GAN을 통해 생성된 Image들의 여러 문제점들
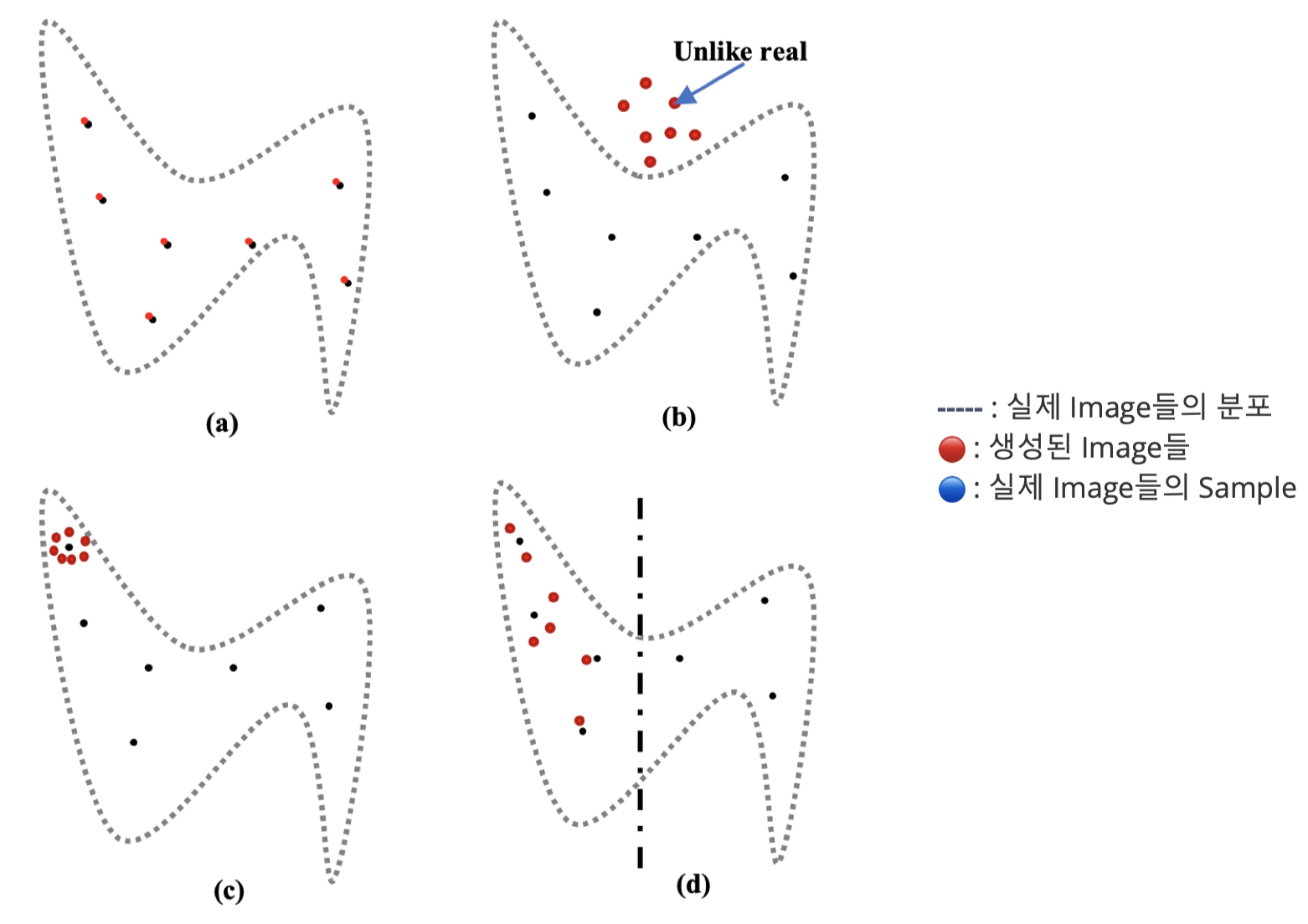
(a) Overfitting 현상
(b) 상속 부족 현상
(c) Mode Collapse 현상
-
Generator가 다양한 이미지를 만들어내지 못하고 비슷한 이미지만 계속해서 생성하는 경우

-
원인 : Discriminator하고 Generator가 학습이 서로 상호작용을 하면서 같이 학습이 진행 되어야 하는데 한쪽이 너무 학습이 잘 되어버려서(학습의 불균형) mode collapse가 발생
(d) Mode Dropping 현상
사람 육안으로 GAN 성능평가의 문제점
- 평가하는 사람에 따라 지표가 나누어지기 때문에 주관적임
- 평가하는 사람의 도메인 지식의 영향이 크기 때문에 적용할 수 있는 분야가 한정적임
- Mode-collapse과 같은 현상을 잡아낼 수 없음
GAN 평가 방법들
1. CID index [Guan et al., 2019]
CID index 공식
- 3가지 평가지표를 곱한 지표
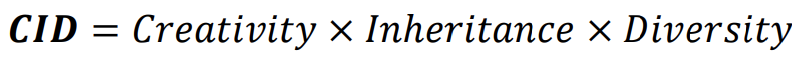
| Notations | |
|---|---|
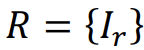 |
실제 Image들의 집합 |
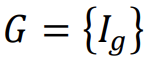 |
GAN으로 생성된 Image들의 집합 |
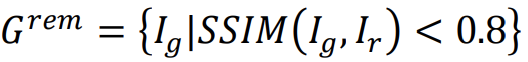 |
G에서 실제 Image와 유사도가 80%보다 낮은 Image들의 집합 |
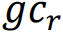 |
GLCM-contrast를 적용한 R의 평균 |
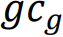 |
GLCM-contrast를 적용한 G^rem의 평균 |
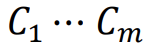 |
