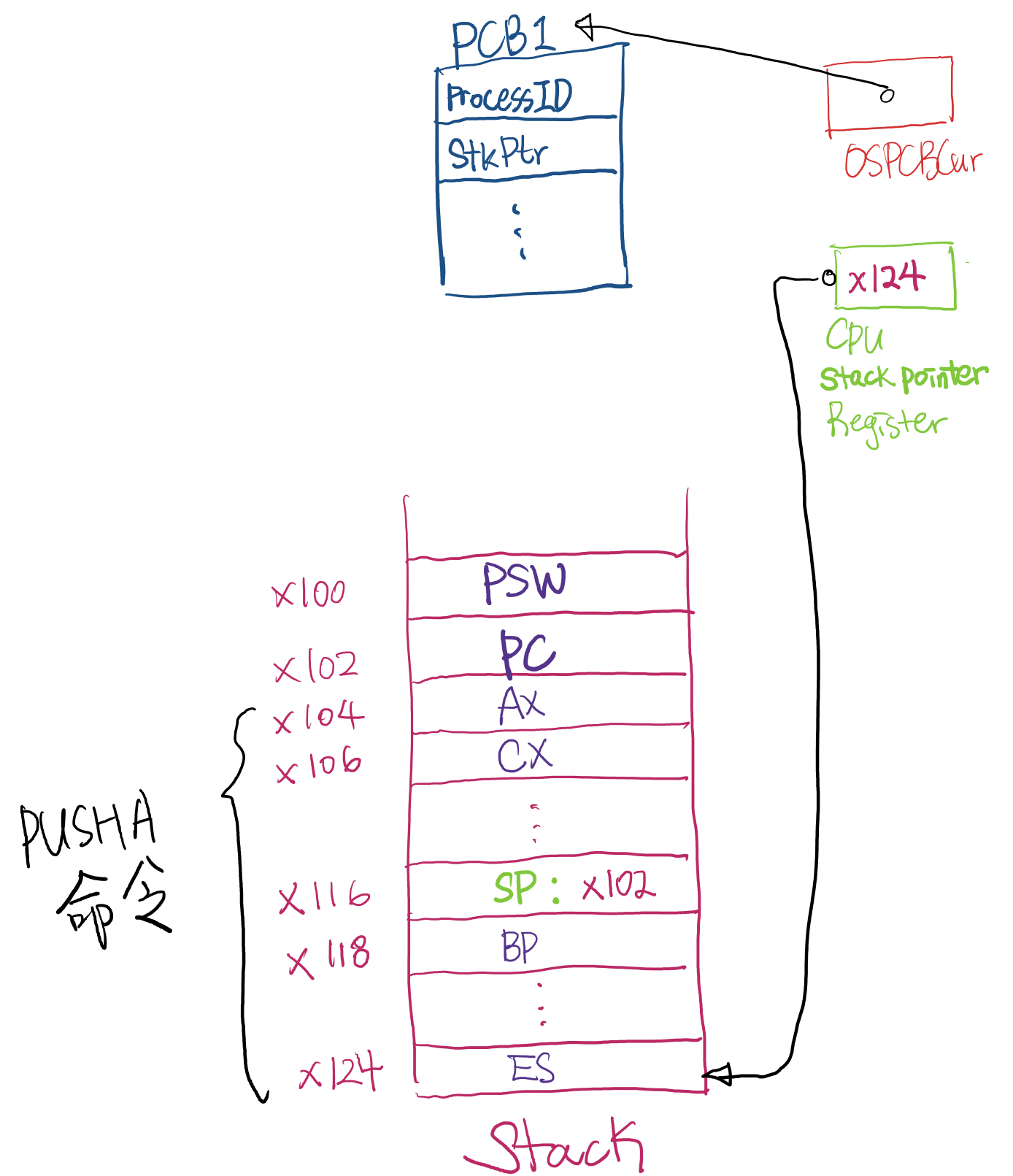
-
지금 중단된 process의 Context saving 완료
-
CPU의 Stack pointer register 값을 PCB의 Stack pointer field (StkPtr)에다 저장
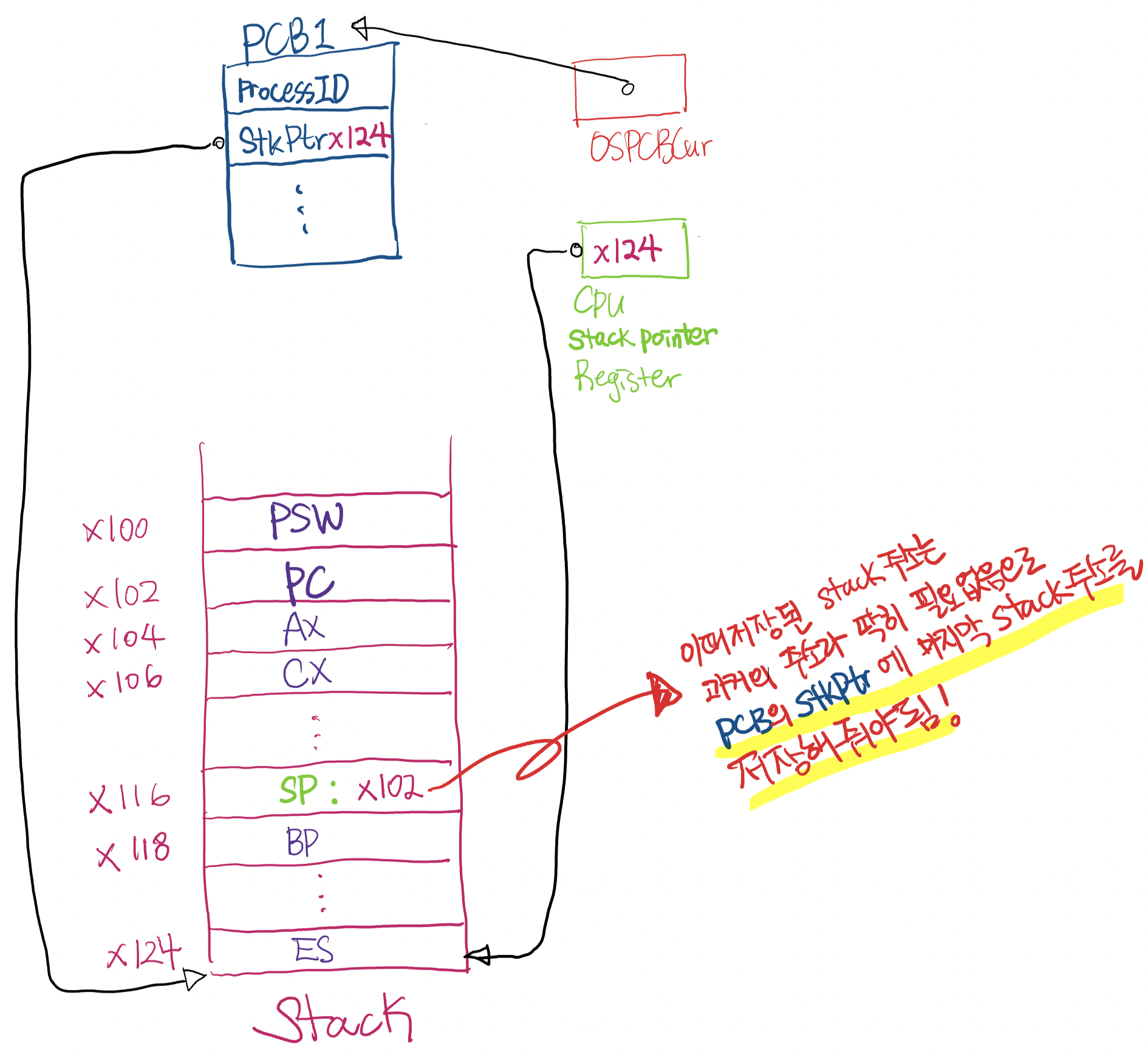
-
다음에 실행되야되는 process의 PCB pointer를 OSPCBCur 변수에 기록
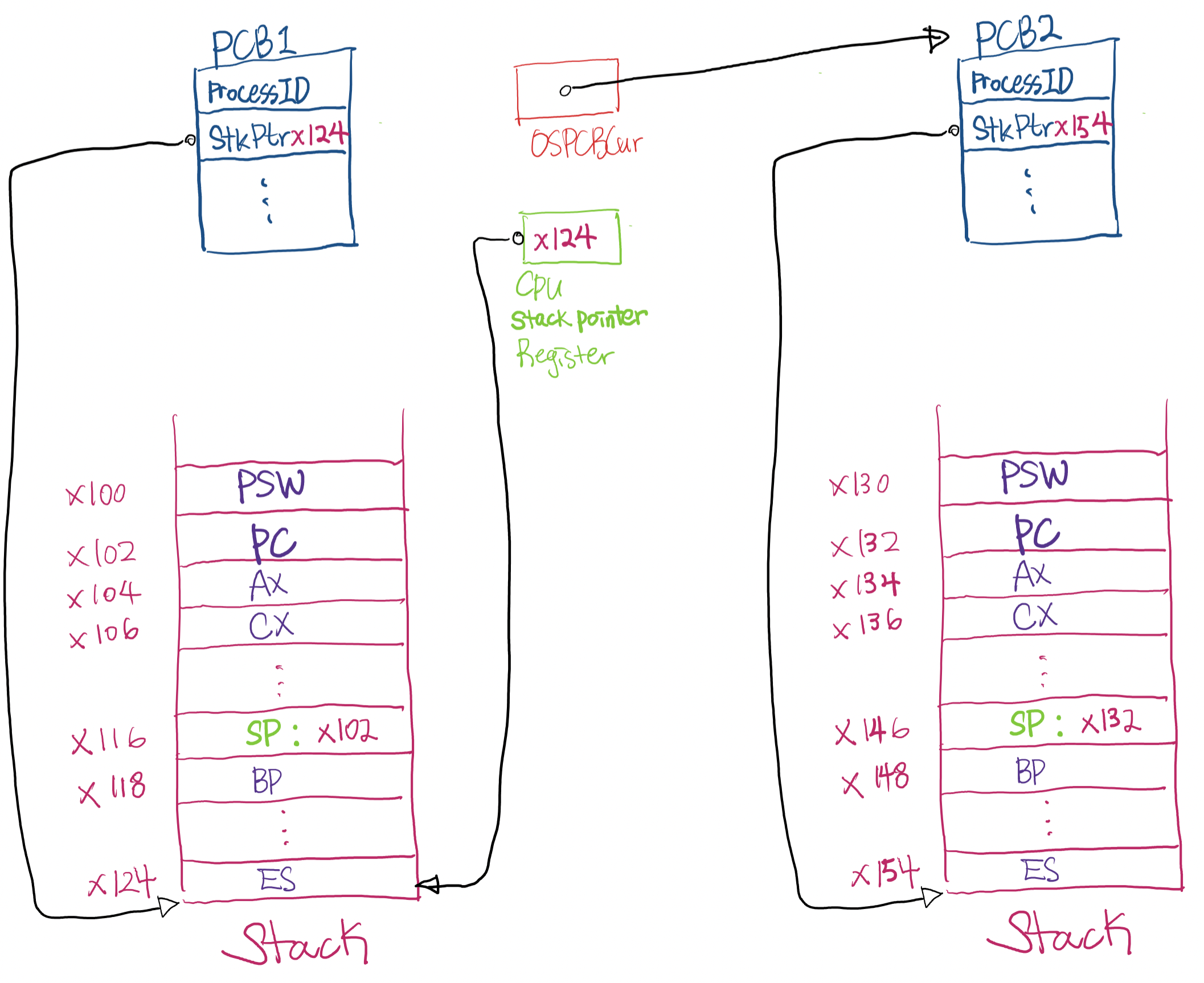
-
새로운 PCB의 Stack pointer field (StkPtr)를 CPU의 Stack pointer register에다 저장