유사한 Image들로 구성된 각 Cluster들의 Entropy |
Creativity : 실제 Image와 중복이 있으면 안됨
-
The Creativity measure is to find duplications of real images
-
Creativity에 대한 지표 : 전체 생성된 Image들 중에 실제 Image와 유사한 Image들이 아닌 Image들의 percentage
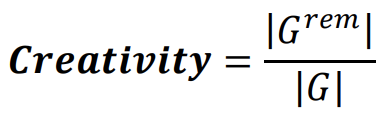
Inheritance : 생성된 Image는 같은 스타일을 가져야 함 (생성된 Image의 분포는 실제 Image의 분포에 가까워야됨)
-
The main idea to measure Inheritance is that same-type images have similar textures
-
Inheritance에 대한 지표 : GLCM-contrast를 적용한 R과 G^rem의 각 평균 차이를 0~1사이 값으로 정규화한 것
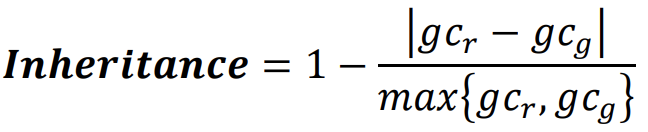
Diversity : 생성된 Image들은 서로 달라야됨
- 유사도를 활용하여 생성된 Image들을 Cluster로 그룹화 시켜 각 Cluster의 entropy를 계산함
- Cluster들이 많고 각 Cluster마다 Image가 적을 경우 생성된 Image가 Diversity하다는 걸 알 수 있음
- 각 Cluster마다 오직 하나의 Image만 있을 경우, 생성된 Image들은 가장 좋은 Diversity지표를 갖게됨
-
Diversity에 대한 지표 :
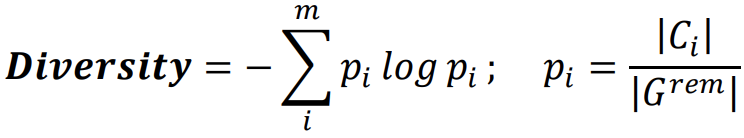
⁉️ GLCM(Gray Level Co-occurrence Matrix)
-