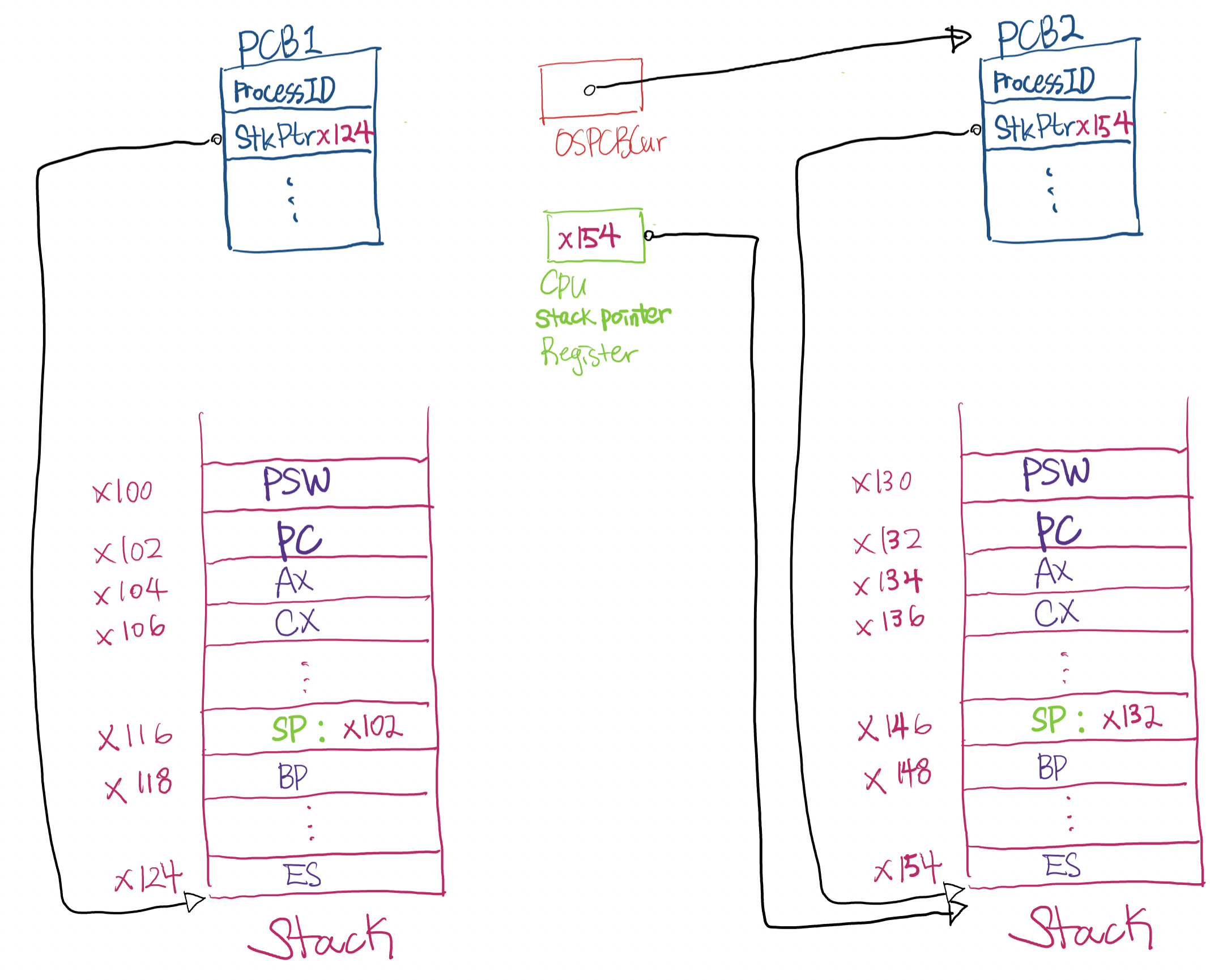
-
POPALL 명령실행 : 새로 수행될 Process의 context들이 CPU register로 들어오게 됨
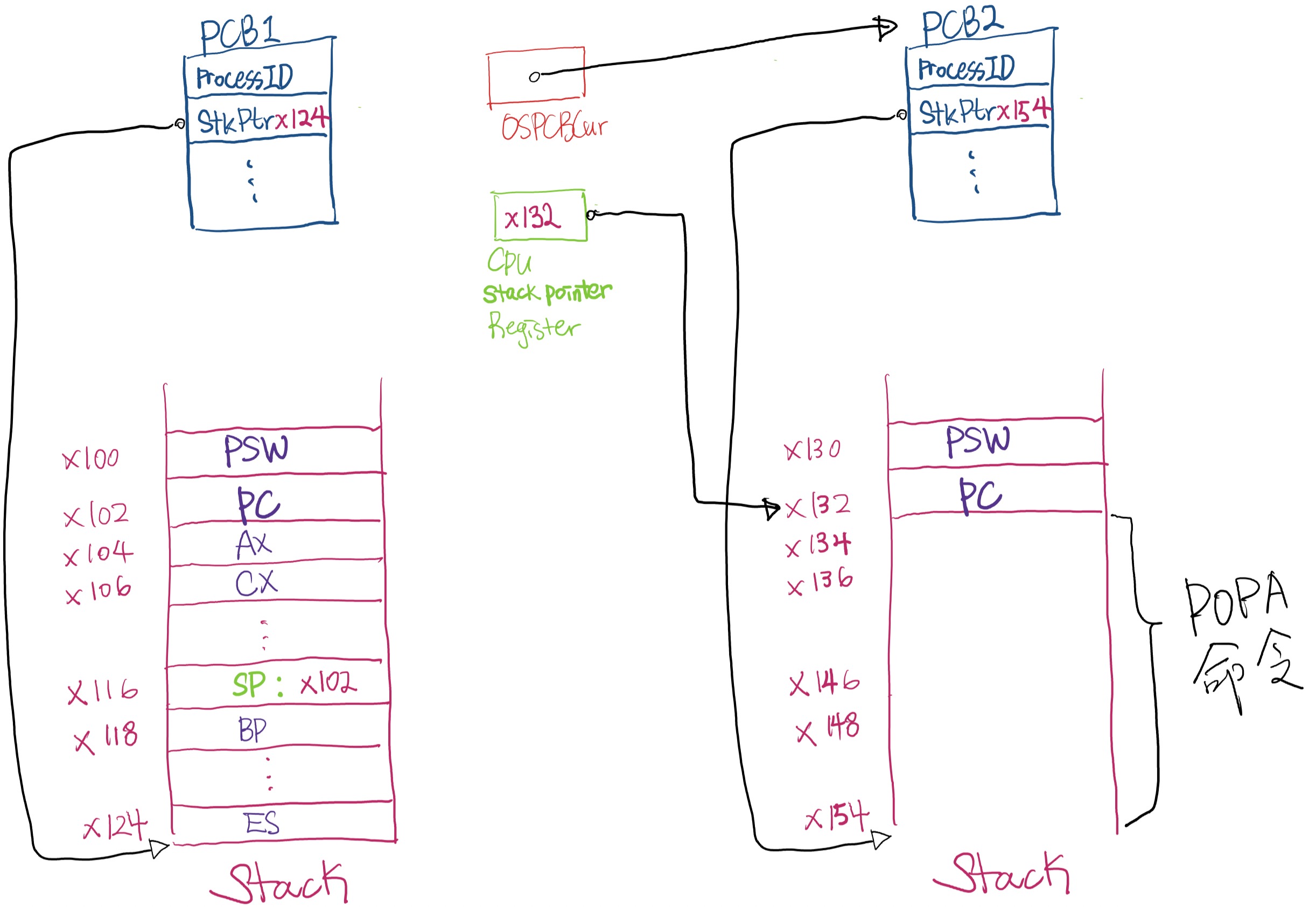
-
PC와 PSW를 POP함 : 새로 수행될 Process의 PC 주소로 jump, PSW의 Mode bit에 따라 mode change
-
❓ PSW는 stack에 왜 들어가야되나?
💁🏻 interrupt가 끝나고 다시 User process로 복귀하면 이 process를 실행 시키위한 mode로 다시 회복 시킬 필요가 있으니깐