GLCM이란, 통계적 질감 분석방법으로 현 재 픽셀과 그 이웃하는 픽셀의 밝기 값의 관계를 대비(Contrast), 상관관계(Correlation), 에너지(Energy), 동질성(Homogeneity) 등과 같은 질감 특징을 결정하는 통계량으로 계산하여 표현하는 것으로, 밝기를 나타낸 영상에서 정의한 변위벡터의 거리와 방향이 일치하는 픽셀쌍의 빈도 수를 표시하는 빈도 수 매트릭스이다
-
GLCM 구하는 과정 :
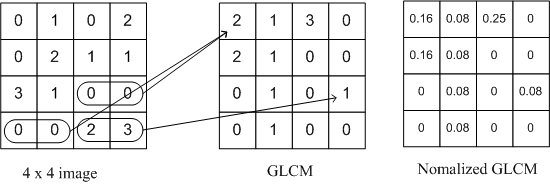
-
예시로 4*4 image에서 각 픽셀 값은 0~3
-
4*4 image에서 가로로 픽셀 2개씩 읽으면 GLCM의 위치 좌표가 됨
 따라서 GLCM 도 4 * 4 Matrix가 나옴
따라서 GLCM 도 4 * 4 Matrix가 나옴 -
대응하는 GLCM의 위치에 +1을 카운트 해주면 됨
-
정규화는 Matrix 픽셀 전체 합이 1이 되도록 만드는 것이므로 각 GLCM의 픽셀값을 GLCM의 합로 나누면 됨
-
2. Inception Score (IS) [Salimans et al. 2016]
- Inception model (Szegedy et al., 2016) : 1,000개의 클래스와 120만개의 이미지로 구성 된 ImageNet g훈련 데이터를 pre-trained한 CNN모형으로 어떤 이미지가 입력되 면 각 1,000개의 클래스에 속할 확률 vector를 출력
Inception Score 계산 공식 :
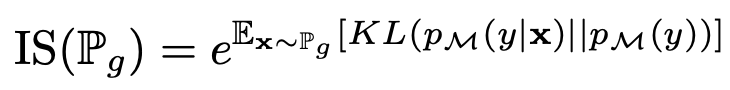
-
Conditional label distibution p(y|x) : 생성된 Image의 품질를 측정하는 부분
-
생성된 Image x를 Inception 모델을 통해 나온 각 label에 대한 확률분포
-
가장 이상적인 Conditional label distibution == 특정 label이 높게 나온 분포
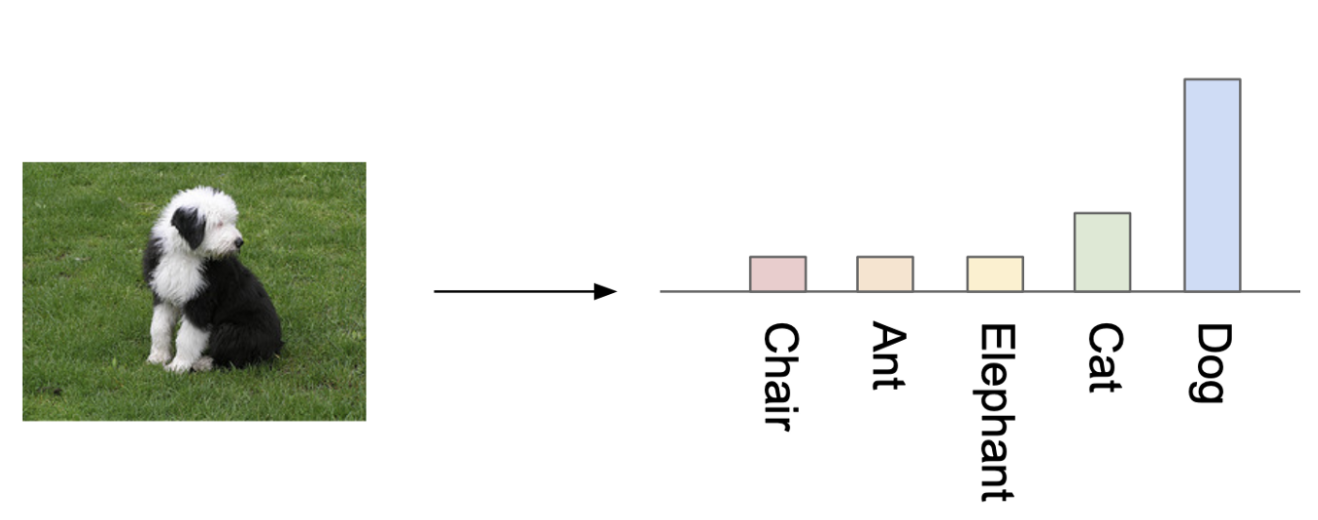
-
-
Marginal distribution p(y) : 생성된 Image의 다양성을 측정하는 부분
-
여러개의 생성된 이미지들을 사용하여 label의 분포를 합산한 새로운 분포
-
가장 이상적인 Marginal distribution == 균등한 분포
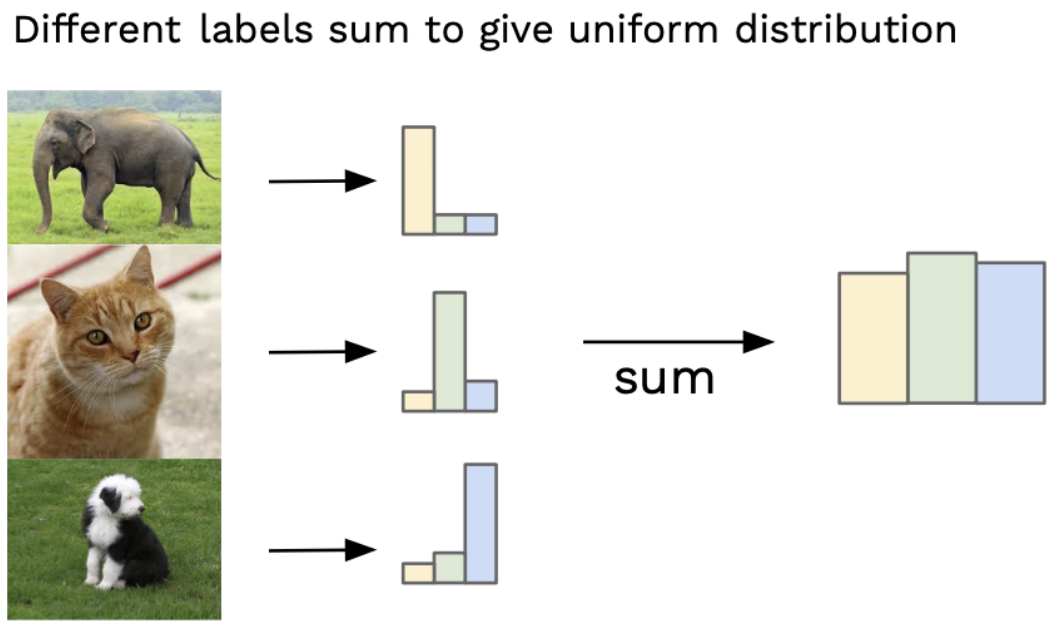
-
-
Kullback-Leibler divergence : p(y|x) 와 p(y)가 얼마나 유사하거나 다른지에 대한 척도
-
즉 특정 label이 높게 나온 Conditional label distibution 과 균등한 Marginal distribution일 때 가장 이상적인 Inception Score를 나타나게 됨
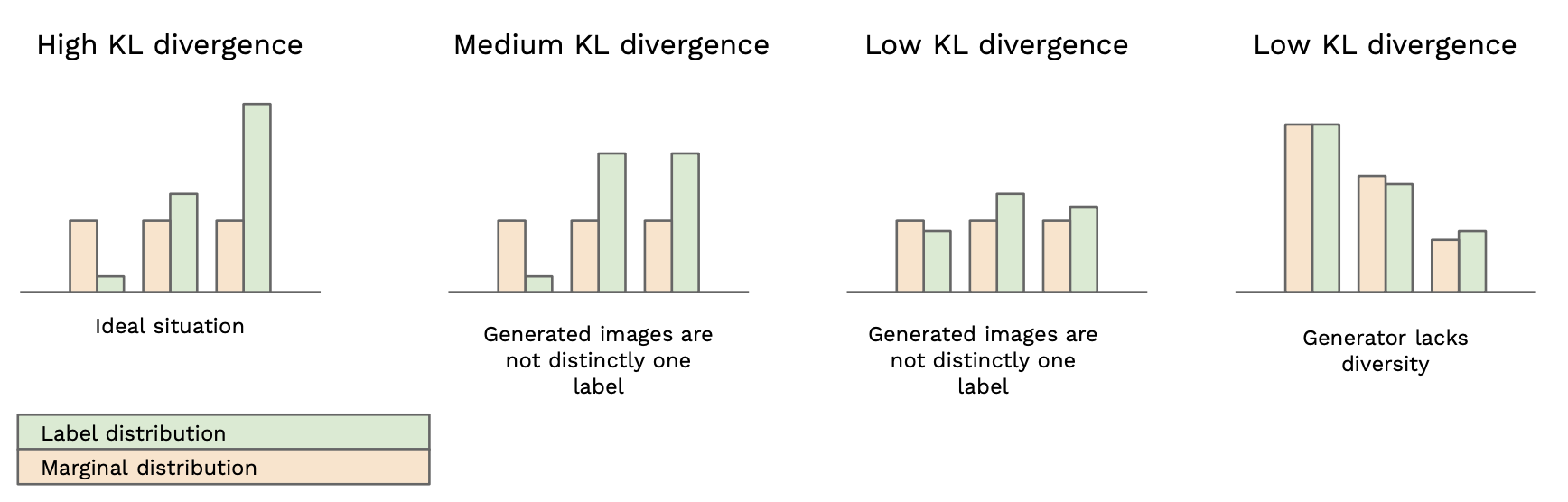
-
결과값 해석
The inception score has
- a lowest value of 1.0
- a highest value of the number of classes supported by the classification model
한계점
[1] Inception Score는 Weight에 민감함
-
Inception Network를 매번 training 하게 되면 training 절차에 어쩔수 없이 내재된 무작위성 때문에 Network내의 weight가 변경 될 수 밖에 없음
-
물론 weight가 여러번 변경되어도 네트워크는 거의 동일한 분류 정확도를 갖을 수 있지만, 약간의 weight 변경으로 인해 동일한 샘플 이미지 세트에 대한 점수가 크게 달라질 수 도 있음
-
Example. (Barratt et al. 2018)
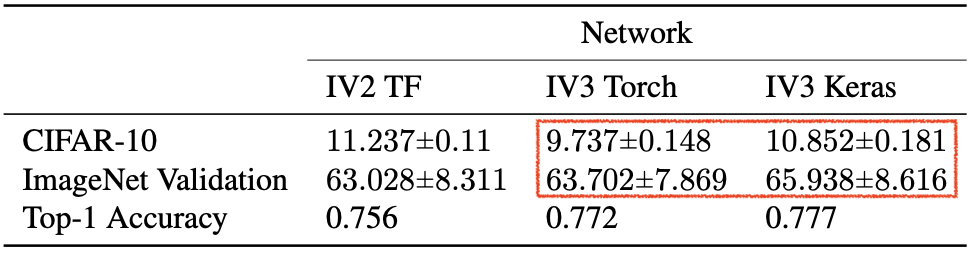
- PyTorch로 구현한 Inception V3 Network으로 계산한 Inception Score과 Keras로 구현한 Inception V3 Network으로 계산한 Inception Score만 (빨간색 구역만) 가지고 비교해보면, CIFAR-10 데이터는 평균 11.5% 가 차이나고 ImageNet validation은 3.5%가 차이가 남