❓Hardware가 직접 PSW 그리고 PC 값을 stack에 넣어주고 PUSHALL 명령의 동작까지 해주면 안됨?
💁🏻 프로그래밍 상황에 따라 일부 Register는 대피하지 않아도 되는 상황이 발생할 수 있기 때문에 PUSHALL 명령은 Software적으로 구현한다
- Terms :
-
이 Mechanism는 잘 동작하는데 딱 하나 예외가 있다 :
-
Process는 적어도 한번은 Context switching을 당해야됨. 그래야만 자기의 Stack이 구성이 될 수 있음
-
예외의 경우는 처음 Process가 만들어 졌을 때 이다.
-
이때는 OS이 어떤 Process를 생성하게 되면 그 process의 stack을 마치 Context switching을 한번이라도 당한것 처럼 Fake stack을 만들어 준다
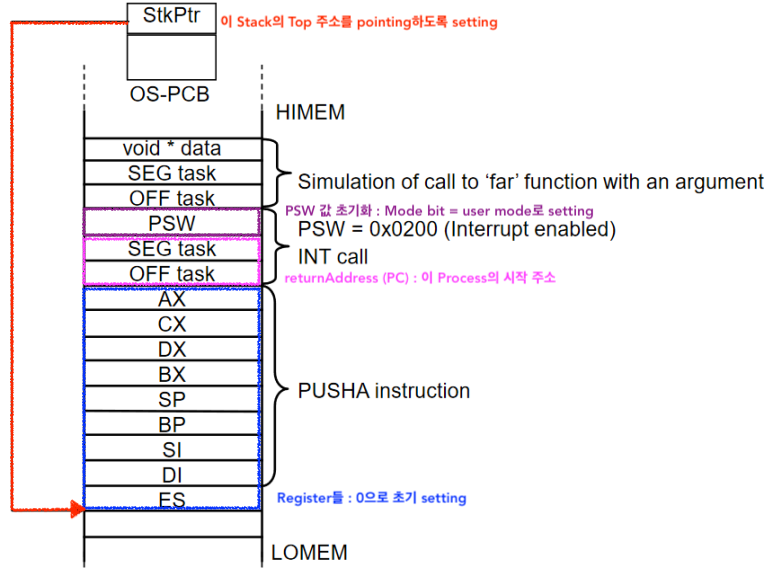
-
-
![]() Main memory에는 각 Process 별로 Stack을 가지고 있고 단지 Active한 Stack은 현재 1개가 있다는 사실 잊지말기
Main memory에는 각 Process 별로 Stack을 가지고 있고 단지 Active한 Stack은 현재 1개가 있다는 사실 잊지말기
- 요약 :
- OS Scheduler는 Policy 부분과 공통적인 Mechanism부분이 있다.