- 하지만 PyTorch로 구현하든 Keras로 구현하든 분류 정확도는 비슷한 걸 볼 수 있음
- TensorFlow로 구현한 Inception V2 Network으로 계산한 Inception Score까지 비교해보면 더 큰 차이가 있다는 것 알 수 있음
[2] ImageNet외 다른 Dataset을 가지고 훈련된 모델한테 Inception Score를 적용할 경우 잘 못된 결과를 도출하게 됨
-
Example. (Barratt et al. 2018)

- ImageNet Dataset는 CIFAR-10 Dataset 보다 class가 더 상세하고 많음
- CIFAR-10에서 Cat class인 이미지를 예로 들면 어떤 이미지가 Inception 모델을 통해 ImageNet에서 더 상세한 고양 종류의 class로 분배되어 원래 특정 label이 높게 나와야 되는 Conditional label distibution이 균등한 분포로 변하게됨
[3] Inception 모델의 훈련 dataset에 없는 무언가를 생성하는 경우
- 예를 들어 Glass Frog의 경우는 Inception 모델의 훈련 dataset에 포함되지 않는다. 만일 Glass Frog의 이미지를 고품질로 생성하더라도 해당 이미지가 특정 Label로 분류가 되지 않기 때문에 항상 낮은 Inception Score를 받을 수 밖에 없음
[4] Generator가 Image의 class 당 하나의 Image만 생성하고 각 Image를 여러번 반복하는 경우
-
이렇게 되면 높은 IS의 조건에 충족하기 때문에 높은 점수를 받음
-
이처럼 Inception Score는 class 내의 다양성을 측정할 수 없음

3. Fréchet Inception Distance (FID) [Heusel et al. 2018]
- FID를 측정할 때 Inception Network를 사용하게 된다는 걸 이름을 통해 알 수 있음
- pretrained된 Inception v3에서 출력 레이어를 제거하고 출력이 마지막 Pooling layer어의 Activation을 사용