- 여기서 Mechanism부분이 Context Switching을 담당하는 Dispatcher다
- Dispatcher가 수행될려면, User process와 User process사이에 mode change 가 일어나서 수행이 되야된다
Process Creation and Termination
Process Creation
- UNIX계열 OS는 Booting할 때 딱 한번 0번 Process를 생성할 때, 다음과 같은 과정으로 생성을 한다
-
0번 Process Creation 과정 :
[1] Program Loading
- File system에 executable file이 있음
- executable file의 path name이 OS에 전달
- OS는 executable file의 code들을 Memory context의 한 부분인 code segment에 읽어드림
- executable file의 Global 변수들에 대한 선언과 정보들을 data segment에 영역을 다 잡아줌
[2] Stack segment, heap 를 생성
[3] Pocess의 PCB를 생성
[4] PCB을 Ready Queue에다 넣기
-
- 0번 Process외의 나머지 Process들은 복제라는 기법을 사용해서 생성한다
-
Parent Process : Process Cloning을 초래하는 기존의 Process
-
Child Process : Parent Process로부터 만들어지는 새로운 Process
-
나머지 Process들의 Creation 과정 :
-
Parent Process가 Child Process를 만들기 위해선
fork()라는 System Call을 호출함 -
fork()를 호출이 되면, OS가 Parent Process의 수행을 중단 시킴, Parent Process의 Context를 그대로 copy 해서 Child Process를 생성 ( 단, PCB의 ProcessID는 다른값을 가짐 ) -
Child Process의 PCB를 Ready Queue로 보냄
-
fork()System Call 수행 끝 -
Parent Process로 return
-
-
fork()System Call (Cloning 방식으로 Child Process 생성)의 문제점 : -
맨 처음 만든 Process 0 프로그램 외 에는 다른 프로그램을 수행할 수 없다
-
그래서
fork()한 다음에exec(..)System Call을 호출시킴-
exec(...): 생성된 프로그램의 executable file path name을 parameter로 받아서 executable file의 code와 data를 읽어와서 Parent의 내용을 override 한다
-
-
-
Process life cycle in UNIX :
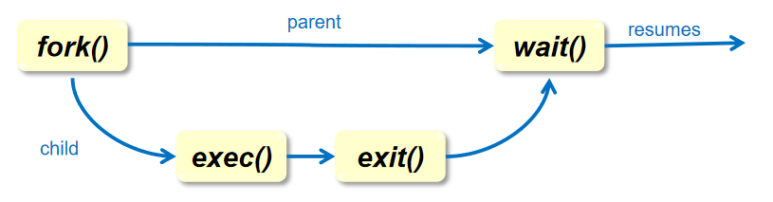
-
fork()수행 后 : Child Process는 Parent Process의 context를 copy -
exec(...)수행 后 : Child Process과 Parent Process가 다른 program을 수행하는 Process가 됨 -
exit(): - Process를 종료시키는 System Call
- OS가 알아서
exit()Call을 해줌 - 그 Process가 가지고 있던 Data structure, Resource를 OS가 걷어감
-
exit()Call 수행이 잘됬나 잘안됬나를 표현하는 결과 code를 하나 남김 - 그 code 값을
wait(...)하고 있는 process에게 전달하게 됨 - Parent Process는 그때서야 깨어나서 자기 나머지 수행을 함
- Zombie state :
exit()를 마치고 Parent Process가 자신의 Exit status를 읽어가기를 기다리는 Process의 상태 -
wait(...):- 자기가 생성한 Child process의 id를 parameter로 넘겨줌
- parameter로 받은 process가 수행을 종료할 때 까지 기다리게 하라는 System Call
-
-
Shell code Example :
- Shell : 사용자가 입력한 명령어를 입력으로 받아들여 새로운 Process를 수행시키는 Program
- System call들의 return 값들 :
- 음수 : System Error
- 0이상의 양수 : 제대로 동작
for(;;) { cmd = readcmd(); // 사용자의 명령어를 받음 pid = fork(); // 사용자의 명령을 수행시킬 Child Process를 만듬 if (pid < 0) { // 만약 System Error일 경우, 종료 perror("fork failed"); exit(-1); } else if (pid == 0) { // Child Process가 수행되는 부분 // Child – Setup environment if(exec(cmd) < 0) perror("exec failed"); exit(-1); // Exit on exec failure } else { // 만약 Child Process의 id가 0보다 클 경우, // Child Process의 실행이 끝날 때 까지 Parent process는 Wait한다 // Parent – Wait for command to finish wait(pid); } }-
pid = fork();:- 이때 Child process가 Parent process로부터 복제됬기 때문에 Child process의 명령 실행 시작 주소는 Parent process와 똑같은
pid = fork();의 바로 다음 명령의 주소가 된다 - 하지만 이때 System call return value를 Child process한테는 0으로 Parent process한테는 Child process의 pid를 넣음 ( 注意 : Child process의 id를 0으로 주는게 아니라
fork()System call의 return값이 0이다 )
- 이때 Child process가 Parent process로부터 복제됬기 때문에 Child process의 명령 실행 시작 주소는 Parent process와 똑같은
-
fork()를 통해 Process 생성하는 방식의 성능 문제 해결 방안 : - 성능 문제 :
- Parent의 Code와 Data를 복사했는데 바로
exec(...)으로 override되는 문제 - 즉, 불필요한 copy를 통한 성능 저하
- Parent의 Code와 Data를 복사했는데 바로
- 해결 방안 : Copy on Write(COW)
-
fork()시점에 Process Context를 복사하지 않고 pointer Data structure를 만들어서 parent의 code와 data segment를 child가 point하게 만듬(대신 stack segment는 별도로 가지고 있고), 그리고 Data Segment에 새로운 값이 쓰여질 때 복사하는 기법
-
Process Termination
- Process Terminate 방법들
-
exit();: Process executes last statement and asks the OS to decide it -
abort();: Parent may terminate execution of children processes
-
Multithreading
Multithreading의 목적
- Concurrency는 높이면서
- Execution Unit을 생성하거나 수행시키는데 드는 부담을 줄임
-
Process가 생성될려면 Context가 생성되야되고, 그 외에 Logical address를 Physical address로 Mapping시키위한 mapping table들 그리고 많은 부수적인 정보들이 필요하게 됨. 그래서 수만개의 process가 한 System에 공존하게 되면 System을 운용하기 어려울 정도에 성능저하가 일어나게 됨
-
Multithreading하게 되면 Single threading의 Process와 달라진 점 :
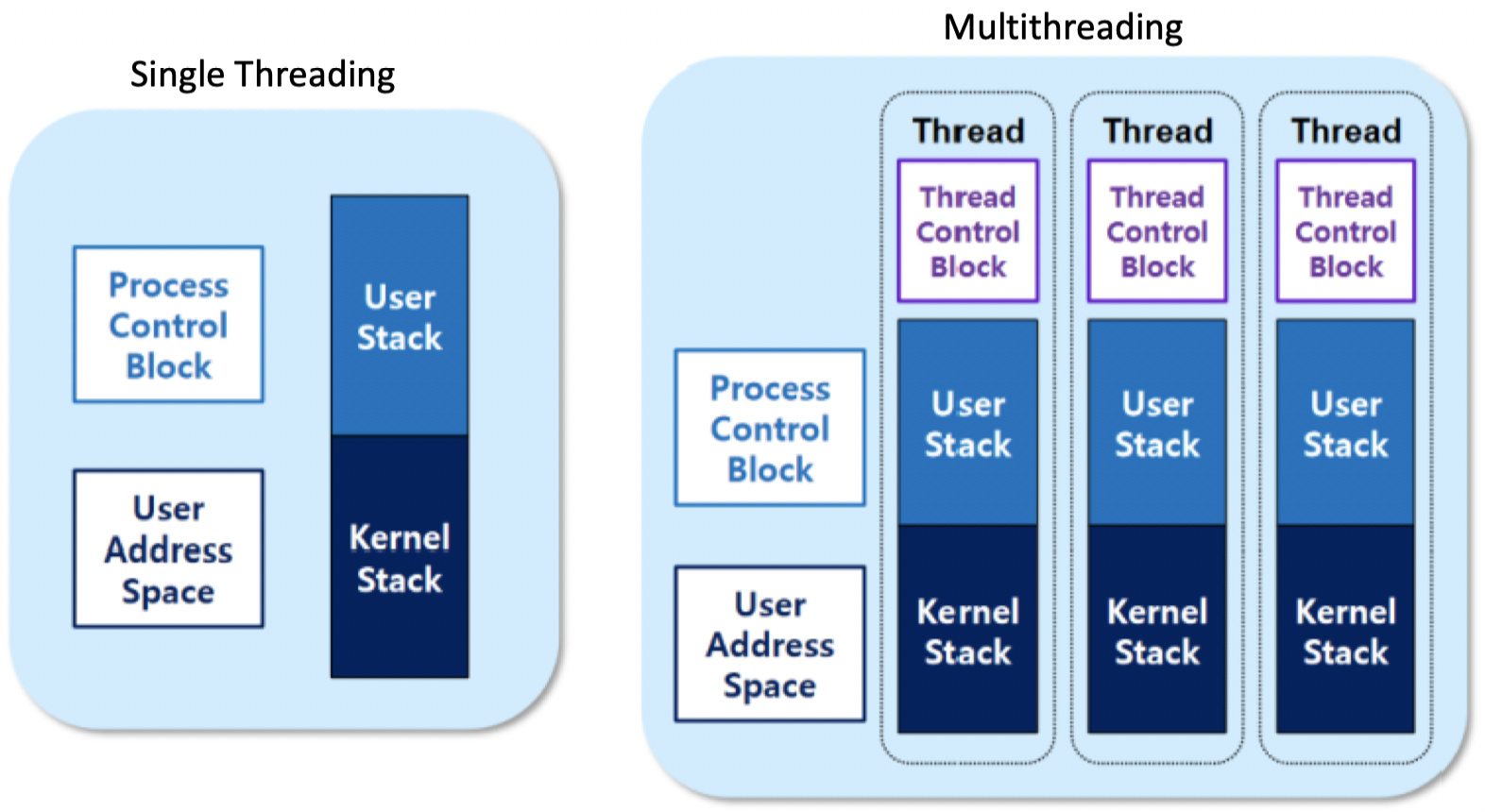
- Thread = Execution stream 또는 Stack
- 그림에서 User stack은 user mode에서 사용되는 stack 그리고 Kernel stack은 kernel mode에서 사용되는 stack을 나타내고 있다
- Single Threading : a.k.a Conventional UNIX Process
- 하나의 Process가 여러 개의 Thread(여러 개의 Execution stream 또는 Stack)를 갇게됨
- 여러 개의 Thread들은 그 Process에 부여된 Address space와 resource들을 공유한다
- Thread = Execution stream 또는 Stack
-
Thread의 구현을 위해 필요한 자료구조
- Stack
- Thread ID : 각 Thread들의 naming
- Thread Control Block (TCB) : 각 Thread ID에 소속된 정보를 담음
-
여러 가지 OS에서 Multithreading의 지원
- MS-DOS : Single Tasking Kernel - 하나의 Process 지원, 그 안에 하나의 Thread of Control만 지원
- 과거 UNIX : Multi Taking Kernel - 여러개의 Process 지원, 각각 Process들 안에 하나의 Thread of Control 밖에 가질 수 밖에 없었음
- 최근 OS : 여러 개의 Process 지원, 그안에 여러개 Thread들을 지원
왜 Multithreading을 해야되나?