- 이 Output layer에는 총 2,048개의 Activation이 있으므로, 각 Image는 2,048개의 특징 vector가 나옴
- Inception Score는 생성된 이미지만 사용하여 성능을 평가하는 반면, FID는 대상 도메인의 실제 이미지 모음 통계와 생성된 이미지 모음 통계를 비교해 평가를 진행함
Fréchet Inception Distance 공식 :
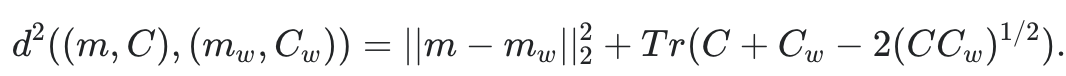
| Notations | |
|---|---|
 |
실제 데이터의 특징 평균 |
 |
실제 데이터의 특징 공분산 행렬 |
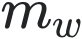 |
생성한 데이터의 특성 평균 |
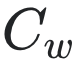 |
생성한 데이터의 공분산 행렬 |
- Inception Network를 통해 추출된 생성한 이미지 사진과 실제 사진의 특성은 Gaussian 분포를 따른다는 전제를 가지고, 이 두 Gaussian 분포 그래프의 거리를 계산 하여 평가하게 됨
결과값 해석
- 점수가 낮을수록 GAN의 성능이 좋다는 의미
- 실제 이미지와 생성한 이미지의 분포가 정확하게 일치할 경우(FID가 0일 경우) 가장 이상적인 모델이라고 판단할 수 있음
- 평균적으로 FID가 10 내외이면 좋은 모델이라고 판단할 수 있음
한계점
-
FID는 특정 생성 기법이 적용된 이미지에만 의미가 있는 평가지표다
Example. (Heusel et al. 2018)
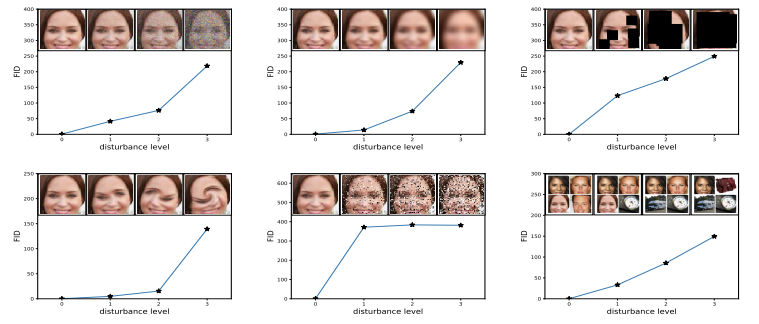
- 가장 왼쪽 위의 그래프를 통해 noise가 들어간 이미지 데이터에 대해서 민감하다는 걸 알 수 있고 가장 오른쪽 위의 그래프를 통해 가려진 이미지 데이터에 대해 더 민감하다는 걸 알 수 있음