- Concurrency를 쉽게 늘리고 response time을 좋게 만들어 주기 때문에
- Multithreading을 사용하게 되면 왜 병렬프로그래밍할 때 overhead가 적은 이유 : process는 1개만 나두고 Thread만 여러개 생성하면 되기 때문에. 이렇게 되면 메모리 요구량도 줄어들고 성능도 개선이 됨
- Thread들이 process에 할당된 Resource를 공유 가능하다
- 물론 공유된 Resource를 가지게되면 Synchronization 문제가 발생함
- 구현이 쉽고 경제적이다
- 새로운 Thread를 생성할 때도 시간도 적게 걸리고 메모리도 조금 차지함
- Process context switching 보다 Thread context switching이 더 경제적인 동작임
Multithreading 구현 방법
-
User-Level 구현 : Kernel이 전혀 모르게 구현하는 방법
-
기본적인 Idea : OS는 Conventional UNIX Process 만 지원함. 그 안에 Multithreading을 구현. 대신 Kernel은 고치진 않고 User-level에서.
-
구현 방안 :
-
Thread를 여러 개 넣을려면 여러 개 Stack 을 구현
- 각 Thread의 Thread Control Block를 만들어서 User-level에 있어야됨
- Thread 간의 switching을 위해 User-level에 Schduler가 있어야됨 💁🏻 함수로 구현하고 그 함수들을 묶어서 Library로 만들면됨
-
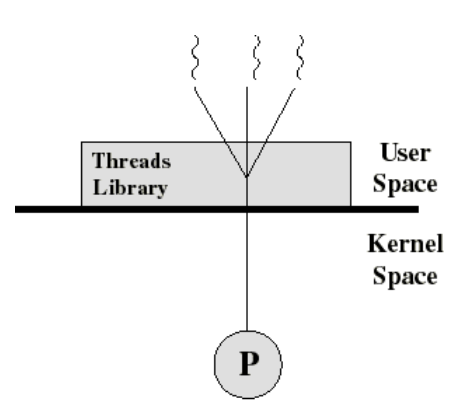
-
Thread :
- 100% User-level Entity
- Kernel은 Thread들이 존재하는지 모름
-
Thread Library :
- Thread를 생성하고 소멸시키는 code 포함함
- Thread context를 저장하는 code 포함함
- Thread들 간에 Communicatoin을 제공해주는 함수들을 포함함
-
단점 :
-
OS가 Thread에게 직접 Interrupt를 전달 할 수 없기 때문에 Preemptive Scheduling에는 한계가 있음
Example. User-level Thread가
read()System call이 필요했다. 그럼 DMA가 Disk I/O가 끝나고 Interrupt를 다시 CPU한테 걸때 그 Interrupt가 Thread에게 전달 될 수 있는 방법이 없음 -
한 Thread가 System call을 호출하는 경우 해당 Process의 모든 Thread가 Block 됨
Example. 어떤 Thread가 수행하다가
read()System call을 호출함. 그래서 Kernel이 Disk I/O를 시작하게 되면 Disk I/O 동작이 끝날 때 까지 Thread가 속한 Process를 Blocking 시킴. 실제로 그 Process안에는read()를 호출한 Thread 뿐만 아니라 다른 Thread들이 잔뜩 있을 수 있음. 즉, 원래 다른 Thread들이 수행을 할 수 있음에도 불구하고 수행을 진전시키지 못하는 문제가 생김
-
-
장점 :
- 구현이 쉬움
- OS code를 고치지 않고도 Multithreading를 할 수 있음
- 병렬 연산에 각 Thread가 mapping되어 잘 동작됨
-
User-Level 구현이 유용한 곳
- 병렬 연산 system
-
-
Kernel-Level 구현 : Kernel이 100% 알고 지원하는 방법
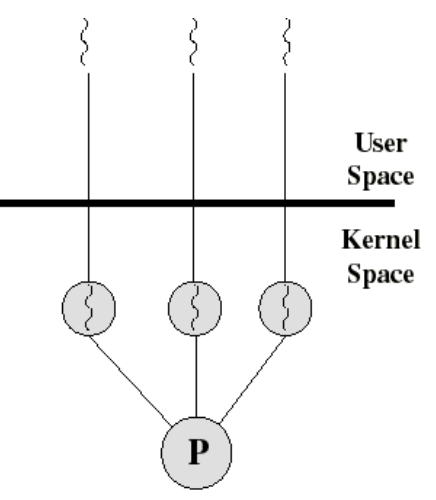
- 기본적인 Idea :
- Thread creation, termination이 모두 Kernel 함수 System call로 구현됨.
- Thread Control Block도 역시 Kernel이 조작함.
- Kernel이 직접 Thread들을 다 Schduling하는 Schduling entity들이 된다
- Window도 Kernel-Level thread를 지원함
- 장점 :
- User-Level 구현의 단점들을 다 해결 할 수 있다
- 단점 :
- Kernel 단의 수행시간이 증가하면서 추가적인 overhead가 발생함
- Kernel-Level 구현이 유용한 곳
- Reactive control system
- 기본적인 Idea :
-
Combined User-Level / Kernel-Level 구현
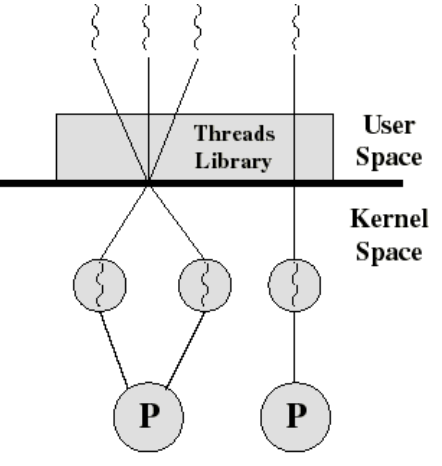
- 상당히 많은 부분을 User-Level Thread가 처리함
- Thread가 Preemptive Scheduling을 가능하게 하는 기법을 User-Level에 추가한 것이 Combined User-Level / Kernel-Level Thread 구현
- 추가된 기법
- Interrupt가 왔을 때, 그 Interrupt를 User-Level Thread Schduler에게 forward해서 어떤 Thread 깨어나야되는 알려주는 기법
- Sun Microsystems Solaris :
- User-level Thread와 Kernel-level Thread 연결시켜서 관리함
응용프로그래머로써 Thread programming model을 어떻게 사용할 것 인가?