- 하지만 가장 왼쪽 아래 그래프를 보면 소용돌이가 들어간 이미지 데이터에 대해선 FID가 낮게 올라 가는 걸 볼 수 있음
- 사람 육안으로 봤을 때 noise가 조금 들어간 것보다 소용돌이가 조금 들어간 이미지가 더 이상하다는 걸 감지할 수 있지만 FID를 사용할 경우 그렇지 않다는 걸 알 수 있음
- 중간 아래의 그래프에도 보면 salt and pepper가 조금 들어간 이미지 데이터에 대해 급격히 올라가다가 salt and pepper가 더 추가가 되어도 큰 변화가 없는 걸 보면 FID는 특정 생성 기법이 적용된 이미지에만 의미가 있는 평가 지표라는 것을 알 수 있음
4. 1-Nearest Neighbor classifier (1NNC)
- Inception Score와 FID처럼 Inception Model을 사용하지

- 대신 1-Nearest Neighbor 방법을 활용하여 LOO accuracy를 계산함
- 사실 1-Nearest Neighbor 뿐 만아니라 3,5,7-Nearest Neighbor으로도 다 가능하지만, 1-Nearest Neighbor으로 하게 될 경우 거리 계산량도 적고 설정해야되는 hyperparameter도 없어서 가장 효율적으로 GAN 모델을 평가 할 수 있음
1NNC의 LOO accuracy 계산
-
실제 Image와 생성된 Image의 수량이 동일해야됨
-
label이 “1”인 생성된 Image과 label이 “0”인 실제 Image로 훈련된 1-NN classifier의 Leave- One-Out (LOO) accuracy를 계산함
-
생성된 Image와 실제 Image가 각 n개씩 있다면 총 2n개 중에
-
2n-1개는 우선 1-NN classifier를 훈련시키는데 사용됨
-
나머지 1개는 1-NN classifier를 Test할 Test data로 사용됨
-
위 같은 과정이 이제 2n번 일어남 (대신 Test data 선택시 재사용 안됨 )