- 응용프로그래머로써 Thread programming model을 어떻게 사용할 것 인가?
- Multi-threading이 제공해주는 API를 알아야됨
-
Portable Operating System Interface (POSIX) :
- 다양한 UNIX 계열 OS들의 API 표준화 하기 위해 IEEE가 정의한 interface
Pthreads API Description pthread_create(...)- 새로운 thread 생성
- 함수의 function pointer가 argument로 들어감pthread_exit()- 호출하는 thread를 terminate시킴 pthread_join(...)- argument로 들어온 thread가 terminate할 때 까지 기다림 pthread_yield()- Non-preemptive Scheduling 때 CPU를 넘겨줄때 사용 -
Thread life cycle
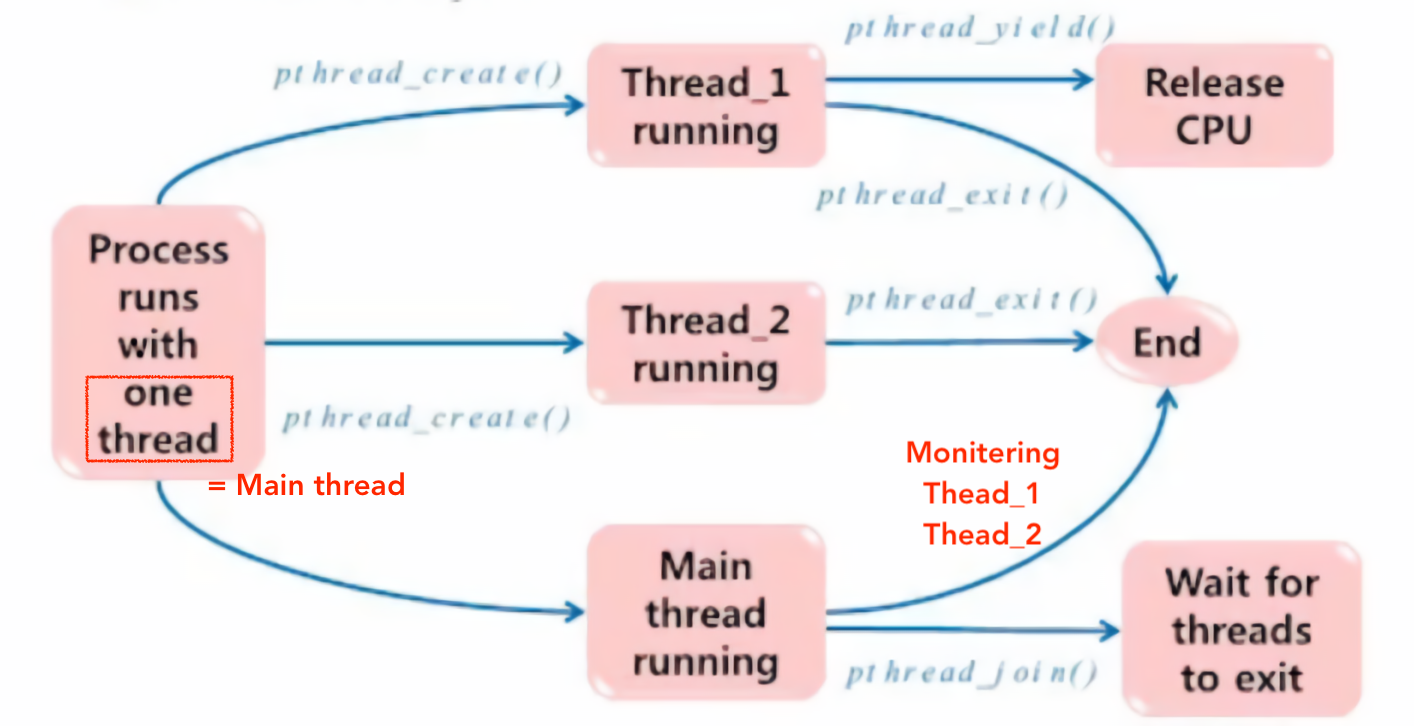
- Main thread : Process에는 default로 한개의 thread를 가지고 있음
❓
pthread_yield()를 호출한 Thread는 어떤 식으로 수행이 재개되는지? 💁🏻
pthread_yield()에 의한 Thread의 상태 변화는 OS에 의해 관리된다. User code 상에서는pthread_yield()의 호출 지점에서 정지되는 것으로 보이며, Thread가 다시 CPU를 할당 받으면 다음 Statement 부터 수행을 재개한다 -
Example Code
#include <stdio.h> #include <stdlib.h> #include <assert.h> #include <pthread.h> #include <unistd.h> #define NUM_THREADS 5 // main에서 pthread_create()의 argument로 들어갈 function pointer void *perform_work(void *arguments){ int threadID = *((int *)arguments); printf("Hello World! I'm thead number %d\n", threadID); return null; } int main(void) { pthread_t threads[NUM_THREADS]; int thread_args[NUM_THREADS]; int i, result; //pthread_create()를 통해 하나씩 thread를 생성하는 부분 for (i = 0; i < NUM_THREADS; i++) { printf("IN MAIN: Creating thread %d.\n", i); thread_args[i] = i; result = pthread_create(&threads[i], NULL, perform_work,(void*) &thread_args[i]); assert(0 == result); } printf("IN MAIN: All threads are created.\n"); //pthread_join()을 통해 각 thread들이 완성될때 까지 기다리는 부분 for (i = 0; i < NUM_THREADS; i++) { result = pthread_join(threads[i], NULL); assert(0 == result); printf("IN MAIN: Thread %d has ended.\n", i); } printf("MAIN program has ended.\n"); return 0; }
《Reference》