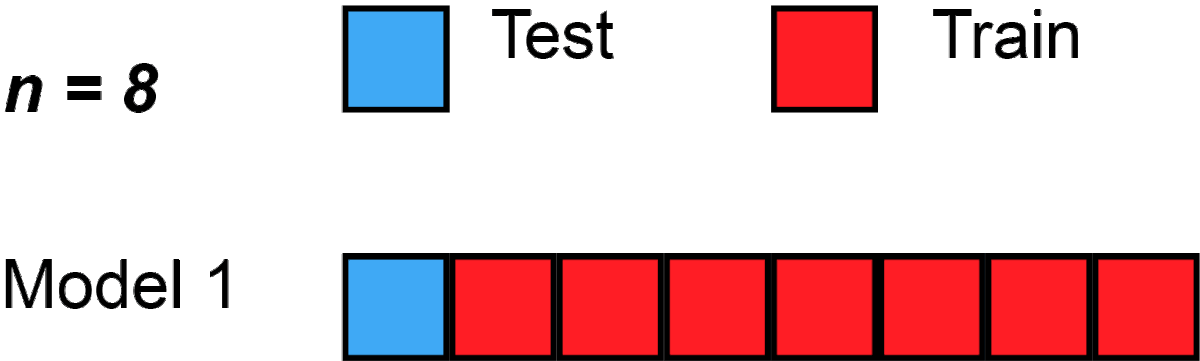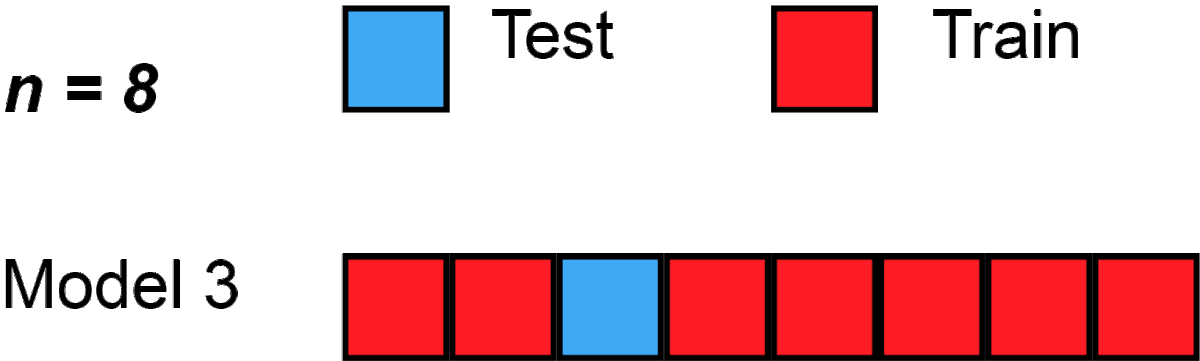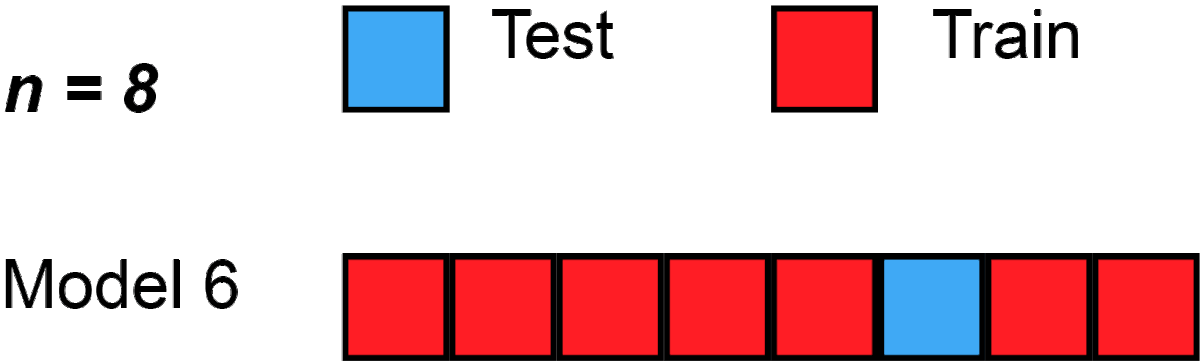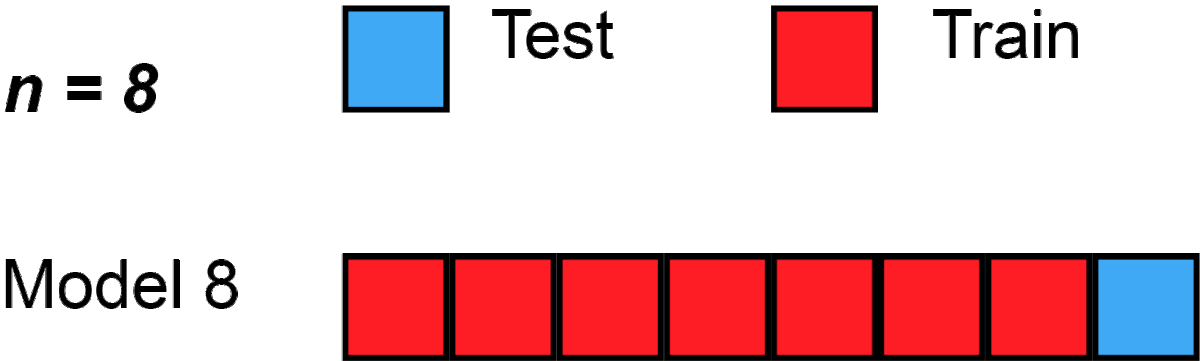
-
최종적으로 2n개 accuracy를 가지고 1-NN classifier의 accuracy를 계산
-
결과값 해석
-
LOO accuracy ≈ 0.5 : 가장 이상적인 경우
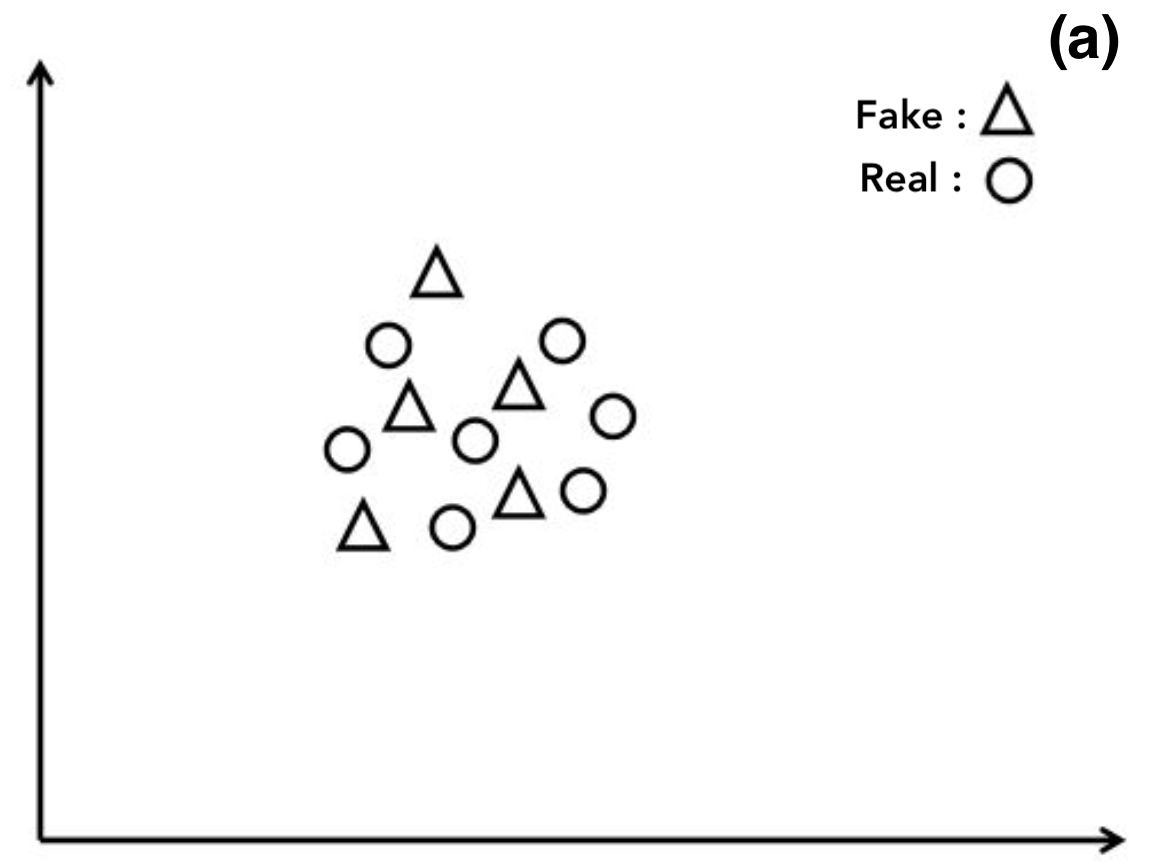
-
LOO accuracy < 0.5 : GAN이 실제 Image들에 Overfitting 됬다는 의미
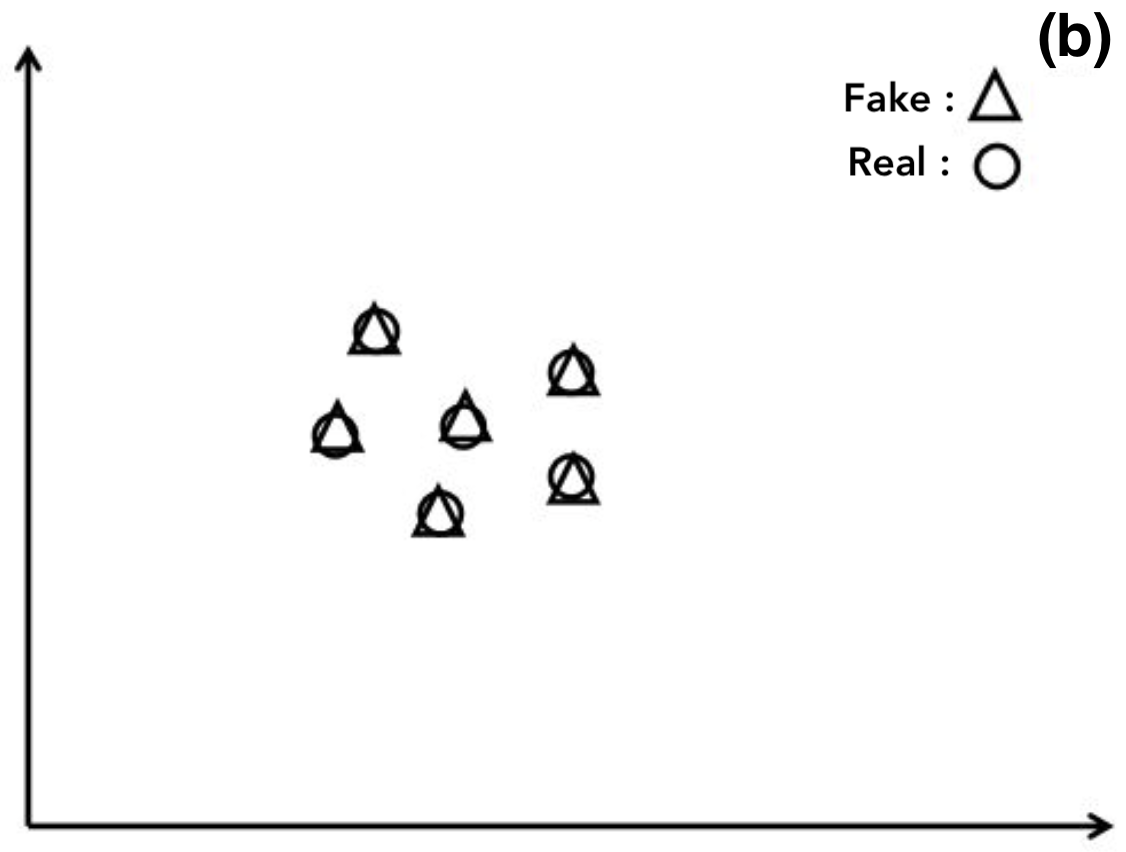
- LOO accuracy == 0 : GAN이 실제 Image들을 모두 기억하고 동일하게 Image를 생성했다는 의미
-
LOO accuracy > 0.5 : GAN이 실제 Image들의 특성 분포를 잘 지니지 못한 Image를 생성했다는 의미
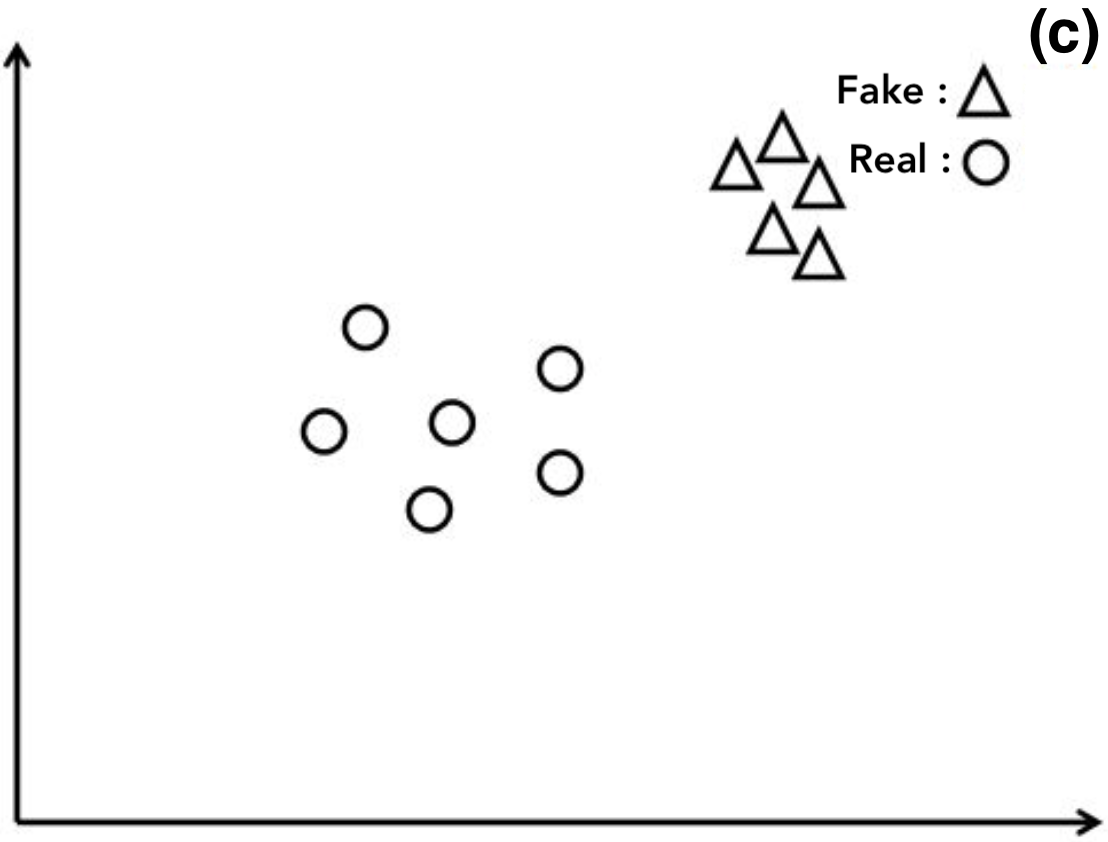
-
1NNC accuracy를 통해 GAN 모델에 Mode Collapsing 현상 존재여부도 파악가능
Example. (Huang et al. 2018)
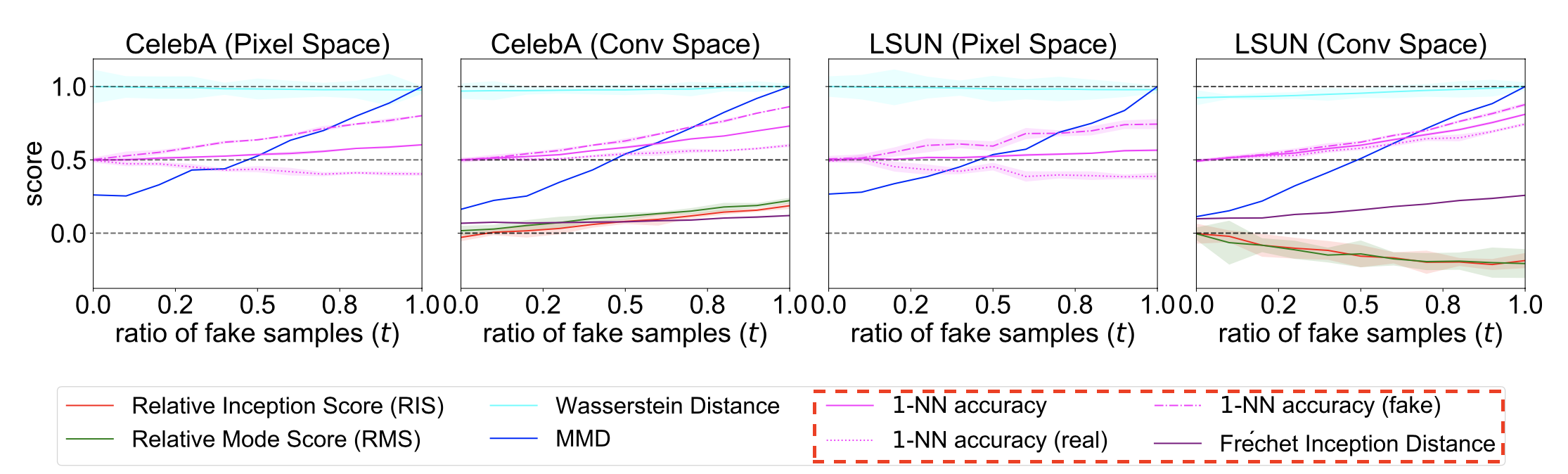
- 1-NN accuracy (Fake) : 생성된 Image가 test case가 되서 측정된 accuracy
- 1-NN accuracy(Real) : 실제 Image가 test case가 되서 측정된 accuracy
- 1-NN accuracy(Fake)의 곡선은 점점 올라가는 반면에 1-NN accuracy(Real)의 곡선이 하향하는 경우 현재 GAN 모델에 Mode Collapsing현상이 존재한다는 걸 알 수 있음
한계점
- The local conditions of distributions will greatly affect the 1-NN classifier
《Reference》